2. Bonnes pratiques en informatique scientifique#
Marc BUFFAT , Université Claude Bernard Lyon 1

(C) graphique issu du site xkcd
2.1. Workflow du calcul scientifique#
Le workflow du calcul scientifique le plus courant est constitué de scripts qui appellent des données, des programmes et d’autres entrées et produisent des sorties pouvant inclure des visualisations et des résultats analytiques. Ces scripts peuvent être implémentés dans des programmes tels que R ou MATLAB, et maintenant de plus en plus Python avec une interface en ligne de commande, ou plus récemment en utilisant des applications Web telles que les Notebooks Jupyter.
Le développement est généralement basé sur une construction itérative, avec une validation à chaque étape, privilégiant l’assemblage de solutions simples pour résoudre des problèmes complexes : small is beautiful
L’approche utilise la méthode REPL suivante: Read-Eval-Print Loop
Définition d’une solution algorithmique
Écriture du code
Exécution avec analyse (print) et validation
Si besoin corriger et Répéter
2.1.1. règles de programmation#
définir les données et les résultats à obtenir
chercher une solution algorithmique
écrire du code python de haute qualité (Writing high-quality Python code)
commentaire (docstring)
privilégier la simplicité
compréhensible
tester pour valider
connaître les variables et fonctions du problème
2.1.2. Zen du python#
# zen du python
import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
2.2. Bonnes pratiques#
Connaitre son environement de travail
Apprendre les bases du shell Unix (interpréteur de ligne de commandes)
Bien connaître le langage Python 3
Ecrire du code Python lissible, claire et de qualité
Vérifier et valider vos proagrammes
Et surtout faites preuve de rigueur
2.3. Connaitre son environnement informatique#
Pour connaître le système d’exploitation (opérating system OS ) utilisé, le système de fichiers …, on utilise des commandes du shell (bash sous Unix) en utilisant dans une cellule le mot clé %%bash ou en utilisant le ! avant la commande : ! commande
2.3.1. commandes du shell (interpréteur de commandes)#
pour avoir une dopcumentation en ligne d’une commande, p.e. whoami
man whoami
%%bash
# nom utilisateur
whoami
buffat
%%bash
# système OS
uname -a
Linux p2chpd-visu2 5.15.0-173-generic #183-Ubuntu SMP Fri Mar 6 13:29:34 UTC 2026 x86_64 x86_64 x86_
64 GNU/Linux
# processeur
!head -5 /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 94
model name : Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz
# memoire
!head -5 /proc/meminfo
MemTotal: 32789832 kB
MemFree: 18830172 kB
MemAvailable: 29225740 kB
Buffers: 456912 kB
Cached: 8917140 kB
2.3.2. système de fichiers, répertoire#
# liste de tout les disques du système
!df
Sys. de fichiers blocs de 1K Utilisé Disponible Uti% Monté sur
tmpfs 3278984 2072 3276912 1% /run
/dev/sdb1 60159876 36090584 20980908 64% /
tmpfs 16394916 0 16394916 0% /dev/shm
tmpfs 5120 4 5116 1% /run/lock
tmpfs 16394916 0 16394916 0% /run/qemu
/dev/sda1 240116872 195727496 32166004 86% /data
/dev/sdb2 81209800 63721088 13317552 83% /home
/dev/sdc1 960310988 124735692 786720872 14% /home/sauvegarde
/dev/sdb5 76712256 54880148 17925908 76% /opt
lovelace.univ-lyon1.fr:/si/softs 78132553728 8456722432 69675831296 11% /softs
lovelace.univ-lyon1.fr:/nbgrader/data 78132553728 8456723200 69675830528 11% /data2
/dev/sdd1 15149072 482896 14666176 4% /media/buffat/DRH - SD
tmpfs 3278980 1696 3277284 1% /run/user/1000
%%bash
# affiche le répertoire courant
pwd
/data/cours/MGC2028L/cours
# caractéristique d'un fichier
!ls -al Lissajous.py
!file Lissajous.py
-rw-rw-r-- 1 buffat buffat 758 oct. 25 2024 Lissajous.py
Lissajous.py: Python script, Unicode text, UTF-8 text executable
2.3.3. quelques commandes classiques#
copy cp
déplace mv
efface rm
création répertoire mkdir
parcourir cd
affiche fichier cat , head , tail
recherche chaine dans un fichier grep
shell script: automatisation
2.4. Recherche d’erreurs (debugging)#
Note
Everyone knows that debugging is twice as hard as writing a program in the first place. So if you’re as clever as you can be when you write it, how will you ever debug it? Don’t comment bad code—rewrite it.
Brian Kernighan (auteur du livre C programming language)
les erreurs sont inévitables : nous écrivons donc tous du code avec des erreurs
apprenez donc à vérifier et tester systématiquement votre code
Keep It Simple, Stupid (KISS) : gardez-le simple, stupide
commentez et explicitez votre code
vérifiez simplement avec la fonction
printaprès ces étapes de base, si vous ne trouvez pas l’erreur, on peut utiliser un débugueur, qui est un outil permettant d’exécuter le code et d’afficher la valeur des variables
2.4.1. Utilisation d’un IDE (type spyder)#
Un IDE (environnement logiciel de développement) est un outil extrêmement puissant utilisé par les développeurs pour l’écriture de codes complexes.
Pour des codes simples, il est sans doute trop puissant, et l’on préférera utiliser un outil plus simple, mème si moins sophistiqué.
2.4.2. Débugueur intégré#
les dernières versions de jupyterlab intègre un débugueur intégré offrant des possibilités intéressantes.
Pour activer le débugueur, ouvrir une notebook IPython ou un programme python dans JupyterLab, puis cliquer sur l’icône bug dans le coin supérieur droit:

Une fois le débugueur activé, on active la fenêtre de debug à droite en cliquant sur l’icône bug dans la colonne de droite, qui fait apparaître différents panneaux

panneau Breakpoints
Mettre des points d’arrêts (breakpoint) dans le code python, ce qui permet de stopper le programme en cours d’exécution. Pour cela, déplace le curseur juste avant le numéro de ligne (un point rouge apparait). Pour mettre un point d’arrêt, il suffit alors de cliquer et le point rouge reste alors fixe
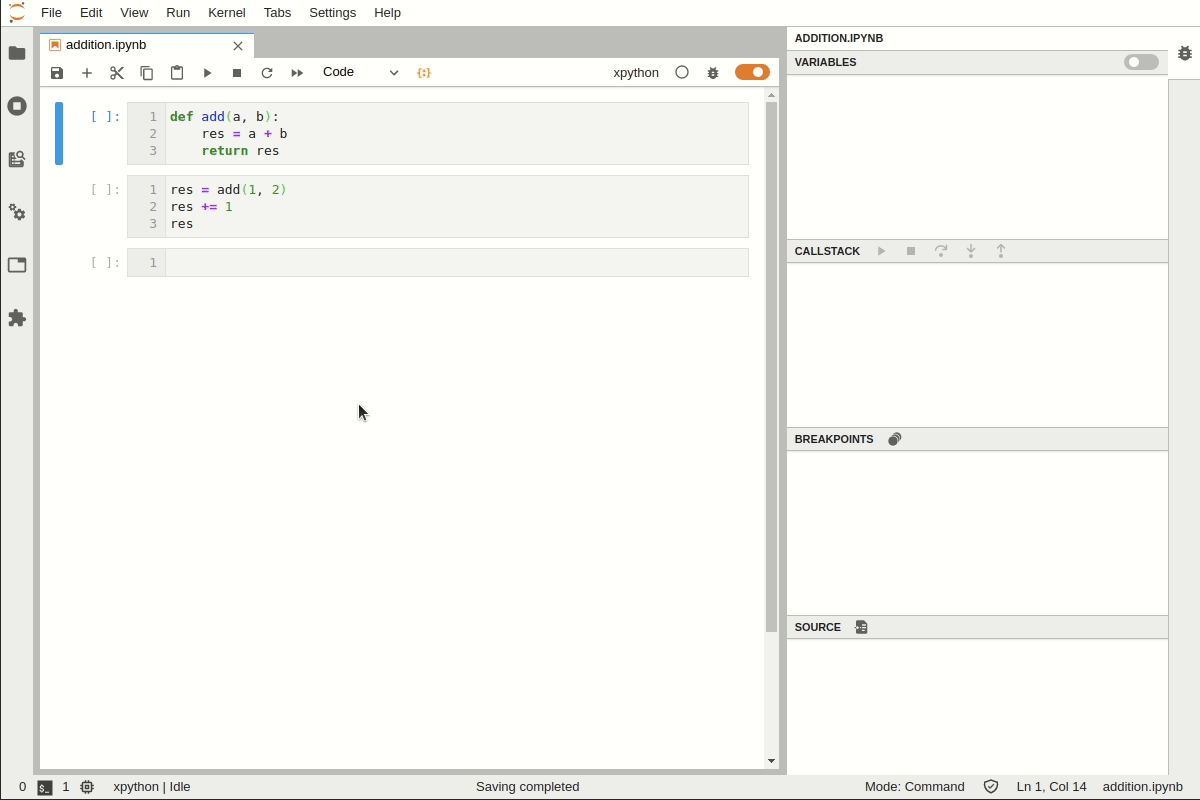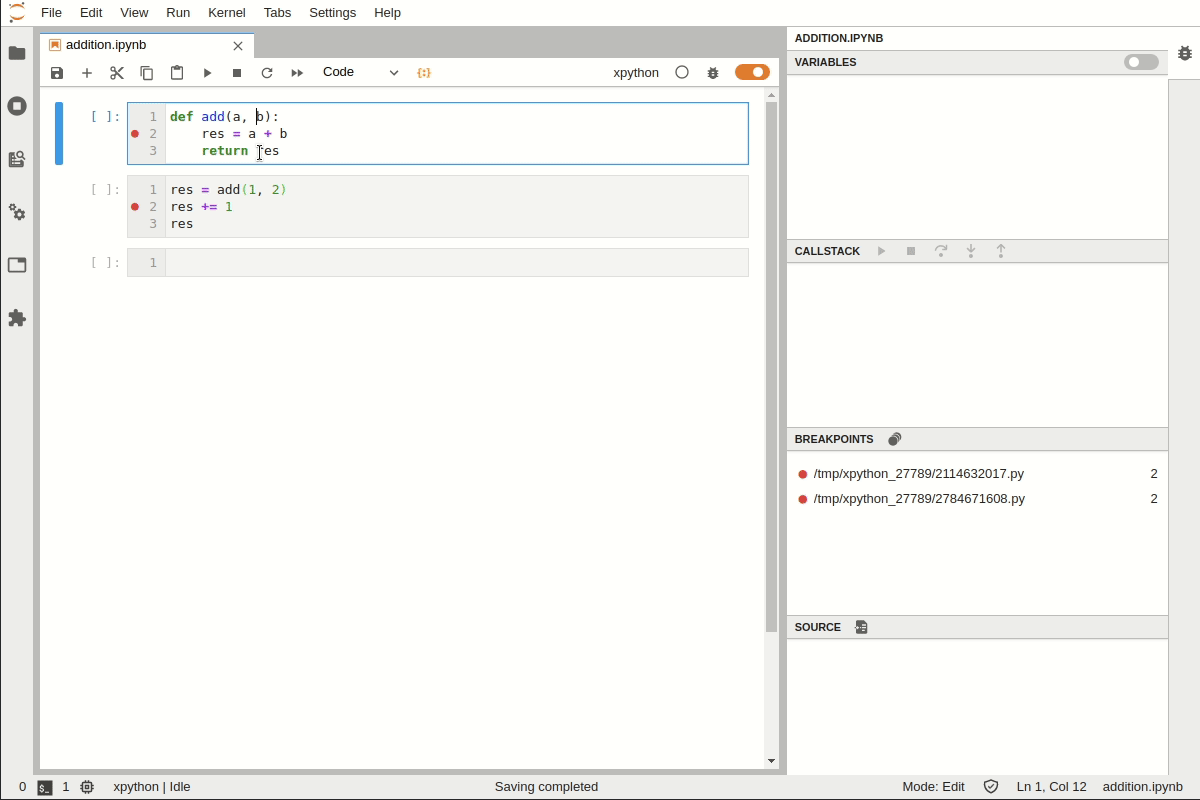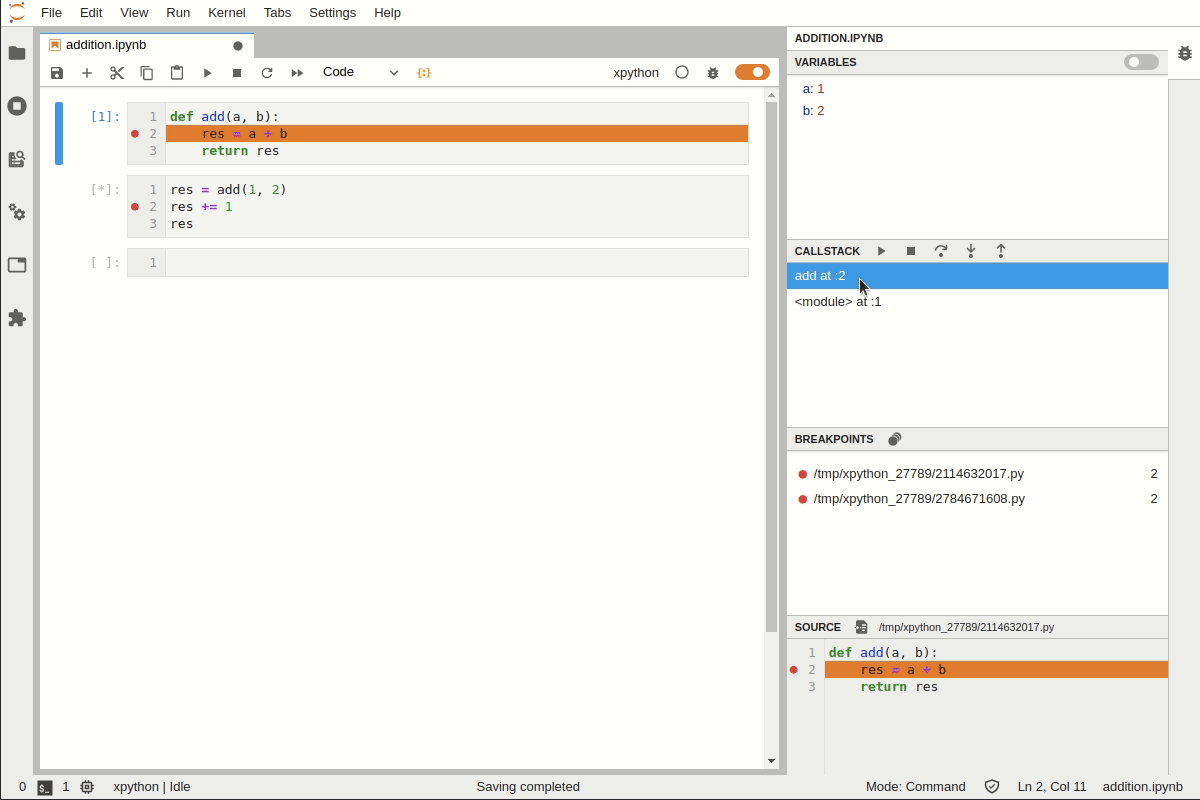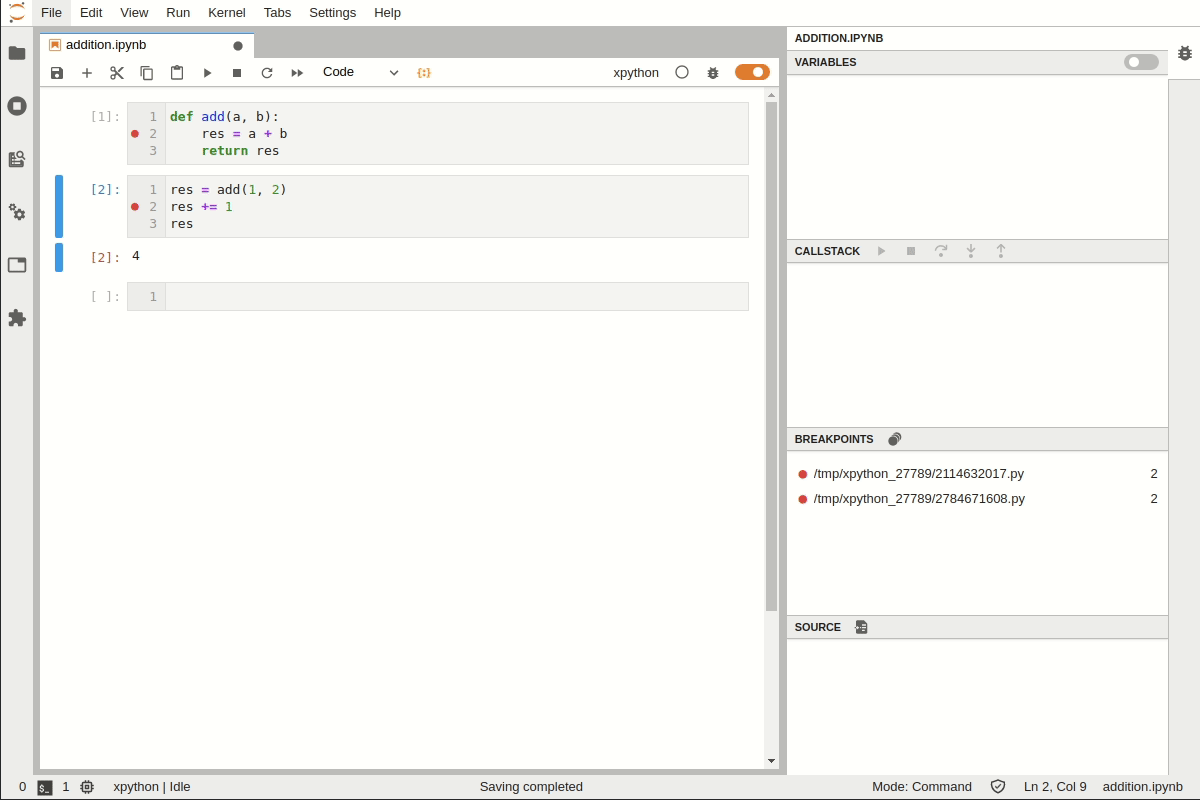
panneau Call Stack
Vous pouvez entrer dans le code et poursuivre l’exécution à l’aide des actions de débogage : exécuter le programme pas à pas
panneau Variables
Permet d’afficher la liste et les valeurs des variables du code. Les variables peuvent être explorées à l’aide d’une vue arborescente et d’une vue tableau :
panneau Source
Le panneau source affiche la source du fichier en cours de débogage
Important
Voici un screencast pour activer le débogueur et configurer des points d’arrêt extrait de la documentation jupyterlab
2.5. Exemple: courbe de Lissajous#
Une courbe de Lissajous (d’après le physicien français « Jules Antoine Lissajous ») est une courbe paramétrique du plan dont les composantes sont des fonctions périodiques du paramètre (en générale le temps en physique, et que l’on peut observer avec un oscilloscope).
Le programme Python suivant lissajous.py trace les courbes de Lissajous suivantes
Le rapport \(n=\frac{p}{q}\) est le paramètre de la courbe et \(\phi\) le déphassage. Le temps \(T\) de parcours de la courbe est le plus petit commun multiple de \(p\) et \(q\): $\(T=pcm(p,q)=\frac{pq}{pgcd(p,q)}\)$
2.5.1. Méthodologie#
Propriétés de l’algorithme PGCD à écrire
calcul PGCD(a,b)
propriétés :
PGCD(a,a) = a
si a >b PGCD(a,b)=PGCD(a-b,b)
sinon PGCD(a,b)=PGCD(a,b-a)
Programme Python
traduction algorithme sous python
Validation
définition des cas de validation
PGCD(125,125)=125
PGCD(9,21)=3
2.5.2. Solution algorithmique#
Algorithme PGCD(a,b)
tant que a#b
si a>b alors a=b-a
sinon b = b-a
retour a
# programme
def PGCD(a,b):
"""calcul du pgcd de a et b par l'algorithme d'Euclide."""
while a!=b:
if a>b:
a = a -b
else:
b = b -a
return a
# validation
assert(PGCD(123,123)==123)
assert(PGCD(9,21)==3)
assert(PGCD(28,16)==4)
# variante (optimise)
def pgcd(a, b):
"""calcul du pgcd de a et b par l'algorithme d'Euclide."""
print(a,b)
while b:
a, b = b, a % b
print(a,b)
return a
pgcd(30,21)
30 21
21 9
9 3
3 0
3
assert(pgcd(123,123)==123)
assert(pgcd(9,21)==3)
assert(pgcd(28,16)==4)
123 123
123 0
9 21
21 9
9 3
3 0
28 16
16 12
12 4
4 0
2.5.3. Courbe de lissajous#
Algorithme Lissajous(p,q,phi,N)
periode commune T = ppcm(p,q)
T = pq/pgcd(p,q)
t = [0,T/(N-1),...,T]
x = sin(2*pi/p*t)
y = sin(2*pi/q*t + phi)
retour t,x,y
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
def Lissajous(p,q,phi,N):
""" calcul de N points d'une courbe de Lissajous"""
omega1 = 2*np.pi/p
omega2 = 2*np.pi/q
# temps d'étude
T = p*q/pgcd(p,q)
t = np.linspace(0., T, N)
# equations parametriques
x = np.sin(omega1*t)
y = np.sin(omega2*t+phi)
return t,x,y
# validation
t,x,y = Lissajous(2,2,0.,100)
assert(np.all(np.abs(x-y)<1.e-8))
2 2
2 0
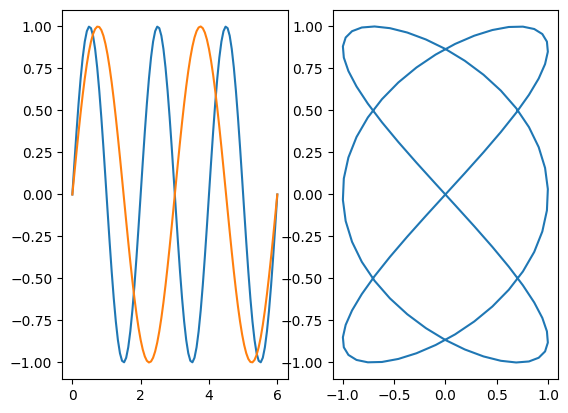
# application
t,x,y = Lissajous(2,3,0.,100)
plt.subplot(1,2,1)
plt.plot(t,x)
plt.plot(t,y)
plt.subplot(1,2,2)
plt.plot(x,y)
2 3
3 2
2 1
1 0
[<matplotlib.lines.Line2D at 0x7f1a041ec0a0>]
2.5.4. Mise sur fichier (pour réutilisation comme module)#
crétaion du fichier Lissajous.py
importation du module
mot clé import
!cat Lissajous.py
#! /usr/bin/env python3
import numpy as np
def PGCD(a,b):
"""calcul du pgcd de a et b par l'algorithme d'Euclide."""
while a!=b:
if a>b:
a = a -b
else:
b = b -a
return a
def Lissajous(p,q,phi,N):
""" calcul de N points d'une courbe de Lissajous"""
omega1 = 2*np.pi/p
omega2 = 2*np.pi/q
# temps d'étude
T = p*q/PGCD(p,q)
t = np.linspace(0., T, N)
# equations parametriques
x = np.sin(omega1*t)
y = np.sin(omega2*t+phi)
return t,x,y
# test de validation
if __name__ == "__main__":
assert(PGCD(123,123)==123)
assert(PGCD(9,21)==3)
assert(PGCD(28,16)==4)
t,x,y = Lissajous(2,2,0.,100)
assert(np.all(np.abs(x-y)<1.e-8))
print("Validation OK")
%%bash
python3 Lissajous.py
Validation OK
import Lissajous as li
t,x,y = li.Lissajous(2,3,0.,100)
plt.subplot(1,2,1)
plt.plot(t,x)
plt.plot(t,y)
plt.subplot(1,2,2)
plt.plot(x,y)
[<matplotlib.lines.Line2D at 0x7f1a02123730>]