8. Mise en oeuvre du machine learning#
Marc BUFFAT , dpt mécanique, Université Lyon 1

(1) inspiré du cours « formation Deep Learning » de méteo-france
8.1. Hyper-paramètres#
paramètres d’un modèle de Machine Learning ?
― type et complexité du modèle
La régression linéaire est un modèle simple, mais on peut le complexifier: polynôme de degré n, random forest, réseaux de neurones…
― paramètres spécifiques du modèle
Pour un réseau de neurones : nombre de couches et nombre de neurones par couche…
Le learning rate (paramêtre de descente)
La taille des mini-batches
Epochs (nbre d’itérations sur le modèle)
8.2. Evaluation du modèle#
\(\Rightarrow\) nécéssité de scinder la base de données en 3:
entraîner sur le jeu d’entraînement,
choisir les hyper-paramètres qui fonctionnent le mieux sur un jeu de validation
tester le modèle sur un jeu de test.

8.3. Problèmes#
8.3.1. Sous-apprentissage - Sur-apprentissage#
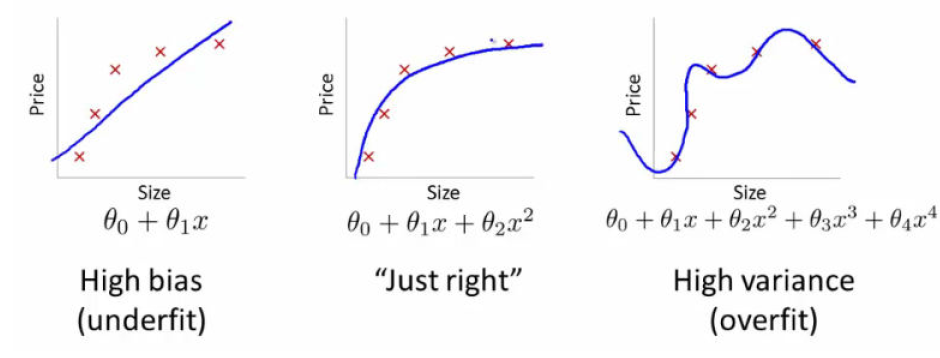
Sous-apprentissage |
Bon modèle |
Sur-apprentissage |
|---|---|---|
modèle trop simple pour expliquer la variance |
modèle qui colle trop au bruit du jeu de données |
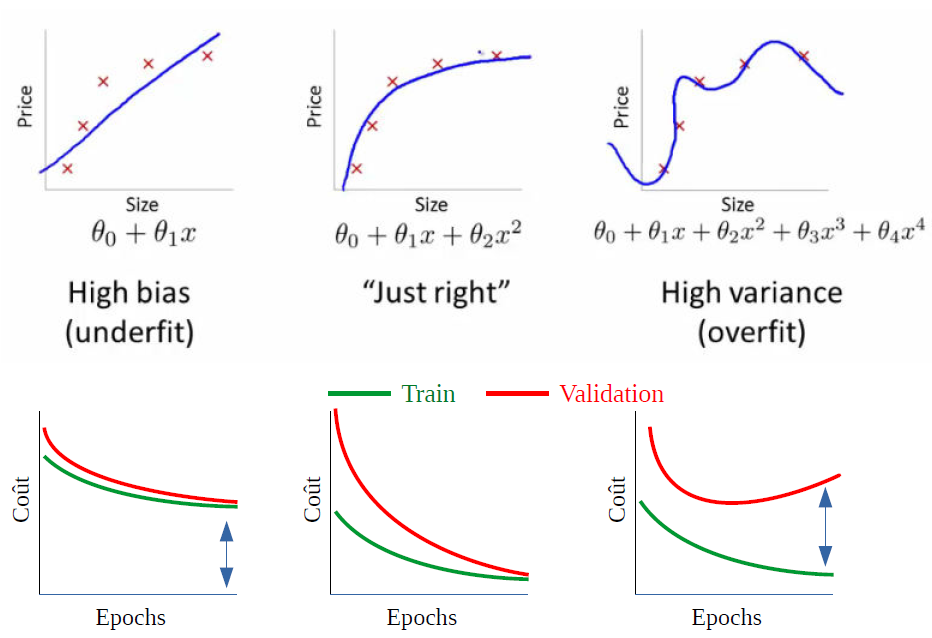
8.3.2. Sous-apprentissage - Sur-apprentissage#
8.3.3. Combattre l’underfitting#
― Complexifier le modèle
Ex : modèle quadratique au lieu d’un modèle linéaire
― Ajouter des prédicteurs, i.e. d’autres paramètres
8.3.4. Combattre l’overfitting#
― Ajouter des données d’ entraînement
― Simplifier le modèle ou retirer des prédicteurs
Eviter que le modèle parvienne à « apprendre par coeur » le jeu d’ entraînement
― Entraîner le modèle moins longtemps
En français, l’overfitting se dit « sur-apprentissage ».
Eviter au modèle de sur-apprendre.
― Limiter la capacité d’apprentissage du modèle
Il existe plusieurs méthodes dont la régularisation et le dropout.
― Utiliser des ensembles
C’est comme en météo. Entraîner plusieurs modèles et combiner leurs prédictions.
8.4. Outils de l’IA#
bibliothèques de base disponibles sous Python
numpy, scipy : calcul numérique
pandas : gestion de base de données
seaborn: statistical data visualization
8.4.1. scikit-learn: Machine Learning in Python (open source)#
outils simples et efficaces pour l’analyse prédictive des données
construit sur NumPy, SciPy et matplotlib
8.4.2. tensor-flow: (open source)#
outils d’apprentissage automatique développé par Google
utilisation de keras API de haut niveaux de tensor-flow
8.4.3. optimisation (utilisation GPU / calcul parallele MPI)#
version de tensor-flow pour GP/GPU
XGBoost: optimized distributed gradient boosting library (parallel tree boosting on distributed env.)
8.5. Algorithmes d’IA#
algorithme implicite (résultat dépend des donnnées) !
algorithme de régression de type random forest
très efficace sur des bases de données moyenne
mais problème de mise à l’échelle
algorithme de type réseaux de neurones
moins précis et beaucoup plus lourd (sensible aux paramètres, adimensionnalisation )
mais passage à l’échelle pour des BD Big Data (Google)
8.6. Conclusion#
Importance de la connaissance du problème
choix et pertinence des données (dataset)
corrélation plausible
organisation des données
training: jeux d’entraînement
validation: jeux de validation (optimisation des paramètres)
test: jeux de test
choix des algorithmes
analyse des résultats
La génération du modèle représente un compromis entre précision et effort. Un modèle analytique personnalisé offrira très probablement une plus grande précision, tandis qu’un modèle de machine learning de type NN bien entraîné peut fournir une précision acceptable pour un coût moindre mais avec une certaine incertitude sur l’initialisation aléatoire
Groensfelder, T., Giebeler, F., Geupel, M. et al. Application of machine learning procedures for mechanical system modelling: capabilities and caveats to prediction-accuracy. Adv. Model. and Simul. in Eng. Sci. 7, 26 (2020). https://doi.org/10.1186/s40323-020-00163-4
8.7. FIN#
Questions ?