4. Introduction à l’IA (machine learning)#
Marc Buffat dpt mécanique, université Lyon 1

(**) inspiré de « L’intelligence artificielle: introduction et applications en physique » par Colin Bernet et du cours « formation Deep Learning » de méteo-france
4.1. Cours d’IA#
L’intelligence artificielle est sûrement un des grands enjeux de la science moderne. Elle désigne les théories et modèles qui permettent de concevoir des machines capables de simuler l’intelligence humaine de façon autonome. On distingue couramment au sein du concept d’intelligence artificielle, le deep learning (apprentissage profond) et le machine learning (apprentissage automatique) : tandis que le machine learning regroupe des systèmes qui apprennent sur la base de grands ensembles de données, le deep learning se compose de systèmes apprenant via des réseaux de neurones composés d’algorithmes pouvant fonctionner sans données structurées et de façon totalement autonome sans intervention humaine.
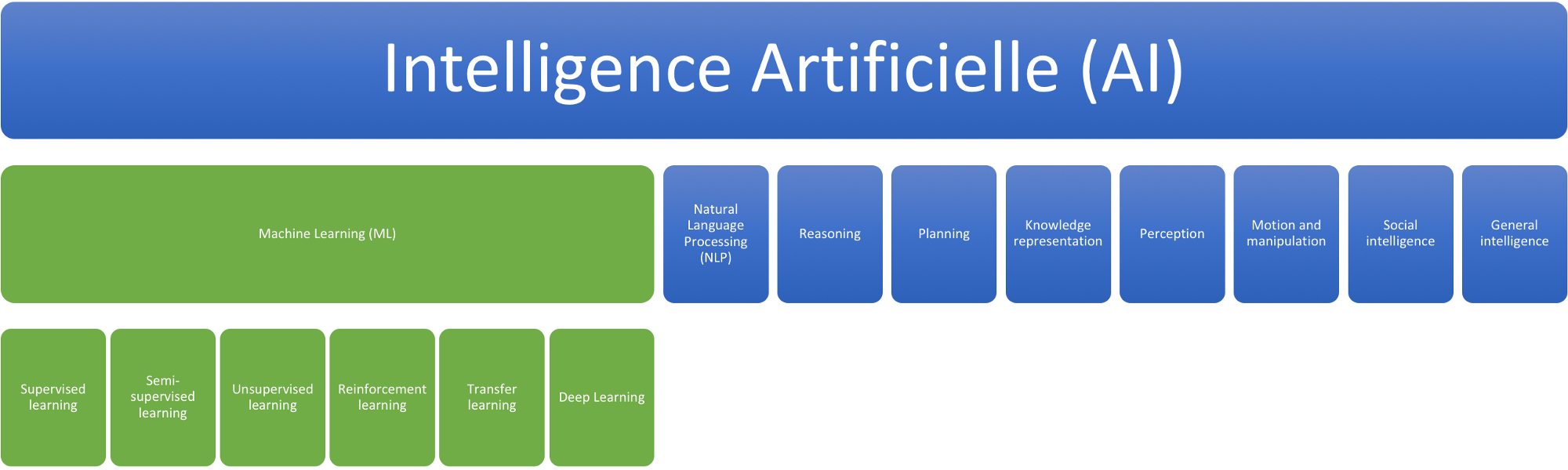
Aujourd’hui l’intelligence artificielle est présente dans presque tous les domaines de la vie courante, de notre smartphone jusqu’a notre voiture et cette technologie intéresse un nombre croissant d’entreprises comme Amazon ou encore Google ou Facebook
4.1.1. Tentative de définition de L’INTELLIGENCE ARTIFICIELLE#
Définition de l’IA :
«L’art de créer des machines ayant des capacités exigeant de l’intelligence quand elles sont réalisées par des humains.» (Kurzweil, 1990)
Paradoxe de Moravec :
Les tâches les plus faciles en IA (Robotique) sont celles qui sont les plus difficiles pour l’homme, et inversement.
4.1.2. Historique: les quatre âges des machines prédictives [1]#
Machine |
Monde |
Calculateur |
Horizon |
|---|---|---|---|
Cybernétique (connexionniste) |
Environnement |
« Boîte noire » |
Negative feedback |
IA Symbolique (symbolique) |
Monde « jouet » |
Raisonnement logique |
Résolution de problème |
Système expert (symbolique) |
Monde de connaissances expertes |
Sélection des hypothèses |
Exemples/ contre-exemples |
Deep Learning (connexionniste) |
Le monde comme vecteur de données massives |
Réseau de neurones profond |
Optimisation de l’erreur sur objectif |
[1] Dominique Cardon, Jean-Philippe Cointet et Antoine Mazières, «La revanche des neurones. L’invention des machines inductives et la controverse de l’intelligence artificielle», Réseaux 2018/5
4.1.3. Question ?#
Will Wilson : nov. 2017
What’s the difference bewteen AI and ML ?
It’s AI when you’re raising money,
it’s ML when you’re trying to hire people.
4.2. Type d’appentissage en IA#
apprentissage supervisée (le plus utilisée)
mais nécessite une énorme base de données d’apprentissage
apprentissage par renforcement (jeu d’échec, go ..)
apprentissage auto-supervisé:
représentation plus simple de la base de données (plus générique)
apprentissage sur la base de données de représentation (réduction)
application : langage naturel, traduction, imagerie
Méthode scientifique : France Culture apprentissage auto-supervisé
4.3. Exemples classiques#
4.3.1. IA de reconnaissance d’écriture manuscrite#
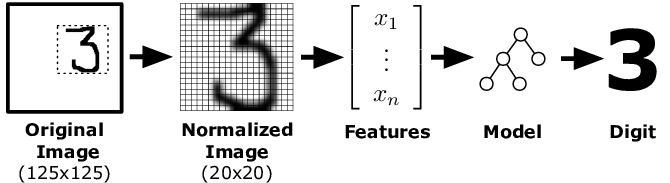
détecteur de visage / reconnaissance faciale
détecteur de SPAM / réseaux sociaux
4.4. Applications de l’IA en mécanique#
4.4.1. Machine Learning#
traitement de données
données structurées
apprentissage
4.4.2. Deep Learning#
utilisation de réseaux de neurones
Big Data
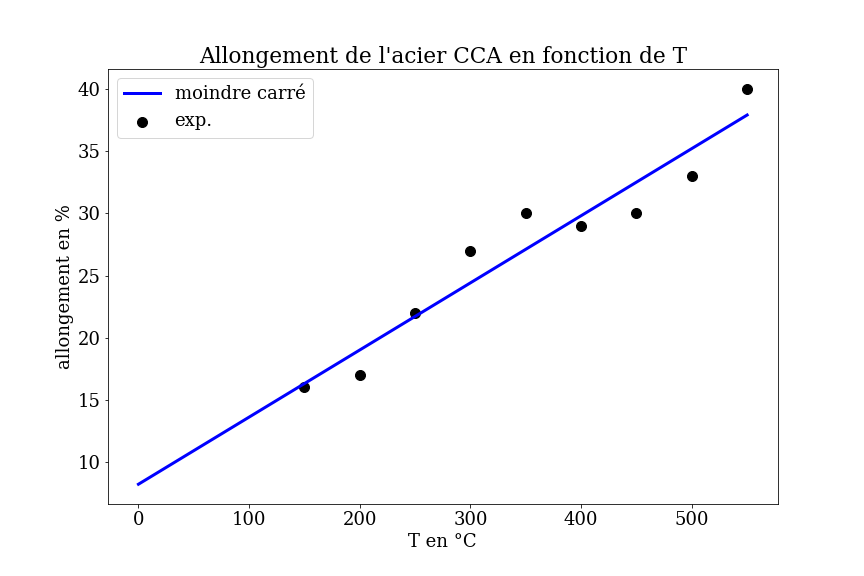
4.4.3. Prédiction des propriétés mécaniques des aciers#
A partir d’une base de mesures expérimentales pour différents alliages d’acier, prédiction de l’allongement du matériau en fonction de sa composition et de la température
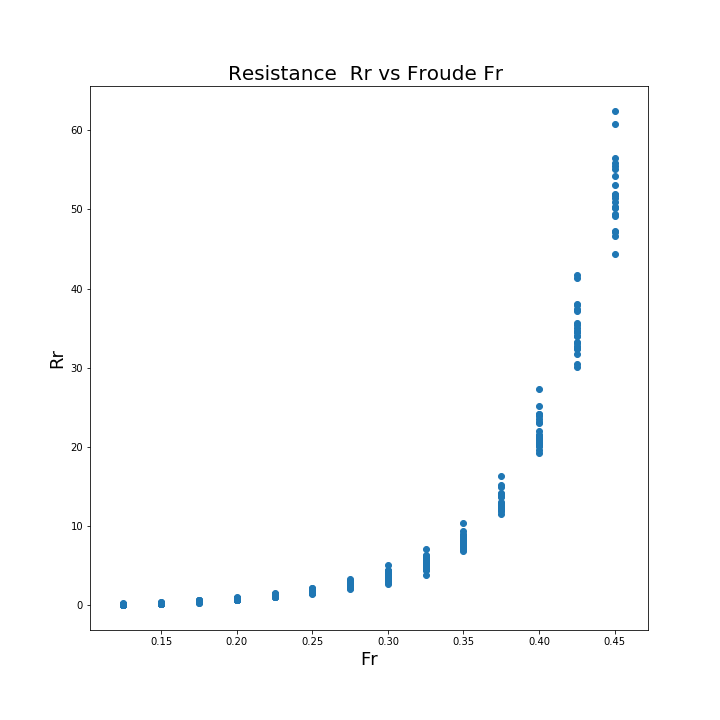
4.4.4. prédiction des propriétés hydraudynamiques des bateaux de plaisance#
Prédiction des propriétés hydraudynamiques (Résistance à l’avancement (vague+frottement) \(R_r\)) en fonction des caractéristiques géométrique et de la vitesse (nombre de Froude \(Fr=\frac{U}{\sqrt{gL}}\)
4.4.5. Apprentissage à partir de simulation FEM#
Les ingénieurs utilisent des modèles numériques pour analyser le comportement des systèmes qu’ils étudient. Cela permet une grande flexibilité pour modifier les paramètres et trouver la meilleur conception.
Mais lorsque les modèles sont trop complexes, les simulations numériques peuvent facilement durer très longtemps: de quelques heures à plusieurs jours. De plus, pendant le processus d’optimisation, vous pourriez avoir besoin plusieurs dizaines d’essais. Ainsi, afin de simplifier le processus, nous pouvons construire un modèle «de substitution» plus simple basé sur quelques simulations en utilisant l’apprentissage automatique.
4.4.6. Prédiction météo par IA#
Dans l’état actuel des choses, il existe des programmes de prévision météo basés sur des modèles physiques. Mais ces modèles physiques sont coûteux en temps de calcul. Des entreprises comme Google ont déjà produit des travaux montrant des accélérations incroyables par rapport aux méthodes physiques de pointe en concevant des réseaux de neurones basés sur du machine learning pour prédire la météo locale.
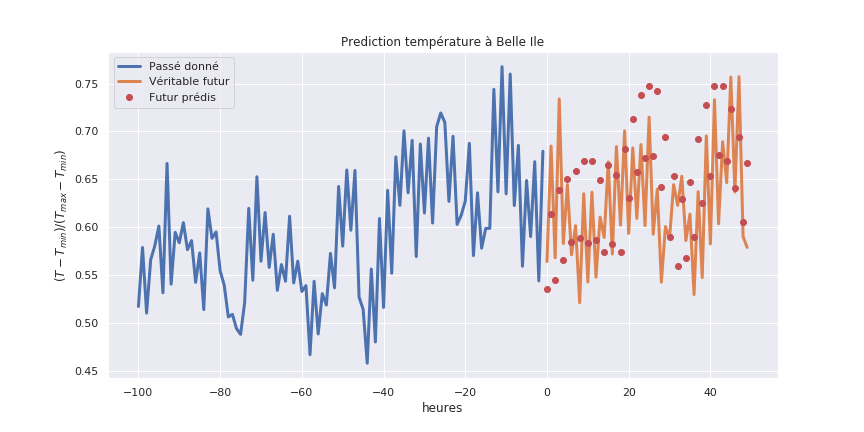
4.4.7. Physics-Informed Neural Networks (PINN)#
c’est nouvelle classe de réseaux de neurones qui hybride apprentissage automatique et lois physiques permettant une « meilleur » prédiction des réseaux de neuronnes (Deep Learning) pour des applications physiques gérées par des équations (ODE ou PDE):
Réseaux de neuronnes inspiré par la physique !!!
Les Physics-Informed Neural Networks (PINN) sont une méthode qui consiste à entraîner un réseau de neurones non seulement sur des données, mais aussi sur les lois physiques décrites par des équations différentielles. L’idée a été popularisée par Maziar Raissi et ses collaborateurs en 2019 Raissi, Perdikaris, and Karniadakis [RPK19] .
attention: aucune connaissance (compréhension) de la physique dans ces algorithmes.
4.4.8. application en mécanique des fluides#
from IPython.display import YouTubeVideo
YouTubeVideo('8e3OT2K99Kw', width=1200, height=600)
4.5. Outils de l’IA#
bibliothèques de base disponibles sous Python
numpy, scipy : calcul numérique
pandas : gestion de base de données
seaborn: statistical data visualization
4.5.1. scikit-learn: Machine Learning in Python (open source)#
outils simples et efficaces pour l’analyse prédictive des données
construit sur NumPy, SciPy et matplotlib
import sklearn
4.5.2. tensor-flow: (open source)#
outils d’apprentissage automatique développé par Google
utilisation de keras API de haut niveaux de tensor-flow
optimisation (multi-processing / GPU)
import tensorflow
4.5.3. torch / Pytorch#
PyTorch: bibliothèque d’intelligence artificielle open source développée par Meta (ex-Facebook)
import pytorch

4.6. Problèmatique du machine learning#
problème : prédire une loi \(\mathcal{F}\)
à partir de l’apprentissage à l’aide d’une base de données de test \(\textbf{X}_i, Y_i\)
\(\rightarrow\) Problème de minimisation
Trouver la meilleur approximation \(\mathbf{F}\) minimisant l’erreur \(J\) sur la base de données de test. \(J\) est une fonction coût du type:
4.7. Modélisation de résultats expérimentaux#
4.7.1. Etude de la dilatation d’une barre métallique#
mesure de la différence de longueur en fonction de la différence de température imposée
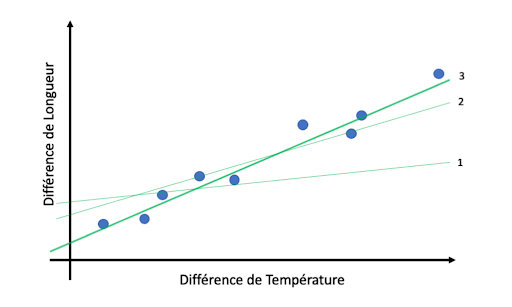
La modélisation consiste à ajuster une courbe aux données pour pouvoir ensuite faire de la prédiction.
Le modèle le plus simple est un ajustement linéaire, que l’on peut déterminer mathématiquement avec la méthode de la droite des moindres carrées qui minimise l’écart quadratique entre les points de mesure et le modèle.
Le modèle est simple et comporte uniquement 2 paramètres. A partir du modèle, on peut faire ensuite des prédictions.
L’apprentissage machine (machine learning), c’est tout simplement ça: l’ajustement d’un modèle à des données!
4.7.2. La révolution de l’intelligence artificielle#
Par rapport à notre exemple précédent, c’est juste une question d’échelle.
D’abord, les modèles les plus avancés à l’heure actuelle, notamment dans le domaine du traitement du langage, peuvent comporter plus de 100 milliards de paramètres, alors que notre modèle de dilatation thermique n’en a que deux.
Ensuite, ces modèles nécessitent une quantité phénoménale de données, souvent collectées automatiquement à partir de millions, voire de milliards de pages web. Dans l’exemple ci-dessus, nous avons entraîné notre modèle avec seulement 9 points de données.
Enfin, ces modèles sont capables de travailler sur des données de très haute dimension (big data).
Dans l’exemple de la dilatation thermique, nous avons considéré des données à deux dimensions: chaque point est représenté par deux variables, la différence de longueur et la différence de température.
Un réseau de neurones pour la classification d’image travaille quant à lui sur des images faites de pixels avec, pour chaque pixel, trois niveaux de couleur (rouge, vert, bleu) variant de 0 à 255. Ainsi, une image 200x200 pixels peut être considérée comme un « point » dans un espace à 200x200x3 = 120 000 dimensions !
Tout cela a été rendu possible grâce à deux avancées technologiques :
matériel: l’augmentation de la puissance des ordinateurs (GPU)
logiciel: et Internet (collecte data->apprentissage)
4.8. Introduction au Machine Learning#
problème général: prédire Y à partir d’une observation (donnée) X, i.e. la loi $\( Y = F(X) \)$
la fonction \(F(X)\) n’est pas connue analytiquement
\(\Rightarrow\) elle doit être définie « au mieux »
nécessité d’une base de données d’apprentissage (apprentissage)
nécessité de validation (base de données de tests) (validation)
remarques
aucune « intelligence réelle » , mais recherche de corrélation (par des processus non-linéaires)!
aucun caractère explicatif !
importance de la qualité de la base de données et du choix des entrées X
analyse (critique) du résultat
4.8.1. Grandes catégories d’algorithmes de machine learning#
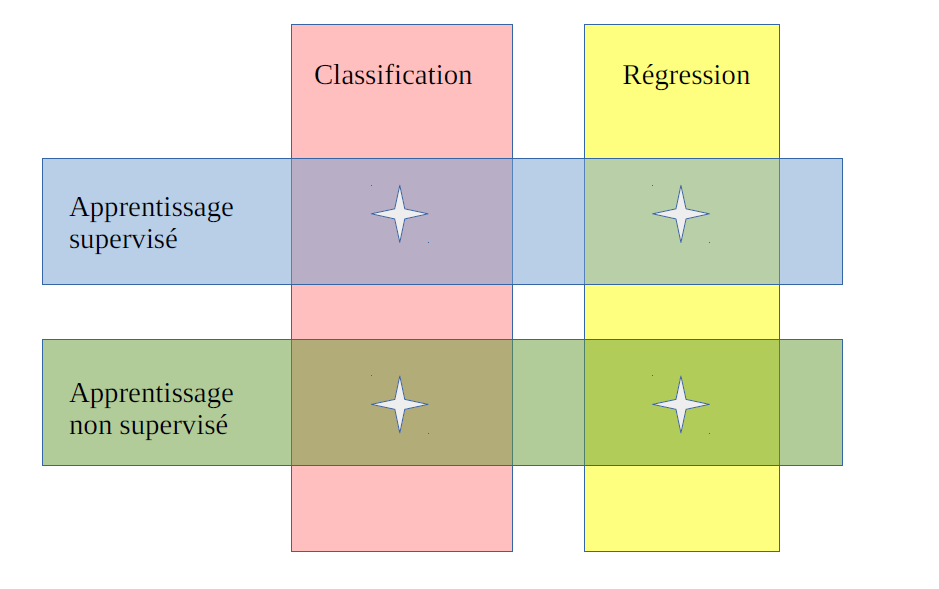 les différents types d’apprentissage
les différents types d’apprentissage
Supervisés |
Non supervisés |
|---|---|
les données d’apprentissage sont |
les données sont fournies sans |
étiquetées avec les résultats attendus |
les résultats attendus en sortie |
4.8.2. Classification / Régression#
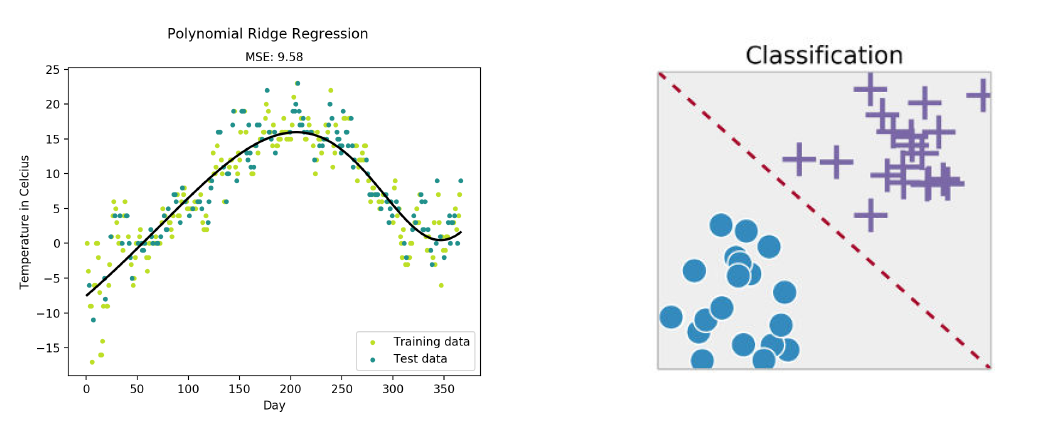
Régression |
Classification |
|---|---|
Prédire une variable quantitative |
Prédire une classe (qualitative, discrète) |
4.9. Une première méthode de Machine Learning : la régression linéaire#
problème: prévoir l’allongement d’un acier en fonction de la température
Méthode d’apprentissage supervisé :
Un jeu d’entrainement X, y issu de mesures
X : la température en °C (observable / data)
y : l’allongement en % (prédiction / target)
4.9.1. Trouver la droite qui se rapproche le plus du nuage de points#
solution = régression linéaire
4.10. La régression linéaire et fonction de coût#
Soit \(\{X_i,y_i\}_{i=1,m}\) un échantillon de taille m du jeu d’entraînement
4.10.2. Fonction coût J(a,b)#
exemple : écart quadratique
\(\leadsto\) Problème de minimisation
remarque
pour ce problème simple on a une solution analytique (droite des moindres carrés)
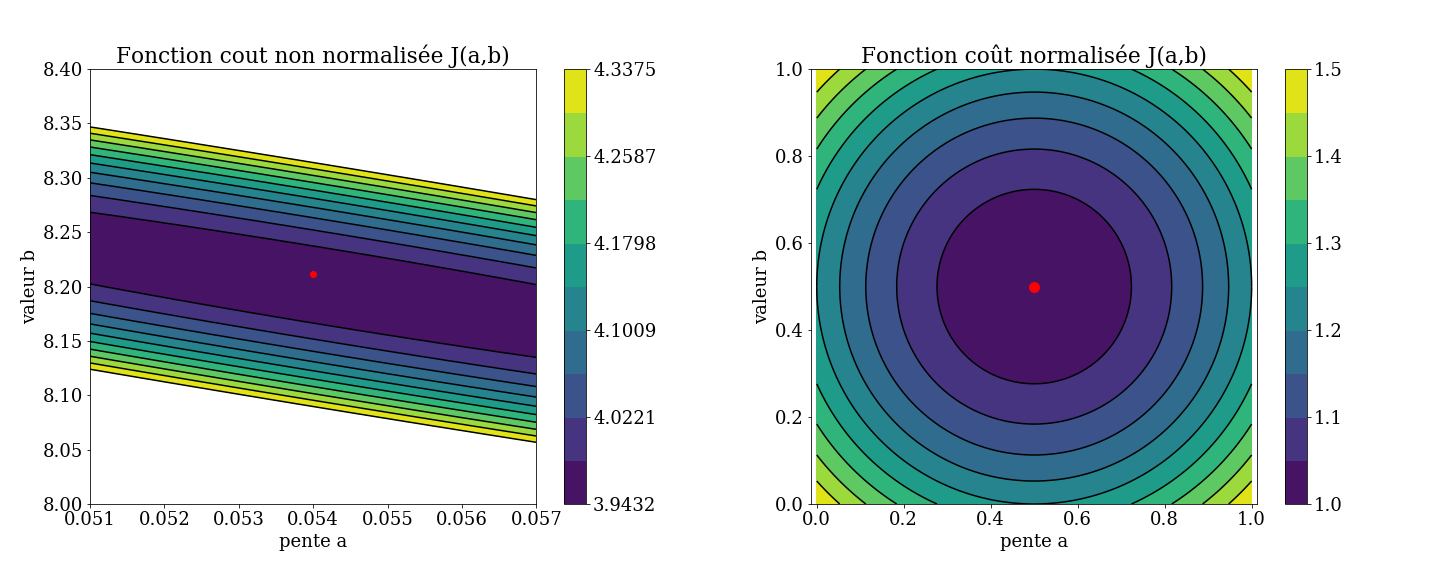
problème de normalisation
\(\leadsto\) forme de la fonction coût
difficulté du problème
forme des fonctions coût \(J(a,b)\)
4.11. Conclusion#
Machine learning: prédiction (numérique) d’une loi (valeur \(y\)) à partir d’observable \(X\)
\(F(X)\) transformation non linéaire des données \(X\) (observable) pour obtenir une prédiction \(y\)
basée sur une analyse statistique (type moindre carré) et un problème de minimisation et non sur un modèle !
Pas de caractère explicatifs !
Questions
choix de la transformation \(h(x)\) et des paramètres \(a_i\)
traitement de données
basée sur des corrélations supposées entre le résultat et les données
est ce de l’intelligence ?
4.11.1. méthodologie#
Phase d’apprentissage (training)
définition des meilleurs paramètres \(a_i\) qui permettent de prédire la meilleur valeur sur un jeux d’entrainement \(X^k,y^k\) .
problème de minimisation d’une fonction coût \(J\)
Phase de validation (testing)
test de la pertinence sur un jeux de test
erreur de prédiction, paramêtres, ..
Pas de méthode universelle !
4.12. Références#
« L’intelligence artificielle: introduction et applications en physique » par Colin Bernet
« Formation Deep Learning » de méteo-france
4.13. FIN#
Questions ?
4.10.1. Comment définir la « meilleure » prédiction \(h(x)\) ?#
dans ce cas simple on peut définir la prédiction \(h(x)\) sous forme explicite dépendant de 2 paramètres :
La « meilleure » prédiction \(h(x)\) (droite) est celle qui minimise une fonction de coût \(J\) qui mesure l’écart quadratique moyen entre la prédiction et la valeur réelle pour l’échantillon