4. TP Prédiction météo par IA#
Marc Buffat Dpt mécanique, UCB Lyon 1

4.1. Objectifs#
prévision complète de la météo par apprentissage (machine learning)
comparaison et validation de la prédiction.
utilisation de la librairie keras de tensor-flow (neural network)
Réseaux de neurones récurrents (RNN)
Les réseaux de neurones récurrents (RNN) sont une classe de réseaux de neurones puissants pour modéliser des données de séquence. Schématiquement, une couche RNN utilise une boucle for pour itérer sur les pas de temps d’une séquence, tout en maintenant un état interne qui code pour des informations sur les pas de temps qu’il a vu jusqu’à présent.
L’objectif est d’avoir une prédiction de la méteo du jour en utilisant les mesures du jour précédent
prédiction de la température par heure
%matplotlib inline
#algèbre linéaire
import numpy as np
import os, time
import pandas as pd
#représentation des résultats
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import display,Markdown
def printmd(text):
display(Markdown(text))
plt.rc('font', family='serif', size='18')
from validation.validation import info_etudiant
try: NUMERO_ETUDIANT
except NameError: NUMERO_ETUDIANT = None
if type(NUMERO_ETUDIANT) is not int :
printmd("**ERREUR:** numéro d'étudiant non spécifié!!!")
NOM, PRENOM, NUMERO_ETUDIANT = info_etudiant()
#raise AssertionError("NUMERO_ETUDIANT non défini")
# parametres spécifiques
_uid_ = NUMERO_ETUDIANT
np.random.seed(_uid_)
_station_test_ = 69029001 # Lyon Bron aeroport
_stations_ = [69299001, 69028001, 1089001, 42005001, 73329001 ]
_station_train_ = _stations_[np.random.randint(len(_stations_))]
# mois d'etude
_station_train_ = 69028001 # Brindas
_mois_ = np.random.randint(1,13)
printmd("**Login étudiant {} {} uid={}**".format(NOM,PRENOM,_uid_))
printmd(f"Station méteo pour l'apprentissage: {_station_train_}")
printmd(f"Station méteo pour le test (Lyon Bron): {_station_test_}")
printmd(f"Etude pour les mois {_mois_} à {_mois_+1} de 2016")
ERREUR: numéro d’étudiant non spécifié!!!
Login étudiant Marc BUFFAT uid=137764122
Station méteo pour l’apprentissage: 69028001
Station méteo pour le test (Lyon Bron): 69029001
Etude pour les mois 3 à 4 de 2016
4.2. Base de données meteo#
utilisation de la base de données météonet
4.2.1. structure des données des stations meteo (mesure / 5 minutes)#
Paramètres de métadonnées
number_sta : numéro de la station au sol
lat : latitude en degrés décimaux
lon : longitude en degrés décimaux
height_sta : hauteur de la station en mètres
Le paramètre date est un objet datetime au format ‘AAAA-MM-JJ HH:mm:ss’.
Paramètres météorologiques
dd : direction du vent en degrés
ff : vitesse du vent en m.s-1
precip : précipitations durant la période de référence en kg.m2
hu : humidité en %
td : température du point de rosée en Kelvin
t : température en Kelvin
psl : pression réduite au niveau de la mer en Pa
température du point de rosée: td (wikipedia)
Le point de rosée ou température de rosée est la température sous laquelle de la rosée se dépose naturellement. Plus techniquement, en dessous de cette température qui dépend de la pression et l’humidité ambiantes, la vapeur d’eau contenue dans l’air se condense sur les surfaces, par effet de saturation.
En météorologie, la température de rosée est parfois utilisée pour estimer le niveau de confort, comme une température ressentie. La température de rosée détermine en effet si la transpiration s’évaporera de la peau, causant ainsi un rafraîchissement de l’organisme. Contrairement à la température, qui varie généralement considérablement entre le jour et la nuit, les points de rosée varient plus lentement. Ainsi, bien que la température puisse chuter la nuit, une journée lourde est généralement suivie d’une nuit lourde.
précipitation: precip (wikipedia)
la dimension des données ‘precip’ est kg/m^2 sur 5 min (une mesure toutes les 5 minutes).
On la convertit en mm d’eau par m^2 et par heure (en xiant par 12)
La quantité de pluie tombée se mesure en mm (millimètre). Un mm représente un litre d’eau tombé par mètre carré. Selon les situations, la pluie tombe avec différentes intensités.
pluie faible: < 2.5 mm / heure
pluie modérée < 7.5 mm / heure
pluie forte > 7.5 mm / heure
4.2.2. Lecture base de données#
Lecture de la base de test et d’apprentissage:
dans le répertoire /home/cours/DatabaseIA/data_meteonet/SE/ground_stations/
sous dossier et fichier csv:
annee/SE{annee}_{mois}.csv
2016/SE2016_01.csvpour janvier 2016 (attention au format)
lire la base de données pour les 2 mois consécutifs donnés
création de
création de 2 dataset panda:
data_train
data_test
#importation de notre dataset sous panda
directory = "/home/cours/DatabaseIA/data_meteonet/SE/ground_stations/"
data = None
station_test = _station_test_
station_train = _station_train_
printmd(f"## Base de données de test {station_test} et d'entrainement {station_train}")
### BEGIN SOLUTION
# choix annee et mois
annee = 2016
mois = _mois_
fname = directory + f'{annee}/SE{annee}_{mois:02d}.csv'
df = pd.read_csv(fname,parse_dates=[4],infer_datetime_format=True)
data_test = df[(df['number_sta'] == station_test)].copy()
data_train = df[(df['number_sta'] == station_train)].copy()
fname = directory + f'{annee}/SE{annee}_{mois+1:02d}.csv'
df = pd.read_csv(fname,parse_dates=[4],infer_datetime_format=True)
data_test1 = df[(df['number_sta'] == station_test)]
data_train1 = df[(df['number_sta'] == station_train)]
data_test = pd.concat([data_test,data_test1])
data_train = pd.concat([data_train,data_train1])
### END SOLUTION
data_test.info()
data_train.info()
Base de données de test 69029001 et d’entrainement 69028001
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Cell In[3], line 12
10 mois = _mois_
11 fname = directory + f'{annee}/SE{annee}_{mois:02d}.csv'
---> 12 df = pd.read_csv(fname,parse_dates=[4],infer_datetime_format=True)
13 data_test = df[(df['number_sta'] == station_test)].copy()
14 data_train = df[(df['number_sta'] == station_train)].copy()
File ~/venvs/jupyter/lib/python3.10/site-packages/pandas/util/_decorators.py:211, in deprecate_kwarg.<locals>._deprecate_kwarg.<locals>.wrapper(*args, **kwargs)
209 else:
210 kwargs[new_arg_name] = new_arg_value
--> 211 return func(*args, **kwargs)
File ~/venvs/jupyter/lib/python3.10/site-packages/pandas/util/_decorators.py:331, in deprecate_nonkeyword_arguments.<locals>.decorate.<locals>.wrapper(*args, **kwargs)
325 if len(args) > num_allow_args:
326 warnings.warn(
327 msg.format(arguments=_format_argument_list(allow_args)),
328 FutureWarning,
329 stacklevel=find_stack_level(),
330 )
--> 331 return func(*args, **kwargs)
File ~/venvs/jupyter/lib/python3.10/site-packages/pandas/io/parsers/readers.py:950, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, error_bad_lines, warn_bad_lines, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options)
935 kwds_defaults = _refine_defaults_read(
936 dialect,
937 delimiter,
(...)
946 defaults={"delimiter": ","},
947 )
948 kwds.update(kwds_defaults)
--> 950 return _read(filepath_or_buffer, kwds)
File ~/venvs/jupyter/lib/python3.10/site-packages/pandas/io/parsers/readers.py:605, in _read(filepath_or_buffer, kwds)
602 _validate_names(kwds.get("names", None))
604 # Create the parser.
--> 605 parser = TextFileReader(filepath_or_buffer, **kwds)
607 if chunksize or iterator:
608 return parser
File ~/venvs/jupyter/lib/python3.10/site-packages/pandas/io/parsers/readers.py:1442, in TextFileReader.__init__(self, f, engine, **kwds)
1439 self.options["has_index_names"] = kwds["has_index_names"]
1441 self.handles: IOHandles | None = None
-> 1442 self._engine = self._make_engine(f, self.engine)
File ~/venvs/jupyter/lib/python3.10/site-packages/pandas/io/parsers/readers.py:1735, in TextFileReader._make_engine(self, f, engine)
1733 if "b" not in mode:
1734 mode += "b"
-> 1735 self.handles = get_handle(
1736 f,
1737 mode,
1738 encoding=self.options.get("encoding", None),
1739 compression=self.options.get("compression", None),
1740 memory_map=self.options.get("memory_map", False),
1741 is_text=is_text,
1742 errors=self.options.get("encoding_errors", "strict"),
1743 storage_options=self.options.get("storage_options", None),
1744 )
1745 assert self.handles is not None
1746 f = self.handles.handle
File ~/venvs/jupyter/lib/python3.10/site-packages/pandas/io/common.py:856, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
851 elif isinstance(handle, str):
852 # Check whether the filename is to be opened in binary mode.
853 # Binary mode does not support 'encoding' and 'newline'.
854 if ioargs.encoding and "b" not in ioargs.mode:
855 # Encoding
--> 856 handle = open(
857 handle,
858 ioargs.mode,
859 encoding=ioargs.encoding,
860 errors=errors,
861 newline="",
862 )
863 else:
864 # Binary mode
865 handle = open(handle, ioargs.mode)
FileNotFoundError: [Errno 2] No such file or directory: '/home/cours/DatabaseIA/data_meteonet/SE/ground_stations/2016/SE2016_03.csv'
assert(isinstance(data_test,pd.DataFrame))
assert(isinstance(data_train,pd.DataFrame))
assert((data_test.shape[0]>14000) and (data_train.shape[0]>14000))
assert((data_test.shape[1]==12) and (data_train.shape[1]==12))
4.2.3. Information sur les 2 stations méteo#
on a une base de données pour 2 stations météo :
la station de test qui est la station la plus proche de Lyon
une station d’apprentissage
En allant sur le site météo France (menu informations sur les stations)
déterminer les caractéristiques de ces 2 stations météo
On déterminera en particulier la distance entre les 2 stations météo
!ls -al Images/geodesique.png
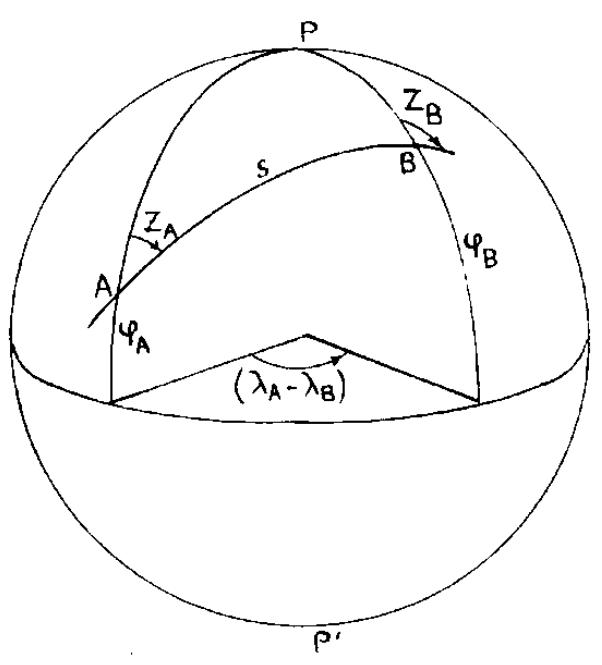
4.2.3.1. calcul de la distance des stations méteo à Lyon 1 (géodésique)#
La géodésique est la trajectoire correspondant à la distance minimale entre deux points sur une surface. Dans le cas de la sphère, c’est un arc de grand cercle.Connaissant la position de deux points A et B sur une sphère, calculer la distance entre eux revient donc à calculer l’abscisse curviligne S (AB) sur le grand cercle passant par A et B.
Si l’on considère deux points A et B sur la sphère, de latitudes \(\phi_A\) et \(\phi_B\) et de longitudes \(\lambda_A\) et \(\lambda_B\), alors la distance angulaire en radians entre A et B est donnée par la relation fondamentale de trigonométrie sphérique:
La distance S en mètres, s’obtient en multipliant \(S_{AB}\) par un rayon de la Terre conventionnel (6 378 137 mètres par exemple).
# calcul de la distance en km entre les 2 stations
dist_station = None
### BEGIN SOLUTION
lat0 = data_test['lat'][data_test.index[0]]
print(data_test.loc[:,'lat'])
lat = data_train['lat'][data_train.index[0]]
long0 = data_test['lon'][data_test.index[0]]
long = data_train['lon'][data_train.index[0]]
R = 6378.137 # rayon terre en km
phiB = np.radians(lat)
phiA = np.radians(lat0)
lAB = np.radians(long0-long)
SAB = np.arccos(np.sin(phiA)*np.sin(phiB) +
np.cos(phiA)*np.cos(phiB)*np.cos(lAB))
dist_station = SAB*R
### END SOLUTION
printmd(f"**distance** {dist_station:.2f} km")
assert (dist_station > 0)
4.3. Nettoyage de la BD pour ces stations#
indexation des base de données avec la date
élimination des données inutiles: colonnes de position, hauteur, ou non utilisés vent, pression
‘number_sta’, ‘lat’, ‘lon’, ‘height_sta’,’ff’,’dd’,’psl’
interpole les données dans les colonnes utilisées pour les données manquantes
‘td’ , ‘precip’ , ‘hu’, ‘t’
def print_info(dataset,titre=""):
"""affiche information sur dataset"""
N = len(dataset)
display(dataset.info())
print(f"Taille des donnees N={N} et % donnees manquantes. {titre}")
display(dataset.isna().sum())
display(dataset.describe(percentiles=[]))
return
# nettoyage des 2 BD data_test et data_train
### BEGIN SOLUTION
def clean_data(data,station):
data.set_index('date', inplace=True)
print(f"Bilan station {station_test} position: {data['lat'][0]}°,{data['lon'][0]}° h={data['height_sta'][0]}")
data = data.drop(['number_sta', 'lat', 'lon', 'height_sta','ff','dd','psl'], axis = 1)
# interpolation des données manquantes
data['td'] = data['td'].interpolate('linear')
data['precip'] = data['precip'].interpolate('linear')
data['hu'] = data['hu'].interpolate('linear')
data['t'] = data['t'].interpolate('linear')
return data
# base de données test
data_test = clean_data(data_test,station_test)
print_info(data_test,"dataset test")
data_train = clean_data(data_train,station_train)
print_info(data_train,"dataset training")
### END SOLUTION
assert((data_train.shape[1] == 4) and (data_test.shape[1] == 4))
data_train.shape
4.4. Bibliothéques d’IA#
#Machine learning
from sklearn import preprocessing
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
4.5. Préparation de la base de données#
A partir de ces 2 bases de données, nous allons maintenant construire les données pour l’apprentissage
On veut faire une prédiction sur la température
on sélectionne les données de température: colonne ‘t’
on normalise les données entre 0 et 1 en utilisant la même normalisation (basé sur la BD de training)
on ré-échantillonne la série pour avoir des données par heure (et non toutes les 5 minutes)
les 2 séries de données sont mises dans T_train et T_test
# colonne de donnees a analyser
col = 't'
T_train_norm = None
T_test_norm = None
Tmin = None
Tmax = None
### BEGIN SOLUTION
# normalisation de la colonne a étudié
Tmin = data_train[col].min()
Tmax = data_train[col].max()
print(f"Tmin={Tmin} Tmax={Tmax}")
T_train_norm = (data_train[col]-Tmin)/(Tmax-Tmin)
T_test_norm = (data_test[col]-Tmin)/(Tmax-Tmin)
#on prend la moyenne sur des périodes (en sec.) de 1 heure
periode='60T'
T_train = T_train_norm.resample(periode).mean()
T_test = T_test_norm.resample(periode).mean()
T_train.info()
T_test_norm.info()
### END SOLUTION
assert(isinstance(T_test,pd.Series))
assert(isinstance(T_train,pd.Series))
assert(T_test.shape[0] == T_train.shape[0])
assert(((T_test.shape[0]/24) > 58 ) and ((T_test.shape[0]/24) < 63 ))
4.5.1. Tracés des 2 séries de températures#
sur la figure suivante,on trace les données pour vérifier la validité de l’approche
plt.figure(figsize=(14,6))
ax = plt.gca()
T_train.plot(ax=ax,label="training")
T_test.plot(ax=ax,label="test")
plt.title("Base de données de température adimen. ")
plt.legend();
4.6. Création du modèle d’IA#
pour cet apprentissage en temps:
on veut prédire le temps du lendemain, connaissant le temps du jour
les données d’entrée sont donc des mesures de température sur 24h (une par heure)
en sortie on a l’évolution de la température sur les 24h suivantes (une par heure)
Il faut donc segmenter la base de données pour créer des segments de données de 24 valeurs de température consécutive, et des segments de résultats associées des 24 valeurs suivantes.
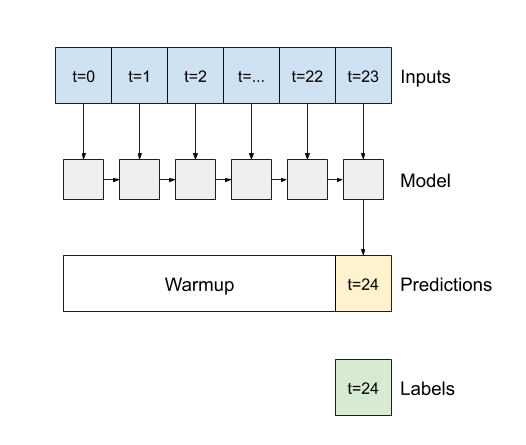
On note:
Nh le nombre de points d’histoire à considérer
Np le nombre de points à prédire
Effectuer cette segmentation des données pour construire les tableaux suivants
- X_entrainement, Y_entrainement pour le traing
- X_test, Y_test pour le test
#Selection du nombre de points de donnés (histoire) et le nombre en prédiction
Nh = 24
Np = 24
print("taille BD:",T_train.shape, T_test.shape," et intervalles : ", Nh,Np)
X_entrainement= None; Y_entrainement = None
X_test= None; Y_test = None
### BEGIN SOLUTION
def segment(dataset, intervale=0, futur=0):
"""segmentation des données et des resultats (labels) par intervalles de valeurs """
data = []
labels = []
for i in range(len(dataset)):
debut_index = i
fin_index = i + intervale
futur_index = i + intervale + futur
if futur_index >= len(dataset):
break
data.append(dataset[i:fin_index])
labels.append(dataset[fin_index:futur_index])
return np.array(data), np.array(labels)
# Prépare des sacs de données suivant la sélection et affiche la dimension des données
def segmentation(dataset):
X, Y = segment(dataset, intervale = Nh, futur = Np)
X = X.reshape(X.shape[0], Nh, 1)
Y = Y.reshape(Y.shape[0], Np, 1)
print("Dimension du Passé: ", X.shape)
print("Dimension du Futur: ", Y.shape)
return X,Y
# creation des donnees
X_entrainement,Y_entrainement=segmentation(T_train)
X_test,Y_test=segmentation(T_test)
### END SOLUTION
assert(X_entrainement.shape[1:] == (Nh,1))
assert(Y_entrainement.shape[1:] == (Np,1))
assert(X_test.shape[1:] == (Nh,1))
assert(Y_test.shape[1:] == (Np,1))
print("dimension DB :",X_test.shape)
# visualisation des données sur 2 sequences la 1ere et la 50ième
plt.figure(figsize=(12,6))
t = np.arange(X_entrainement.shape[0])
for i in [0,49]:
plt.scatter(t[i],X_entrainement[i,0,0])
plt.plot(t[i:i+Nh],X_entrainement[i,:,0],label=f"seq {i}")
plt.scatter(t[i+Nh:t[i+Nh+Np]],Y_entrainement[i,:],marker='x',c='k')
plt.title(f"séquences de {Nh} valeurs")
plt.legend();
4.7. Apprentissage#
utilisation d’un réseaux de neurones récurrents RNN de type LSTM avec la bibliothéque keras
Long Short-Term Memory layer - Hochreiter 1997.
documentation keras
modèle par defaut:
un réseau récurrent LSM (dimension Nh)
un réseau Dense pour adapter la dimension en sortie Np
paramètres par défauts (à optimiser éventuellement)
# construction du modele LSTM
model = Sequential([
LSTM(Nh),
Dense(Np),
])
#Configuration du modèle(on minimise avec la méthode des moindres carrés)
model.compile(optimizer='adam', loss='mse')
print("Taille de la base de données training:",X_entrainement.shape, Y_entrainement.shape)
print("Taille de la base de données test :",X_test.shape, Y_test.shape)
4.7.1. paramètres d’apprentissage#
Epoch dans le contexte de l’entraînement d’un modèle, l’epoch est un terme utilisé pour référer à une itération où le modèle voit tout le training set pour mettre à jour ses coefficients.
mae Calcule la moyenne de la différence absolue entre les résultats et les prédictions.
loss Le but des fonctions de perte (loss) est de calculer la quantité qu’un modèle doit chercher à minimiser pendant l’apprentissage
lancer l’apprentissage du modèle sur la base de training,
on notera history le résultat de la fonction d’apprentissage (fit)
puis faire la prédiction du la base de test
On notera YPred la prédiction sur la base de test. Pour comparer cette prédication, on remettra (avec la méthode reshape) le tableau Y_test sous la même forme que YPred
On pourra jouer sur la paramètre EPOQUE, nbre d’itération du modèle d’apprentissage en temps
#Lance l'entrainement du modèle
EPOQUE = 100
history = None
YPred = None
### BEGIN SOLUTION
import time
time_start = time.time()
history = model.fit(X_entrainement, Y_entrainement, epochs=EPOQUE, verbose = True)
print('phase apprentissage: {:.2f} seconds'.format(time.time()-time_start))
# prédiction sur la station test
time_start = time.time()
YPred = model.predict(X_test, verbose=False)
Y_test = Y_test.reshape(Y_test.shape[0], Np,)
print('phase test: {:.2f} seconds'.format(time.time()-time_start))
### END SOLUTION
assert(YPred.shape == Y_test.shape)
assert(history.history['loss'][-1] < 0.015)
plt.title("convergence apprentissage")
plt.plot(history.history['loss'], label='train')
plt.legend();
# bilan de l'apprentissage
from sklearn.metrics import r2_score
print("R2 score {:.2f}".format(r2_score(Y_test, YPred)))
print("model evaluate loss/mae")
model.evaluate(X_test,Y_test)
model.summary()
4.8. Affichage des résultats#
4.8.1. Transformation des résultats#
à partir des résultats sans dimension
conversion des résultats en °C dans
Thist pour les données X_test
Tpred pour les prédictions Ypred
Ttest pour les resultats Y_test
# renormalisation des resultats
Thist = None
Tpred = None
Ttest = None
### BEGIN SOLUTION
Thist = X_test * (Tmax-Tmin) + (Tmin - 273.15)
Tpred = YPred * (Tmax-Tmin) + (Tmin - 273.15)
Ttest = Y_test * (Tmax-Tmin) + (Tmin - 273.15)
### END SOLUTION
print("Dimension: ",Thist.shape, Tpred.shape, Ttest.shape)
assert(Thist.shape == X_test.shape)
assert(Tpred.shape == YPred.shape)
assert(Thist.max()>1.0)
assert(Tpred.max()>1.0)
assert(Ttest.max()>1.0)
4.8.2. Tracé des résultats#
def plot_multi_etape(historique, vrai_futur, prediction, titre):
"""fonction pour tracer une prédiction sur un jour fixé"""
plt.figure(figsize=(12, 6))
num_passe = np.arange(-len(historique),0)
num_futur = np.arange(len(vrai_futur))
plt.plot(num_passe, np.array(historique[:, 0]), label='Passé donné')
plt.plot(num_futur, np.array(vrai_futur), label='Véritable futur')
plt.plot(num_futur, np.array(prediction), '-ro', label='Futur prédis')
plt.legend(loc='upper left')
plt.title(titre)
plt.xlabel("heures")
plt.ylabel("T en °C");
return
#Première figure: La prédiction sur le mois
plt.figure(figsize=(30,8))
sns.set(rc={"lines.linewidth": 3})
sns.lineplot(x=t, y=Tpred[:,0], color="green")
sns.set(rc={"lines.linewidth": 3})
sns.lineplot(x=t, y=Ttest[:,0], color="coral")
plt.margins(x=0, y=0.5)
plt.legend(["Mesure", "Prédiction"])
plt.title("Prediction / mesure");
plt.xlim([0,24*10])
plt.ylim([-5,30]);
#Deuxième figure: Une prédiction particulière pour une date
date = f"2016-{mois:2d}-05 00:00:00"
cas = T_test.index.get_loc(date) + Nh
plot_multi_etape(Thist[cas], Ttest[cas], Tpred[cas],
titre=f"Prediction température à Lyon 1 le {date}")
# idem mais pour le mois suivant
date = f'2016-{mois+1:2d}-19 00:00:00'
cas = T_test.index.get_loc(date) + Nh
plot_multi_etape(Thist[cas], Ttest[cas], Tpred[cas],
titre=f"Prediction température à Lyon 1 le {date}")
4.9. Amélioration de la prédiction#
Dans les cellules suivantes, proposer et tester des améliorations de la prédiction
utilisation des données sur les 2 jours précédents
optimisation des paramètres
4.9.1. décrire ici les proposition d’amélioration#
# tester les améliorations proposées
### BEGIN SOLUTION
### END SOLUTION
4.10. Analyse et conclusion#
écrire votre analyse en markdown dans la cellule suivante
Votre analyse