6. Implementation of IA/ML#
Marc BUFFAT , dpt mécanique, Université Lyon 1
(1) inspired from “formation Deep Learning (météo france)” MétéoFrance [2018]
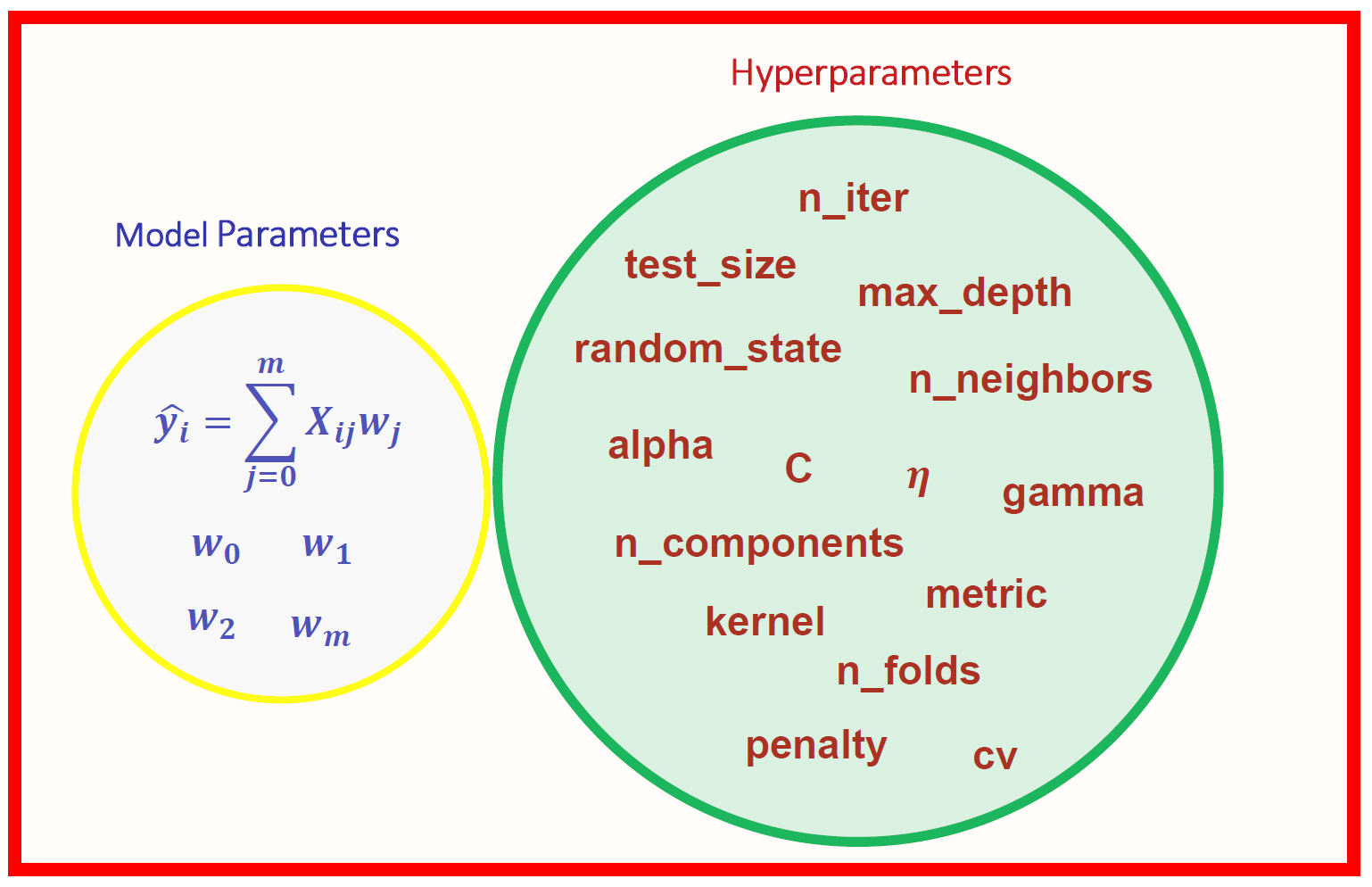
6.1. Hyper-paramètres#
Parameters of a Machine Learning model?
Type and complexity of the model
Linear regression is a simple model, but it can be made more complex:
polynomial of degree n, random forest, neural networks…
Specific Model Parameters
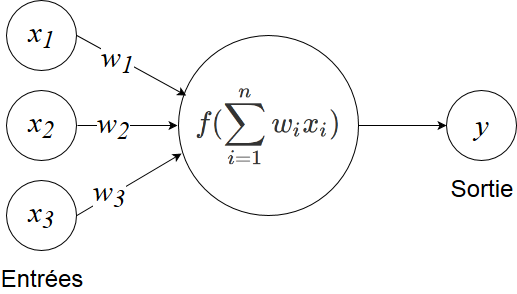
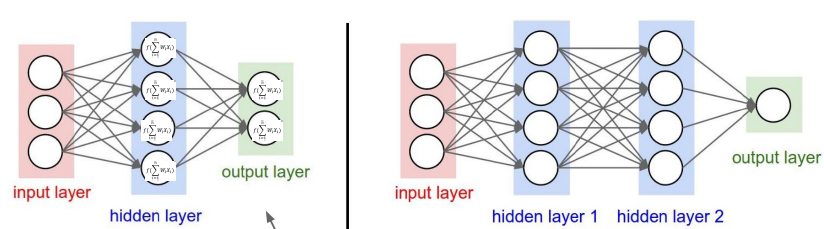
For a neural network:
number of layers and number of neurons per layer…
Learning rate (descent parameter)
Mini-batch size
Epochs (number of iterations over the model)
6.2. Evaluation of the model#
\(\Rightarrow\) Necessity to split the dataset into 3 parts:
Train on the training set,
Choose the hyperparameters that work best on a validation set,
Test the model on a test set.

6.3. Problems#
Underfitting: Occurs when a model is too simple to capture the underlying patterns in the data. It results in poor performance on both the training and test datasets. This can happen when:
The model has too few parameters.
The model is not trained long enough.
The features provided to the model are not informative enough.
Overfitting: Occurs when a model is too complex and captures noise along with the underlying patterns in the training data. It performs well on the training set but poorly on the test set. This can happen when:
The model has too many parameters.
The model is trained for too long.
The model captures specific patterns of the training data, including noise, which do not generalize to unseen data.
Balancing the two: The goal is to find the right balance where the model is complex enough to capture the underlying patterns in the data but not so complex that it captures noise. This can be achieved through:
Cross-validation.
Regularization techniques.
Pruning in decision trees.
Using dropout in neural networks.
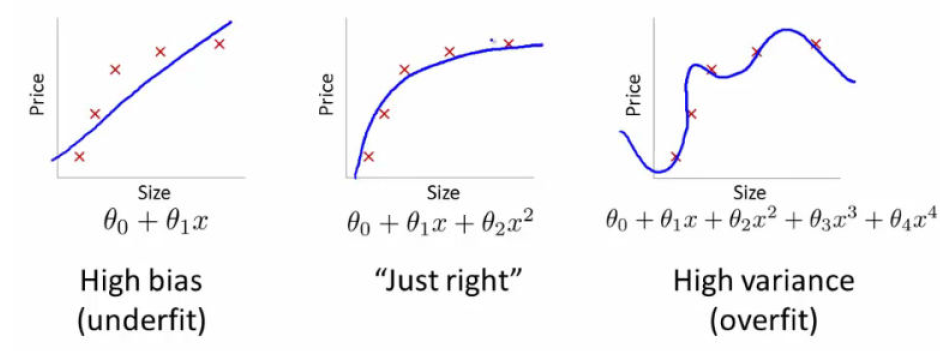
6.3.1. Underfitting - Overfitting the data#
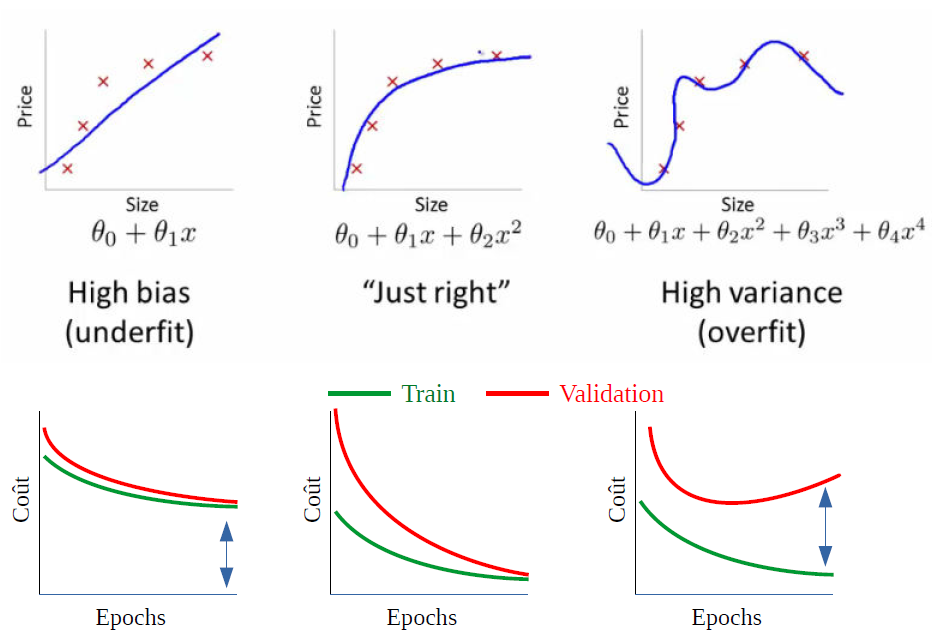
6.3.2. Fight Under-fitting#
Increase model complexity
Example: Use a quadratic model instead of a linear model
Add more predictors, i.e., other parameters
6.3.3. Fight Over-fitting#
Add more training data
Simplify the model or remove predictors
Prevent the model from “memorizing” the training set
Train the model for a shorter duration
Prevent the model from over-learning.
6.4. Tools for AI#
basic libraries in Python
numpy, scipy : numerical calculation
pandas : data base
seaborn: statistical data visualization
scikit-learn: Machine Learning in Python (open source)
Simple and Effective Tools for Predictive Data Analysis
Built on NumPy, SciPy, and matplotlib
tensor-flow: (open source by google)
Machine Learning Tools Developed by Google
Use of Keras: High-level API of TensorFlow
optimization (use of GPU / and multi-cores)
version of tensor-flow for GP/GPU
XGBoost: optimized distributed gradient boosting library (parallel tree boosting on distributed env.)
torch (open-source by meta)
pytorch python interface
open source PyTorch framework and ecosystem for deep learning
highly optimized on GPU (cuda)
6.5. AI Algorithms#
Implicit Algorithm ! (result depends on the data)!
Random Forest Regression Algorithm
Very effective on medium-sized datasets
However, scaling issues
Neural Network Algorithm
Less precise and much heavier (sensitive to parameters, dimensionality reduction)
But scalable for Big Data datasets (e.g., Google, Meta, Microsoft)
deep learning
%matplotlib inline
import sys
import numpy as np
import matplotlib.pyplot as plt
# police des titres
plt.rc('font', family='serif', size='18')
from IPython.display import display,Markdown
import sklearn as sk
#sys.path.insert(1,"/home/cours/DatabaseIA")
from datasetIA import *
6.5.1. Random Forest#
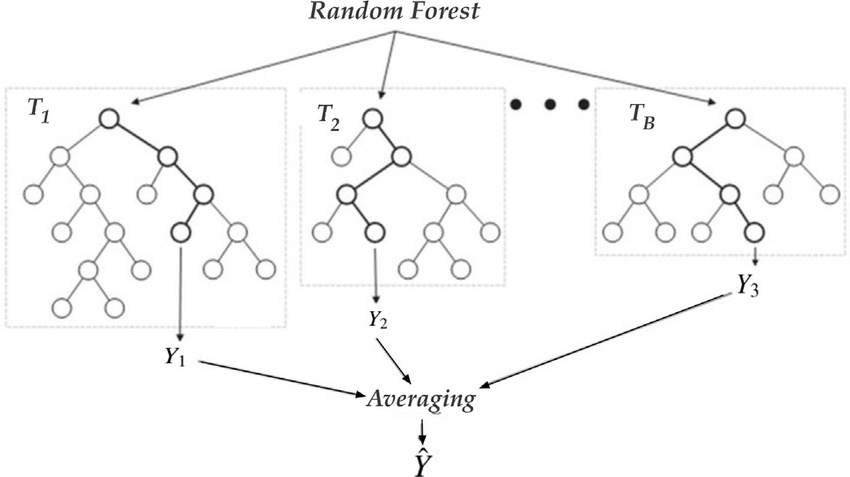
from sklearn.ensemble import RandomForestRegressor
N=11
X,y = dataset1(N)
clf = RandomForestRegressor(max_depth=None, random_state=0)
cfl = clf.fit(X, y)
print("score = {:2d}%".format(int(100*clf.score(X, y))))
score = 98%
NN = 51
Xpred = np.array([[1,x] for x in np.linspace(1,4,21) ])
ypred = clf.predict(Xpred)
plot1(N,X,y, Xpred,ypred,titre="random forest")
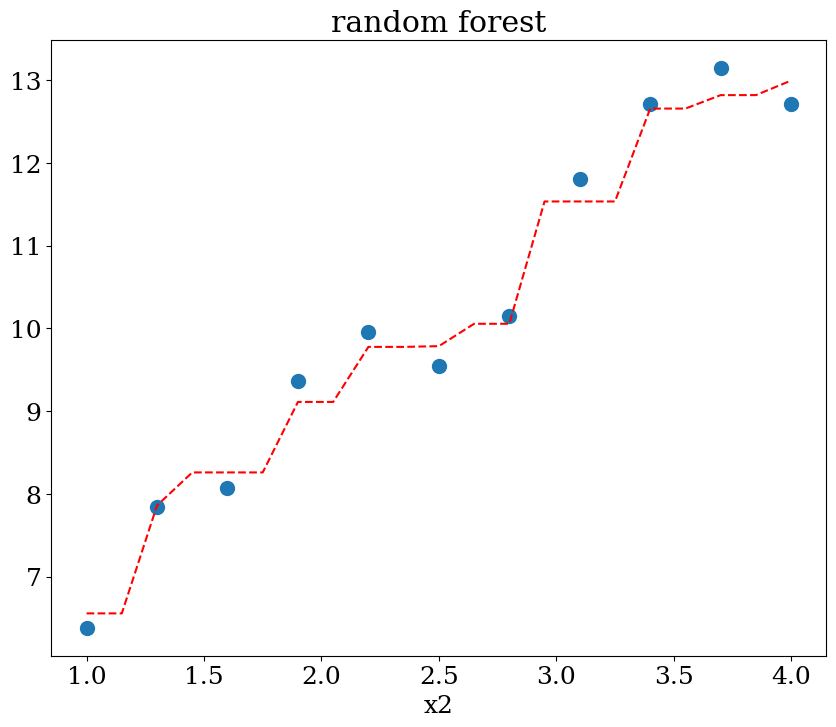
6.5.2. Neural network#
from sklearn.neural_network import MLPRegressor
N = 11
X,y = dataset1(N)
clf = MLPRegressor(hidden_layer_sizes=(N**2,N**2,N**2), max_iter=400, random_state=1, verbose = False)
clf = clf.fit(X,y)
print("score = {:2d}%".format(int(100*clf.score(X, y))))
score = 43%
NN = 51
Xpred = np.array([[1,x] for x in np.linspace(1,4,21) ])
ypred = clf.predict(Xpred)
plot1(N,X,y, Xpred,ypred,titre="Reseaux neuronnes")
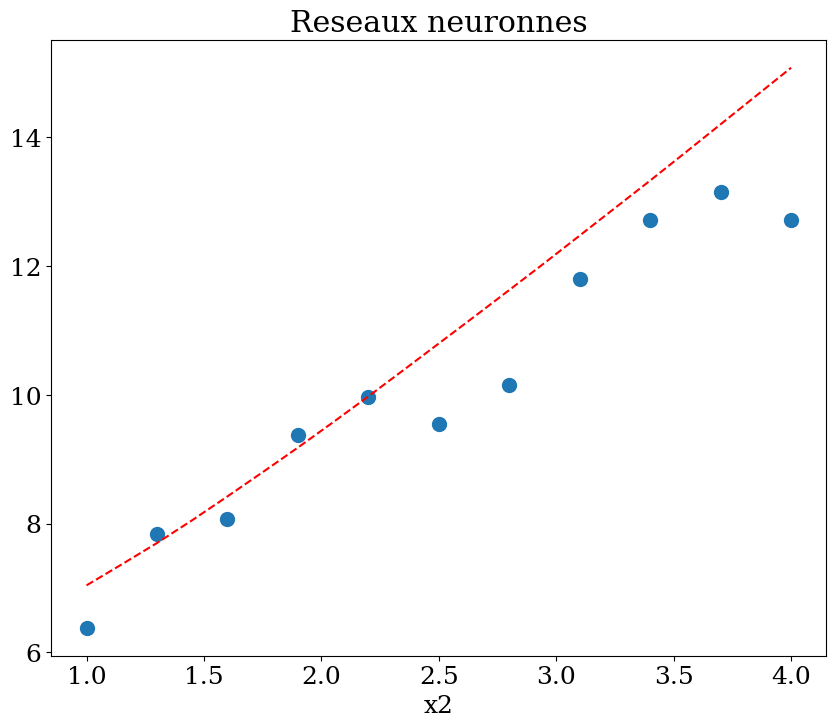
6.6. Conclusion#
Knowledge of the problem is important
Choice and Relevance of Data (Dataset): Understanding which data is relevant and how it can be used effectively.
Plausible Correlation: Identifying and understanding the relationships between variables.
Data Organization:
Training: Training datasets
Validation: Validation datasets (for parameter optimization)
Test: Test datasets
Choice of Algorithms: Selecting the appropriate algorithms based on the problem and data characteristics.
Analysis of Results: Interpreting and evaluating the results to ensure they align with the problem requirements and objectives.
Model Generation represents a trade-off between precision and effort. A custom analytical model will likely offer higher precision, whereas a well-trained neural network (NN) machine learning model can provide acceptable precision at a lower cost, albeit with some uncertainty due to random initialization.
see “Application of machine learning procedures for mechanical system modeling” {cite:ts}`Groensfelder2020