8. Software and hardware for AI/ML Computing#
Marc BUFFAT , dpt mécanique, Université Lyon 1
Software is the key of AI, but knowledge of the underlying hardware is extremely important to run the software efficiently
8.1. Documentation#
8.2. Introduction#
The hardware that powers machine learning (ML) algorithms is just as crucial as the code itself. CPUs have been the backbone of computing for decades, but GPUs (and now TPU) are the new emerging hardware for AI.
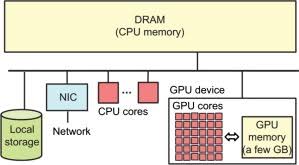
CPU (Central Processing Unit)
CPU are the primary processing units in any computing system, responsible for executing instructions of a computer program. They’re general-purpose processors capable of handling a wide range of tasks, which makes them versatile for various applications—including machine learning inference.
GPU (Graphics Processing Unit)
Initially designed for rendering graphics and images, GPUs (graphics processing units) have evolved into powerful processors for parallel computation, making them highly suitable for machine learning inference.
TPU (Tensor Processing Units) TPUs (tensor processing units) are application-specific integrated circuits (ASICs) developed by Google specifically for accelerating machine learning workloads. They’re designed to handle the computational demands of both training and inference phases in machine learning, with a particular focus on deep learning models.
8.2.1. CPU hardware#
CPUs are versatile pieces of hardware adapted for General-purpose and small-scale. While CPUs are versatile and omnipresent, they face certain challenges for machine learning applications.
Performance and parallel processing
CPUs are designed for general-purpose computing and have fewer cores than GPUs. This design limits their ability to perform the parallel processing that’s essential for efficiently handling the large-scale matrix operations common in machine learning.
Energy efficiency and scalability
CPUs tend to consume more energy per computation compared to specialized hardware.
Memory and specialized acceleration
CPUs can face memory bandwidth limitations, potentially causing bottlenecks that affect the performance of data-intensive models. And unlike some GPUs, CPUs don’t have dedicated hardware for specific machine learning operations
8.2.2. GPU hardware#
With their parallel processing capabilities, GPUs are the go-to choice for models like convolutional neural networks (CNNs) and recurrent neural networks (RNNs). Owing to their origins in graphics rendering, they also excel in tasks related to image and video processing, driving applications in computer vision and video analytics.
While GPUs are highly effective for machine learning inference—particularly for tasks that benefit from parallel processing—they have certain limitations.
Cost and power consumption
High-performance GPUs come with a significant price tag compared to CPU (NVIDIA H100 40k€ in 2024)
Memory and technical complexity
Compared to system RAM, GPUs often have limited memory, which can pose challenges when working with large models or datasets.
Deployment and performance concerns
In multi-user or shared environments, contention for GPU resources can result in performance reductions
8.2.3. Multi-threading computing#
Multi-threading is a technique that allows a CPU to execute multiple threads concurrently, which can improve the performance of applications by parallelizing tasks.
Thread: A thread is the smallest unit of processing that can be scheduled by an operating system. It represents a single sequence of instructions within a program.
Multi-threading: This involves creating and managing multiple threads within a single process, enabling parallel execution of tasks.
Concurrency: Multi-threading allows multiple threads to make progress concurrently. This doesn’t necessarily mean they run at the same exact time (parallelism), but they can be interleaved on a single CPU core or run simultaneously on multiple cores.
Parallelism: When threads run literally at the same time on multiple CPU cores, this is parallelism. Parallelism is a subset of concurrency where tasks are truly executed in parallel.
Benefits:
Responsiveness: Multi-threading can keep an application responsive, especially in user interfaces.
Resource Sharing: Threads within the same process share resources like memory, which can be more efficient than using separate processes.
Efficiency: Can lead to better CPU utilization by keeping multiple threads busy while others are waiting for I/O operations.
Challenges:
Synchronization: Ensuring that threads don’t interfere with each other when accessing shared resources. This can involve using locks, semaphores, or other synchronization mechanisms.
Deadlock: A situation where two or more threads are blocked forever, waiting for each other to release resources.
Context Switching: Switching between threads has overhead, and too much context switching can negate the performance benefits.
Applications: Multi-threading is used in various applications like web servers (handling multiple requests simultaneously), gaming (handling rendering, physics, AI concurrently), and any computational tasks that can be broken down into smaller, parallelizable tasks.
In summary, multi-threading is a powerful technique for improving the performance and responsiveness of applications by allowing multiple threads to execute concurrently, but it requires careful management to avoid issues like race conditions and deadlocks.
8.2.4. Parallel computing#
Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time.
Parallel computing involves the simultaneous use of multiple compute resources to solve a computational problem. This can include using multiple CPU cores, multiple CPUs, or even multiple machines.
Granularity: The size of the tasks into which a problem is divided determines the granularity of parallelism:
Fine-grained parallelism: Tasks are small and require frequent communication between them.
Coarse-grained parallelism: Tasks are larger and involve less frequent communication.
Types of Parallelism:
Data Parallelism: Distributes data across different parallel computing nodes. Each node performs the same task on different pieces of distributed data.
Task Parallelism: Distributes tasks (or threads) across different nodes. Each node performs a different task on the same or different data.
Architectures:
Shared Memory Architecture: Multiple processors access the same memory space. Threads running on different processors can communicate by reading and writing to shared variables.
Distributed Memory Architecture: Each processor has its own private memory. Processors communicate by passing messages to each other.
Models of Parallel Computing:
Single Instruction, Multiple Data (SIMD): One instruction operates on multiple data points simultaneously.
Multiple Instruction, Multiple Data (MIMD): Different instructions operate on different data points at the same time.
Advantages:
Speed: Can significantly reduce the time required to solve complex problems.
Efficiency: Better utilization of available resources.
Scalability: Can handle larger problems as more compute resources are added.
Challenges:
Synchronization: Ensuring that all parallel tasks are coordinated.
Communication Overhead: The time required for tasks to communicate with each other can become significant.
Load Balancing: Distributing the tasks so that all processors are used efficiently.
Debugging and Testing: More complex than with serial programs due to the concurrency of operations.
Applications:
Scientific Simulations: Weather forecasting, climate modeling, physics simulations.
Data Analysis: Big data processing, machine learning, bioinformatics.
Engineering: Computer-aided design, computational fluid dynamics.
Entertainment: Rendering graphics for movies, real-time video game physics and graphics.
In summary, parallel computing leverages multiple processing elements simultaneously to solve problems more quickly and efficiently. It’s fundamental in modern computing, enabling tasks ranging from everyday applications to high-performance scientific computations.
8.2.5. HPC Centers#
Jupiter Exascale Supercomputer \(10^{18} \mbox{ flops}\) (German-French consortium EuroHPC)

JEDI (Jupiter dvt system) 125 compute nodes (each with 24 individual computers) with 24 000 Nvidia GH200 GPU interconnect with infiniband networking, consumption \(\approx 11\) Megawatts
CCD Doua: regional data center at University Claude Bernard Lyon with HPC capabilities
HPC very efficient consumption
Highly optimized cooling of the computing rack
Power usage effectiveness (PUE)
HPC: \(\mbox{PUE} \approx 1.2-1.3\)
Workstation: \(\mbox{PUE} > 2.5 - 3 \)
PC: \(\mbox{PUE} > 2\)
Jupyter nbgrader servers:
94 cores, 256 GB ram, 175 GB disk, 2000 users (students L1-L3): 250 W
Desktop PC in computer lab:
8 cores 16 GB RAM: 200 W
Summary
Using shared computers located in data-center is much more energy efficient than using personal computer for computing intensive task!!
but it needs:
Good Networking access
Sharing of the resources:
In multi-user or shared environments, contention for CPU/GPU resources can result in performance reductions
8.3. Using AI library efficiently#
8.3.1. importance of the type of hardware#
# executer la commande
#!nvidia-smi
# dans un terminal en continu
# nvidia-smi -l
8.3.2. Tensorflow#
Test TensorFlow with GPU
Using cuda with cupy (Python Cuda)
Test CuPy (CUDA Python versus numpy)
CuPy.ipynb
8.3.3. Torch#
PyTorch with GPU
8.4. Modele IA de balistique#
IAprojectile.ipynb
8.5. Problem on multiuser system#
Presentation JCAD
8.6. Modélisation du pendule double#
Modele pendule double
optimisation CPU
optimisation GPU