3.5. TensorFlow LSTM#
Marc Buffat, dpt mécanique, Lyon 1
prédiction d’un signal périodique (sinus) par machine learning avec RNN Tensorflow
3.5.1. Configuration pour l’utilisation d’un GPU avec tensorflow#
Par défaut, la bibliothèque Tensorflow optimisée pour GPU utilise un GPU par défaut, mais en réservant toute la mémoire du GPU.
Pour l’utiliser efficacement dans un contexte de partage de ressources, il faut :
sélectionner le numéro du GPU (0 ou 1) que l’on veut utiliser en répartissant les utilisateurs sur les 2 GPU. On choisit dans notre cas le GPU 1 (i.e. le second GPU)
sélectionner la mémoire maximale que l’on utilise sur le GPU en Mo. Dans notre cas, on choisit d’allouer 2 Go de RAM sur le GPU
La commande suivante vérifie la configuration des GPU et sélectionne le GPU 1 avec 2Go de RAM (2x1024 Mo)
!nvidia-smi
from validation.libIA_GPU import Init_tensorflowGPU
gpu = Init_tensorflowGPU(2*1024, 1)
# test GPU
!nvidia-smi
Thu Feb 13 14:03:09 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100 80GB PCIe On | 00000000:09:00.0 Off | 0 |
| N/A 36C P0 65W / 300W | 1889MiB / 81920MiB | 18% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA A100 80GB PCIe On | 00000000:0A:00.0 Off | 0 |
| N/A 33C P0 43W / 300W | 4MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 406952 C .../jupyterhub/venvs/torch/bin/python3 1880MiB |
+-----------------------------------------------------------------------------------------+
# configuration pour l'utilisation du GPU
from validation.libIA_GPU import Init_tensorflowGPU
gpu = Init_tensorflowGPU(2*1024, 1)
print(gpu)
2025-02-13 14:03:10.493415: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-02-13 14:03:11.859297: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Num GPUs Available: 2
GPU select: PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU') Mem GPU: 2048 Mo
PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU')
3.5.2. Bibliothèque et définition du modèle#
%matplotlib inline
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import Dense
import matplotlib.pyplot as plt
# définition du modele
# nbre de pas / sequence (optimal a partir de 20, trop faible pour 15 et 10
n_steps = 30
model = Sequential()
model.add(LSTM(10, activation='tanh'))
model.add(Dense(1, activation='tanh'))
model.compile(optimizer='adam', loss='mse')
2025-02-13 14:03:14.593496: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1928] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 2048 MB memory: -> device: 1, name: NVIDIA A100 80GB PCIe, pci bus id: 0000:0a:00.0, compute capability: 8.0
# preparation des donnéees
def train_function(x):
return np.sin(x)
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + n_steps
if end_ix > len(sequence)-1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
# define input sequence
xaxis = np.arange(-50*np.pi, 50*np.pi, 0.1)
train_seq = train_function(xaxis)
print("train function : ",train_seq.shape, n_steps)
# donnée 20 valeurs avant dans X pour predire la valeur de y
X, y = split_sequence(train_seq, n_steps)
# reshape from [samples, timesteps] into [samples, timesteps, features]
n_features = 1
X = X.reshape((X.shape[0], X.shape[1], n_features))
print("X.shape = {}".format(X.shape))
print("y.shape = {}".format(y.shape))
train function : (3142,) 30
X.shape = (3112, 30, 1)
y.shape = (3112,)
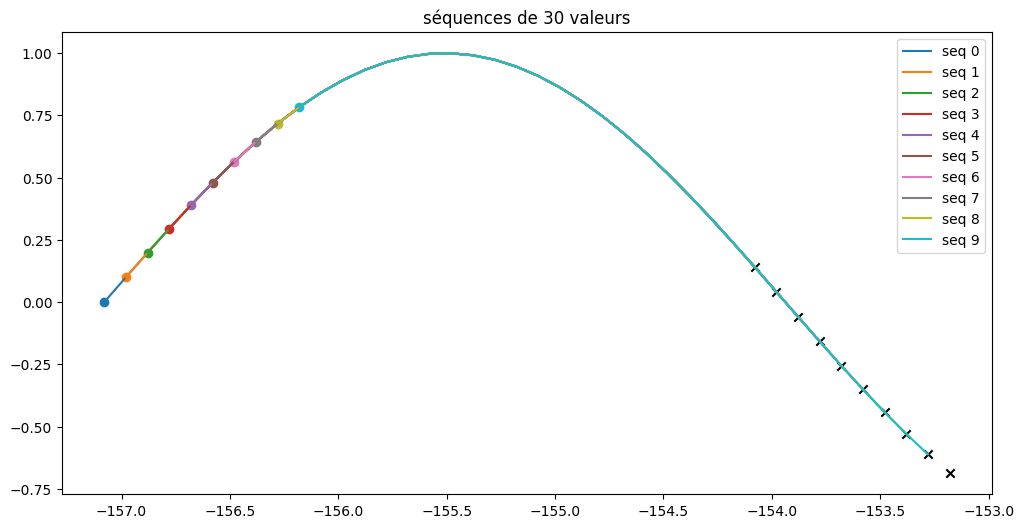
plt.figure(figsize=(12,6))
for i in range(10):
plt.scatter(xaxis[i],X[i,0,0])
plt.plot(xaxis[i:i+n_steps],X[i,:,0],label=f"seq {i}")
plt.scatter(xaxis[i+n_steps],y[i],marker='x',c='k')
plt.title(f"séquences de {n_steps} valeurs")
plt.legend();
3.5.3. Entraînement du modèle#
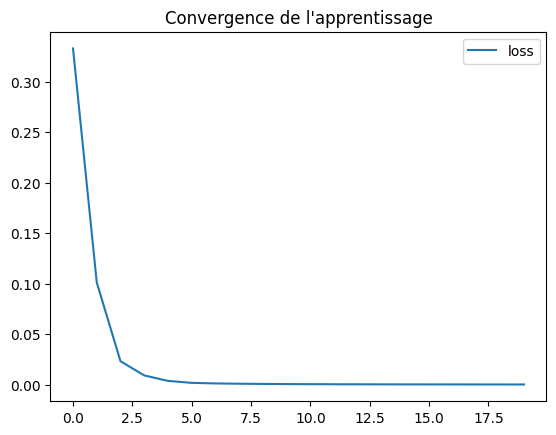
# train the model with 20 epochs
history = model.fit(X, y, epochs=20, verbose=0)
plt.plot(history.history['loss'], label="loss")
plt.legend(loc="upper right")
plt.title("Convergence de l'apprentissage")
plt.show()
2025-02-13 14:03:16.576195: I external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:465] Loaded cuDNN version 8907
3.5.4. Validation du modèle#
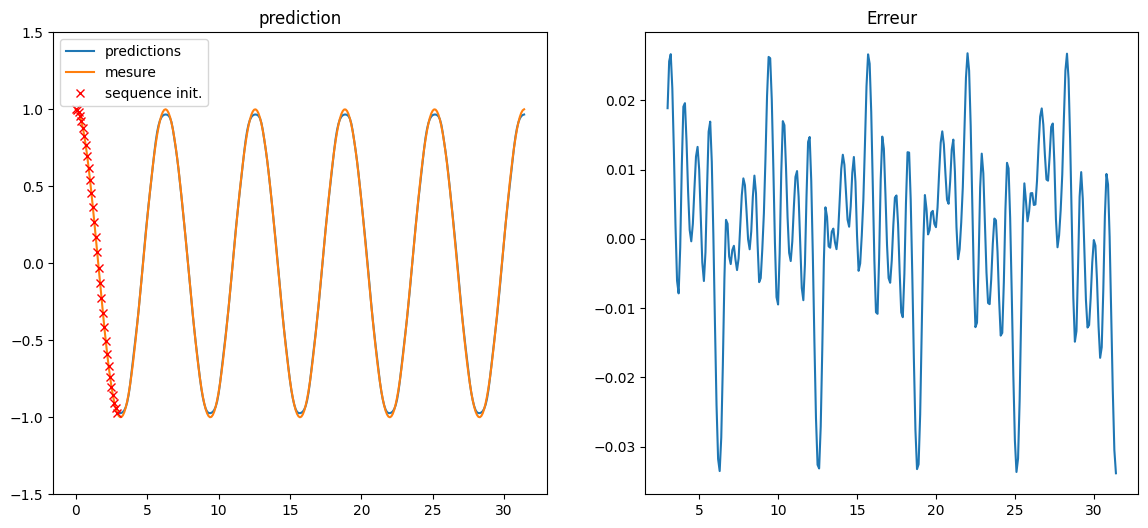
# test du model
test_xaxis = np.arange(0, 10*np.pi, 0.1)
def test_function(x):
return np.cos(x)
calc_y = test_function(test_xaxis)
# start with initial n values, rest will be predicted
test_y = calc_y[:n_steps]
results = []
for i in range( len(test_xaxis) - n_steps ):
net_input = test_y[i : i + n_steps]
net_input = net_input.reshape((1, n_steps, n_features))
y = model.predict(net_input, verbose=0)
test_y = np.append(test_y, y)
print("nbre de sequences ",len(test_xaxis)-n_steps)
nbre de sequences 285
plt.figure(figsize=(14,6))
plt.subplot(1,2,1)
plt.plot(test_xaxis[n_steps:], test_y[n_steps:], label="predictions")
plt.plot(test_xaxis, calc_y, label="mesure")
plt.plot(test_xaxis[:n_steps], test_y[:n_steps], 'xr',label="sequence init.")
plt.legend(loc='upper left')
plt.ylim(-1.5, 1.5)
plt.title("prediction")
plt.subplot(1,2,2)
plt.plot(test_xaxis[n_steps:], test_y[n_steps:]-calc_y[n_steps:])
plt.title("Erreur");
3.5.5. FIN#
Attention : A la fin de l’exécution du notebook, les ressources allouées sur le GPU ne sont pas libérées automatiquement, même si on ferme le notebook. La commande nvidia-htop.py permet de le vérifier.
Il faut explicitement arrêter le notebook soit :
avec le menu
Fichier->Close and Shut Down Notebookouctrl+shift+Qsoit avec le bouton à gauche (carré) qui gère tous les noyaux de l’utilisateur en cours d’exécution
!nvidia-htop.py
Thu Feb 13 14:04:01 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100 80GB PCIe On | 00000000:09:00.0 Off | 0 |
| N/A 37C P0 64W / 300W | 1907MiB / 81920MiB | 13% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA A100 80GB PCIe On | 00000000:0A:00.0 Off | 0 |
| N/A 36C P0 65W / 300W | 2541MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
+------------------------------------------------------------------------------+
| GPU PID USER GPU MEM %CPU %MEM TIME COMMAND |
| 0 406952 marc.bu+ 1898MiB 86.0 0.3 01:59 /var/lib/jupyterhub/ |
| 1 407074 marc.bu+ 2532MiB 106 0.3 01:26 /var/lib/jupyterhub/ |
+------------------------------------------------------------------------------+