3.6. PyTorch LSTM#
Marc Buffat, dpt mécanique, Lyon 1
prédiction d’un signal périodique (sinus) par machine learning avec RNN pytorch
inspiré de towardsdatascience.com
3.6.1. Configuration pour l’utilisation d’un GPU avec tensorflow#
Par défaut, la bibliothèque pytorch optimisée pour GPU n’utilise pas le GPU par défaut, mais le CPU en multi-threading surs tous les coeurs disponibles.
Pour l’utiliser efficacement dans un contexte de partage de ressources, il faut :
Sélectionner le numéro du GPU (0 ou 1) que l’on veut utiliser en répartissant les utilisateurs sur les 2 GPU. On choisit dans notre cas le GPU 0 (i.e. le premier GPU)
Transférer explicitement les données vers le GPU et effectuer explicitement le calcul sur le GPU contrairement à TensorFlow. On n’a pas donc pas à explicitement allouer de la mémoire sur le GPU, mais il faut avoir une idée de la taille des données que l’on va transférer sur le gPU.
Définir le nombre de threads (coeurs CPU) que l’on veut utiliser pour les calculs hors GPU. On choisit ici d’allouer 4 coeurs CPU au maximum.
La commande suivante vérifie la configuration des GPU et sélectionne le GPU 0 et 4 coeurs CPU
!nvidia-smi
from validation.libIA_GPU import Init_torchGPU
cuda_dev = Init_torchGPU(4, 0)
Attention vous ne pouvez pas ré-exécuter la fonction Init_torchGPU sans avoir redémarrer le noyau.
!nvidia-smi
Thu Feb 13 14:02:20 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100 80GB PCIe On | 00000000:09:00.0 Off | 0 |
| N/A 35C P0 43W / 300W | 1MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA A100 80GB PCIe On | 00000000:0A:00.0 Off | 0 |
| N/A 33C P0 43W / 300W | 1MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
from validation.libIA_GPU import Init_torchGPU
cuda_dev = Init_torchGPU(4, 0)
print(cuda_dev)
Max threads : 80 / used threads 4
Torch CUDA GPU count: 2 GPU device used cuda:0 NVIDIA A100 80GB PCIe
cuda:0
3.6.2. Bibliothèque et définition du modèle#
Avec la valeur dans cuda_dev retournée par la fonction précédente Init_torchGPU, on obtient le CUDA device utilisé par pytorch, stocké dans la variable device que l’on utiliser pour sélectionner le GPU avec pytorch.
device = torch.device(cuda_dev)
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
torch.cuda.is_available()
device = torch.device(cuda_dev)
print("CUDA device: ",cuda_dev)
print("Torch CUDA device: ",device," threads:",torch.get_num_threads(),torch.get_num_interop_threads())
CUDA device: cuda:0
Torch CUDA device: cuda:0 threads: 4 4
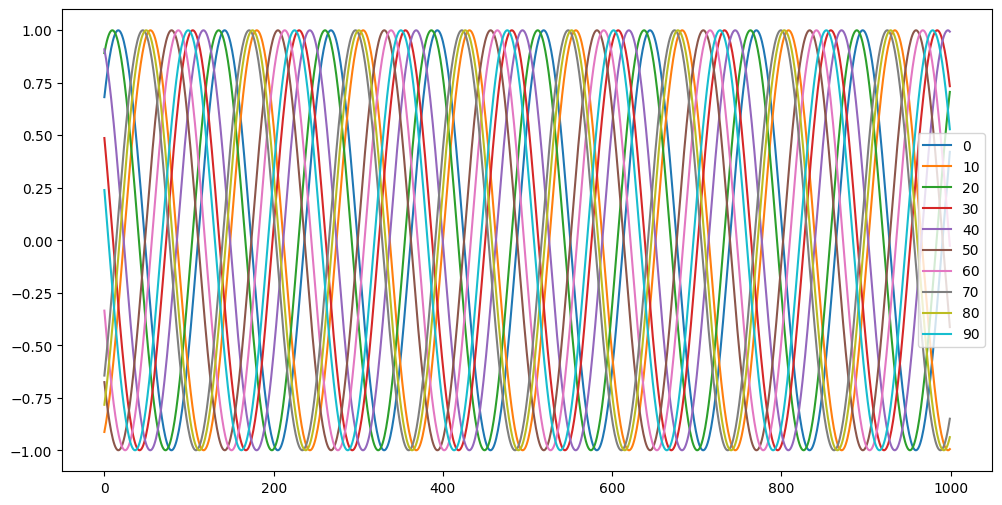
3.6.3. Génération des données#
100 courbes sinus de même fréquence et amplitude mais avec un déphasage
N = 100 # number of samples
L = 1000 # length of each sample (number of values for each sine wave)
T = 20 # width of the wave
x = np.zeros((N,L), np.float32)
for i in range(N):
x[i,:] = np.arange(L) + np.random.randint(-4*T, 4*T)
y = np.sin(x/1.0/T).astype(np.float32)
plt.figure(figsize=(12,6))
for i in range(0,N,10):
plt.plot(y[i,:],label=str(i))
plt.legend()
<matplotlib.legend.Legend at 0x7f3f497afdf0>
3.6.4. Construction du modèle LSTM#
Définition du réseau
Modèle: réseau RNN de type LSTM
Entrée dim=1
2 layers lstm: 1x64 et 64x64
1 layer linear: 64x1
Sortie dim=1
Phase de prédiction (forward)
Dans la méthode directe, une fois que les couches individuelles du LSTM ont été instanciées avec les tailles correctes, nous pouvons commencer à nous concentrer sur les entrées réelles dans le réseau. Une cellule LSTM prend les entrées suivantes : entrée, (h_0, c_0).
input : un tenseur d’entrées de taille (batch, input_size), où nous avons déclaré input_size lors de la création de la cellule LSTM.
h_0 : un tenseur contenant l’état caché initial pour chaque élément du lot (batch), de taille (batch, hidden_size).
c_0 : un tenseur contenant l’état initial de la cellule pour chaque élément du lot (batch), de taille (batch, hidden_size).
Pour relier les deux cellules LSTM (et la deuxième cellule LSTM avec la couche linéaire entièrement connectée), nous devons également savoir ce qu’une cellule LSTM produit réellement : un tenseur de forme (h_1, c_1).
h_1 : un tenseur contenant le prochain état caché pour chaque élément du lot (batch), de taille (batch, hidden_size).
c_1 : un tenseur contenant le prochain état de cellule pour chaque élément du lot (batch), de taille (batch, hidden_size).
Dans notre cas la taille du lot est batch=100 (1ere dimension de l’entrée input)
Mise en place du modèle LSTM avec torch
On construit le modèle LSTM en définissant une classe de type torch Module, qui est la classe de base de pytorch pour définir un réseau de neuronnes (documentation pytorch).
Explicitement, dans ce modèle, on indique que les variables du modèle doivent être transférées sur le GPU en utilisant la méthode
.to(device)
class LSTM(nn.Module):
def __init__(self, hidden_layers=64):
super(LSTM, self).__init__()
self.hidden_layers = hidden_layers
# lstm1, lstm2, linear are all layers in the network
self.lstm1 = nn.LSTMCell(1, self.hidden_layers).to(device)
self.lstm2 = nn.LSTMCell(self.hidden_layers, self.hidden_layers).to(device)
self.linear = nn.Linear(self.hidden_layers, 1).to(device)
def forward(self, y, future_preds=0):
outputs, n_samples = [], y.size(0)
h_t = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32).to(device)
c_t = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32).to(device)
h_t2 = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32).to(device)
c_t2 = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32).to(device)
for input_t in y.split(1, dim=1):
# N, 1
h_t, c_t = self.lstm1(input_t, (h_t, c_t)) # initial hidden and cell states
h_t2, c_t2 = self.lstm2(h_t, (h_t2, c_t2)) # new hidden and cell states
output = self.linear(h_t2) # output from the last FC layer
outputs.append(output)
for i in range(future_preds):
# this only generates future predictions if we pass in future_preds>0
# mirrors the code above, using last output/prediction as input
h_t, c_t = self.lstm1(output, (h_t, c_t))
h_t2, c_t2 = self.lstm2(h_t, (h_t2, c_t2))
output = self.linear(h_t2)
outputs.append(output)
# transform list to tensor
outputs = torch.cat(outputs, dim=1)
return outputs
3.6.5. Phase d’entraînement#
on choisit les dernières 97 courbes pour l’entraînement et les 3 premières pour les tests
# training data input L-1
train_input = torch.from_numpy(y[3:, :-1]) # (97, 999)
train_target = torch.from_numpy(y[3:, 1:]) # (97, 999)
# test
test_input = torch.from_numpy(y[:3, :-1]) # (3, 999)
test_target = torch.from_numpy(y[:3, 1:]) # (3, 999)
print("Train CUDA : N={} L={} cuda={} {}".format(N,L,train_input.is_cuda, train_target.is_cuda))
Train CUDA : N=100 L=1000 cuda=False False
train_input = train_input.to(device)
train_target = train_target.to(device)
test_input = test_input.to(device)
test_target = test_target.to(device)
print("Train CUDA : N={} L={} cuda={} {}".format(N,L,train_input.is_cuda, train_target.is_cuda))
Train CUDA : N=100 L=1000 cuda=True True
model = LSTM()
criterion = nn.MSELoss()
optimiser = torch.optim.LBFGS(model.parameters(), lr=0.08)
import time
def training_loop(n_epochs, model, optimiser, loss_fn,
train_input, train_target, test_input, test_target):
for i in range(n_epochs):
start = time.perf_counter()
def closure():
optimiser.zero_grad()
out = model(train_input)
loss = loss_fn(out, train_target)
loss.backward()
return loss
optimiser.step(closure)
with torch.no_grad():
future = 1000
pred = model(test_input, future_preds=future)
# use all pred samples, but only go to 999
loss = loss_fn(pred[:, :-future], test_target)
y = pred.detach().cpu().numpy()
# print the loss
out = model(train_input)
loss_print = loss_fn(out, train_target)
tcpu = time.perf_counter()-start
print("Step: {}, Loss: {} tcpu={:.3f} s".format(i, loss_print,tcpu))
# draw figures
plt.figure(figsize=(12,6))
plt.title(f"Step {i+1}")
plt.xlabel("x")
plt.ylabel("y")
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
n = train_input.shape[1] # 999
def draw(yi, colour):
plt.plot(np.arange(n), yi[:n], colour, linewidth=2.0)
plt.plot(np.arange(n, n+future), yi[n:], colour+":", linewidth=2.0)
draw(y[0], 'r')
draw(y[1], 'b')
draw(y[2], 'g')
plt.savefig("predict%d.png"%i, dpi=200)
plt.close()
# Phase d'entrainement
Nepochs=10
training_loop(Nepochs,model,optimiser,criterion,train_input, train_target, test_input, test_target)
Step: 0, Loss: 0.033405572175979614 tcpu=23.835 s
Step: 1, Loss: 0.01707189716398716 tcpu=24.301 s
Step: 2, Loss: 0.008241494186222553 tcpu=22.685 s
Step: 3, Loss: 0.001806470681913197 tcpu=20.623 s
Step: 4, Loss: 0.000917300465516746 tcpu=23.598 s
Step: 5, Loss: 0.0005174727994017303 tcpu=24.210 s
Step: 6, Loss: 0.0003372530045453459 tcpu=24.073 s
Step: 7, Loss: 0.00026835378957912326 tcpu=24.136 s
Step: 8, Loss: 0.00017204898176714778 tcpu=24.176 s
Step: 9, Loss: 0.0001305166952079162 tcpu=23.052 s
3.6.6. Prédictions#
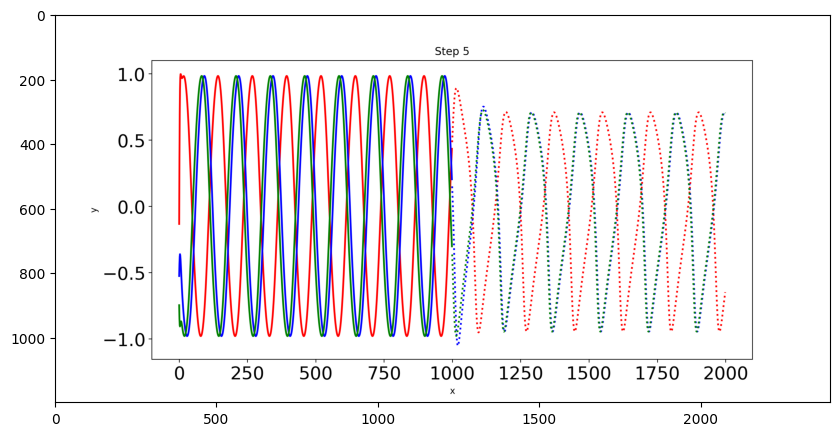
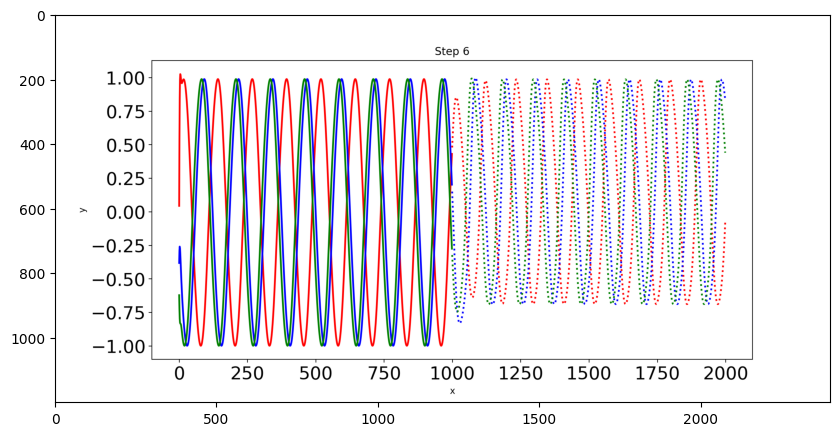
Il n’y a que trois courbes sinusoïdales de test et nous dessinerons chaque courbe dans une couleur différente. Les lignes pointillées indiquent les prévisions futures et les lignes pleines indiquent les prévisions dans la plage actuelle des données.
from PIL import Image
img = np.asarray(Image.open('predict1.png'))
plt.figure(figsize=(10,6))
plt.imshow(img)
<matplotlib.image.AxesImage at 0x7f3ecd89eaf0>
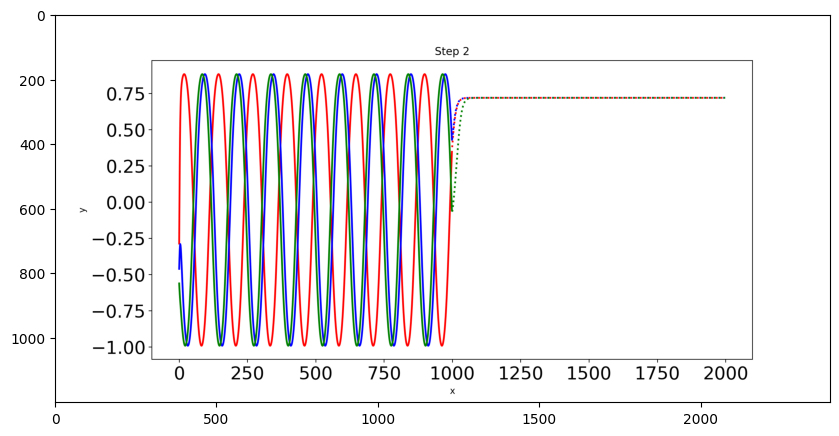
img = np.asarray(Image.open('predict4.png'))
plt.figure(figsize=(10,6))
plt.imshow(img)
<matplotlib.image.AxesImage at 0x7f3ecd9f7d90>
img = np.asarray(Image.open('predict5.png'))
plt.figure(figsize=(10,6))
plt.imshow(img)
<matplotlib.image.AxesImage at 0x7f3ecd8c1fa0>
img = np.asarray(Image.open('predict6.png'))
plt.figure(figsize=(10,6))
plt.imshow(img)
<matplotlib.image.AxesImage at 0x7f3ecd83d730>
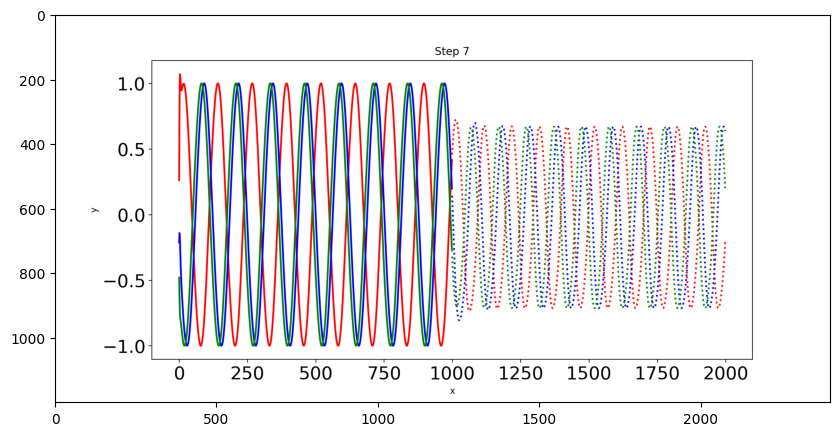
img = np.asarray(Image.open('predict9.png'))
plt.figure(figsize=(10,6))
plt.imshow(img)
<matplotlib.image.AxesImage at 0x7f3ecd7aba30>
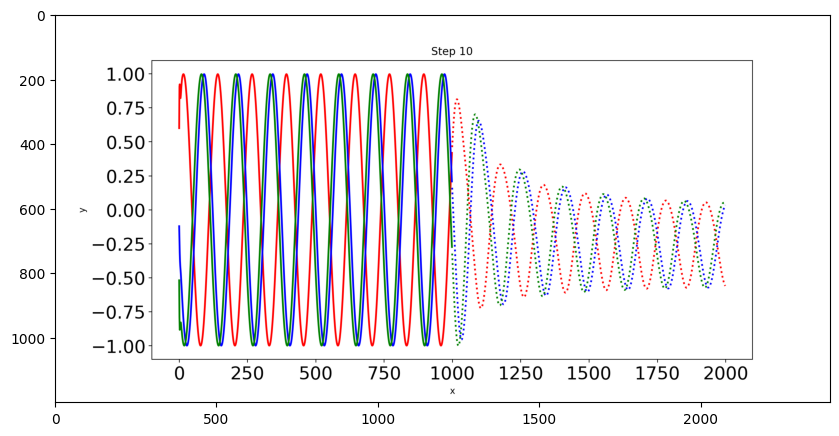
3.6.7. Applications#
on utilise le modèle précédent pour prédire une fonction périodique :
On utilise la méthode .cpu() pour transférer les données du GPU au CPU pour pouvoir les manipuler (i.e. les tracer)
N = np.random.randint(50, 200) # number of samples
L = np.random.randint(800, 1200) # length of each sample (number of values for each sine wave)
T = np.random.randint(10, 30) # width of the wave
x = np.empty((N,L), np.float32) # instantiate empty array
x[:] = np.arange(L) + np.random.randint(-4*T, 4*T, N).reshape(N,1)
y = np.cos(np.sin(x/1.0/T)**2).astype(np.float32)
plt.plot(y[2,:]);
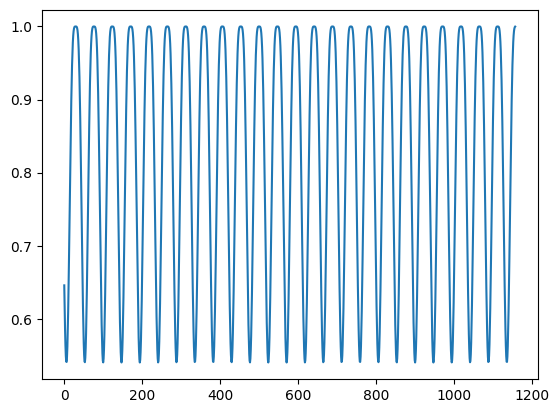
train_prop = 0.95
train_samples = round(N * train_prop)
test_samples = N - train_samples
#y = np.zeros((N, L))
print(N,L,y.shape)
train_input = torch.from_numpy(y[test_samples:, :-1]) # (train_samples, L-1)
train_target = torch.from_numpy(y[test_samples:, 1:]) # (train_samples, L-1)
test_input = torch.from_numpy(y[:test_samples, :-1]) # (train_samples, L-1)
test_target = torch.from_numpy(y[:test_samples, 1:]) # (train_samples, L-1)
137 1159 (137, 1159)
plt.plot(test_input[0,:].cpu(), label='test')
plt.plot(test_target[0,:].cpu(), label='pred.')
plt.legend();
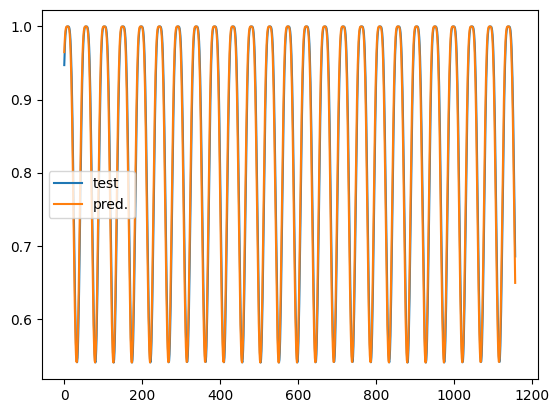
3.6.8. END#
Attention : A la fin de l’exécution du notebook, les ressources allouées sur le GPU ne sont pas libérées automatiquement, même si on ferme le notebook. La commande nvidia-htop.py permet de le vérifier.
Il faut explicitement arrêter le notebook soit :
avec le menu
Fichier->Close and Shut Down Notebookouctrl+shift+Qsoit avec le bouton à gauche (carré) qui gère tous les noyaux de l’utilisateur en cours d’exécution
!nvidia-htop.py
Thu Feb 13 14:06:26 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100 80GB PCIe On | 00000000:09:00.0 Off | 0 |
| N/A 37C P0 62W / 300W | 1915MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA A100 80GB PCIe On | 00000000:0A:00.0 Off | 0 |
| N/A 38C P0 67W / 300W | 2541MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
+------------------------------------------------------------------------------+
| GPU PID USER GPU MEM %CPU %MEM TIME COMMAND |
| 0 406952 marc.bu+ 1906MiB 93.5 0.3 04:24 /var/lib/jupyterhub/ |
| 1 407074 marc.bu+ 2532MiB 39.8 0.3 03:52 /var/lib/jupyterhub/ |
+------------------------------------------------------------------------------+