contrôle continu (poids 1/3)
un QCM de 12 questions par jour.
La note de contrôle continu ne baisse pas la note de l'UE
par contre pour 70% des étudiants elle l'augmente.
examen final papier (poids 2/3) avec une session 2 en juin/juillet
sur ce que vous avez fait avec MUNIX
Pour pouvoir aborder cette UE en toute sérénité,
il est nécessaire d'avoir quelques compétences préalables.
Être capable de comprendre des phrases compliquées comme :
«C'est le mari de la fille ainée de la soeur du père de ton frère.»
et d'en déduire qu'il n'y a qu'une seule tante, un seul frère et plusieurs cousines.
Savoir lire l'anglais.
Savoir utiliser une clavier d'ordinateur, notamment les touches :
Tab «↹»
pour naviguer dans les zones de saisie.
Entrée «⏎»
pour terminer la saisie.
Début «↖»
pour aller au début de la ligne ou du document.
Fin
pour aller à la fin de la ligne ou du document.
Page précédente «⇞»
Page suivante «⇟»
Backspace «espace arrière»
pour détruire le caractère à gauche du curseur.
Suppr
pour détruire le caractère à droite du curseur.
Shift «⇧»
à ne pas confondre avec verrouillage majuscule que
vous ne devez "jamais" utiliser.
Elle permet aussi de faire des sélections sans la souris.
Contrôle «Ctrl»
qui s'utilise comme Shift mais
qui change la signification des touches pressées.
Copier coller : «Ctrl+C» «Ctrl+V» «Ctrl+X».
Changer d'onglet : «Ctrl+⇞» et «Ctrl+⇟».
Undo : «Ctrl+Z»
Déplacement de mot en mot : «Ctrl+→» et «Ctrl+←».
Destruction du mot suivant «Ctrl+Supr» ou précédent «Ctrl+Backspace».
Alt
pour utiliser les menus des applications
ou de faire «Alt+Tab» pour changer de fenêtre.
AltGr
pour taper le caractère en bas à droite de la touche.
Il y a une unique séance de cours présentant l'organisation de l'UE,
faisant une démonstration des différents outils,
donnant des conseils pour l'apprentissage
et vous indiquant comment ne pas perdre trop de temps.
Le support de cours est uniquement pour vous aider à réviser.
Pour préparer l'UE il suffit de faire les TP MUNIX.
Le support de cours HTML contenant
la concaténation des cours des différents modules «MUNIX».
Avant d'imprimer (ce qui est une mauvaise idée),
vérifiez sur l'aperçu d'impression que les textes et images
ne sont pas tronqués.
La présence aux séances de TP n'est pas obligatoire.
Vous n'avez pas besoin de dispense d'assiduité.
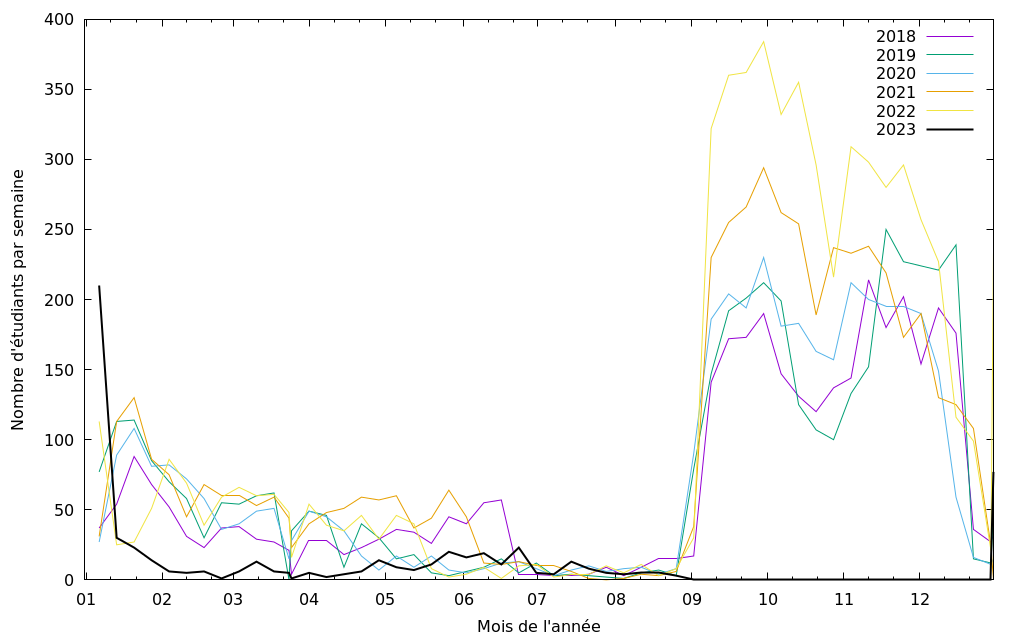
Les TP sont tous les jours de 13h à 14h.
MUNIX est une application en ligne vous permettra d'apprendre et vous entraîner
tout au long du semestre (la note de l'UE ne tient pas compte
du travail fait dans MUNIX), elle restera à votre disposition
dans la suite de votre scolarité de licence en master.
Cliquez sur le premier module pour démarrer :
Relire le cours du
Module 1
puis essayez d'obtenir 4 étoiles.
Il faut cliquer sur «Autre question» puis «Autre version» afin
de compléter le bord du disque.
Examen terminal papier portant sur le contenu de MUNIX début janvier.
La session 2 est fin juin/début juillet.
MUNIX
MUNIX contient le cours et les TP.
Votre objectif est d'obtenir 4 étoiles à chaque module
afin d'avoir une chance d'obtenir la moyenne à l'examen terminal.
Chaque module utilise les connaissances acquises dans les modules
précédents, il peut être nécessaire de retravailler les premiers
modules si vous êtes bloqué.
Toutes les informations nécessaires sont indiquées dans l'application,
vous risquez de vous éloigner de la bonne réponse si vous cherchez
sur le web.
Si vous êtes bloqué sur une question, expliquez votre problème
dans le champ commentaire de MUNIX en bas à gauche et envoyez-le.
Je recevrais alors un mail avec la question et vos différents
essais, je pourrais alors facilement vous aider.
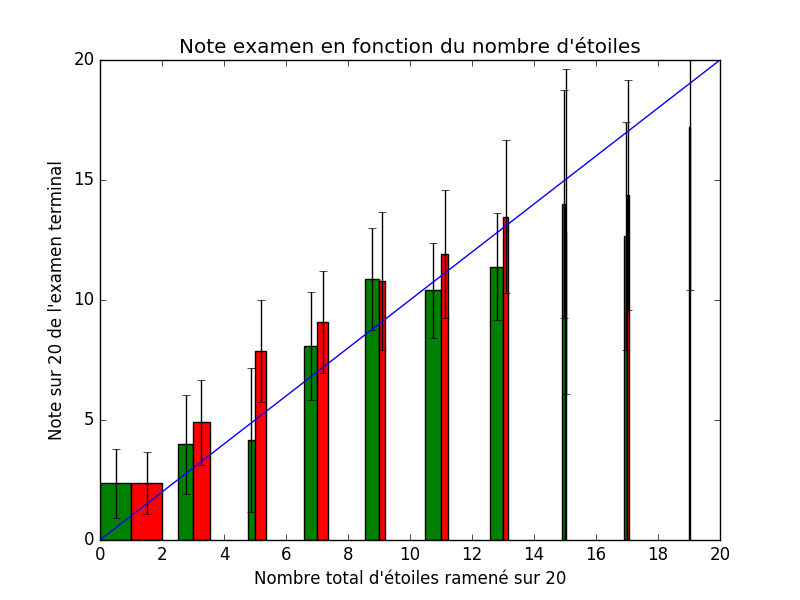
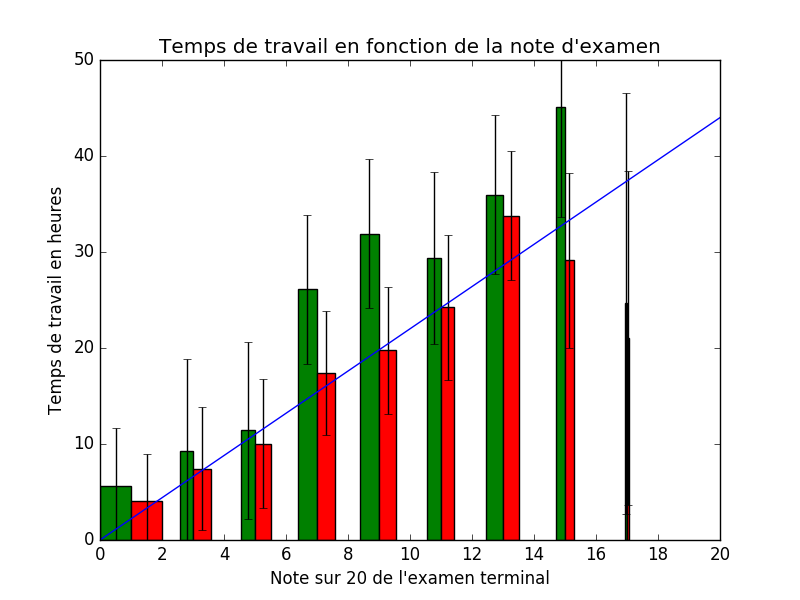
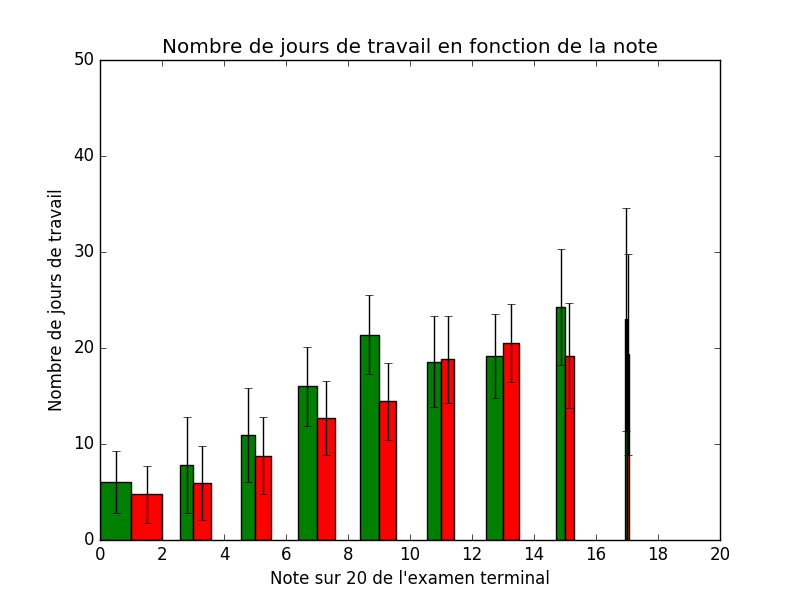
La médiane du temps de travail pour obtenir 4 étoiles est de 10 heures
pour chacun des modules, attention, ¼ des étudiants mettent plus
de 15 heures pour obtenir les 4 étoiles pour un seul module.
Détails des statistiques.
Attention ces TP nécessitent beaucoup de concentration,
et sont donc très fatiguants, il est donc recommandé de travailler
régulièrement chaque jour car il ne faut pas espérer réussir
à rester concentré 8 heures dans la même journée.
Votre progression est affichée dans
TOMUSS
chaque jour afin que votre
enseignant référent puisse voir que vous travaillez régulièrement.
La note de l'UE ne tient pas du tout compte du temps
passé ni du nombre d'étoiles obtenues sur MUNIX.
La notation de cette UE commence dès le lundi de la deuxième semaine de cours,
avec le QCM
qui vous posera des questions tous les jours jusqu'aux vacances de Noël.
Ce qui est affiché dans TOMUSS n'est pas mis à jour instantanément,
il faut attendre le lendemain.
La note de l'UE est la moyenne pondérée de :
Type
Poids
Contrôle continu
1/3
Un
QCM
avec 12 questions par jour, si vous ne répondez pas
dans les temps vous avez 0 à la question.
Vous répondez quand vous voulez.
Toute tricherie sera punie.
Si cette note est plus faible que celle de l'examen terminal
alors elle ne sera pas comptée.
Examen terminal
2/3
Examen papier portant exclusivement sur MUNIX
avec une deuxième session.
Pour cette UE de manière expérimentale, la deuxième session ne baissera
pas la note de première session.
L'examen terminal sera un QCM papier à points négatifs avec environ 60 questions
et de très nombreux choix,
il durera 1 heure et sera sans documents.
C'est une épreuve de vitesse, qui ne pourra
être réussie que si vous pratiquez le shell tous les jours
pour tous vos travaux sur machine.
Attention :
Cela prend trop de temps de trouver la bonne réponse par élimination
des mauvaises réponses car il y en a trop.
Il est bien plus rapide d'imaginer la bonne réponse dans
sa tête et de la chercher parmi les réponses possibles.
Entre la dernière séance de TP et l'examen
il ne sera répondu à aucune question concernant le contenu
de l'UE. C'est au début de l'UE qu'il faut travailler,
pas après la fin.
Voici les notes obtenues aux examens passés.
Ne prenez pas peur en regardant ces chiffres car ils comptabilisent
tous les étudiants.
Et comme 50% des étudiants ont passé moins de 10 heures à préparer l'UE,
ils se retrouvent avec 0 ou 1/20 à l'examen ce qui fait baisser
la moyenne.
La moyenne à l'examen terminal des étudiants travaillant
entre 30 et 50 heures sur MUNIX est de 13/20.
Tout d'abord, si vous avez un ordinateur vieux de 10 ans
c'est le moment de le ressortir du placard pour installer Linux dessus.
Si la machine à 2Go de RAM et a un processeur 64 bits je vous conseille Lubuntu.
Si elle a moins, alors essayez «Puppy Linux» (je ne l'ai pas personnellement installé).
Petit lexique :
OS (Operating System)
: ce qui vous permet d'utiliser votre ordinateur
Unix, Windows... : des OS
Linux, FreeBSD, NetBSD, MacOS, Minix, Hurd... : des noyaux Unix
Fedora, Debian, Ubuntu... : des distributions Linux,
c'est-à-dire le noyau et des applications.
Machine virtuelle
: une application qui simule une machine physique,
pour faire croire à un logiciel qu'il s'exécute tout seul sur un vrai
ordinateur.
Voici quelques choix qui s'offrent à vous pour accéder à Unix :
Ordi en salle de TP Linux
Il faut être à la fac.
Choisir Fedora au démarrage en utilisant le clavier.
Votre ordi Votre navigateur web Internet https://shell.univ-lyon1.fr/
Il faut Internet.Indiquer l'adresse web
https://shell.univ-lyon1.fr/ à votre navigateur
et vous pourrez vous connecter sous Unix avec les identifiants
de l'université.
Attention cette machine est partagée par tous les étudiants,
donc si quelqu'un crée «/tmp/toto» les autres ne pourront pas
le modifier.
Votre ordi Votre OS Client SSH Internet Ordi linuxetu Linux
Il faut Internet.Installer un client SSH sur votre ordinateur.
Connectez-vous à linuxetu.univ-lyon1.fr avec votre login
p9999999 (la première lettre est en minuscule).
Si vous utilisez la commande ssh c'est :
ssh p9999999@linuxetu.univ-lyon1.fr
La première fois, acceptez la clef.
Lisez ce qui est affiché et taper : ssh shell.univ-lyon1.fr
Votre ordi Linux
Tous les changements sont perdus à chaque démarrage.
Démarrer votre ordinateur avec une clef USB contenant
un Linux Live.
Par exemple celui qui est dans les salles de TP :
Fedora
Votre ordi Linux
Il faut de la place disque. On risque de perdre des données.
Installer Linux sur votre ordinateur à coté de votre
système habituel après avoir vérifié que le Linux Live fonctionne,
notamment le wifi.
Votre ordi Windows WSL bash
Il faut une machine 64 bits. Il n'y a pas le graphique.
Sous Windows : installez et lancez
Windows Subsystem for Linux
Votre téléphone Android Linux
Il n'y a pas le graphique.
Sous Android installez « termux »
Vous avez accès à plus de 1000 applications Unix pour
programmer en langage C, en Python, Javascript...
Il est recommandé de connecter un vrai clavier à votre téléphone
qu'il soit bluetooth ou USB avec un connecteur OTG.
Votre ordi Votre OS Votre Navigateur Web Machine virtuelle Linux
Ne permet pas de répondre à toutes les questions. Très très lent. Il faut Internet
Cliquez sur JSLinux qui
est une mini distribution Linux qui fonctionne dans
le navigateur web.
Voici quelques méthodes permettant de travailler avec les fichiers
de l'université.
Pour toutes ses méthodes il faut accepter le certificat lors de la première
connexion et taper son mot de passe une ou plusieurs fois.
Vous ne pouvez plus travailler car vous avez atteint
la limite de votre espace de stockage.
Voici comment résoudre le problème.
Ce qui fonctionne pour faire rapidement de la place :
vous vider le cache du navigateur web.
Dans le menu du navigateur il y aura quelque chose du genre
«Delete browsing data» sinon allez dans les paramètres (ou configuration)
et cherchez «cache» pour pouvoir le vider.
Détruisez le contenu du répertoire téléchargement et de la poubelle.
Si cela n'a pas résolu votre problème, cherchez dans quel répertoire
il se trouve en tapant la commande «du -sh ~/* ~/.*»
ce qui vous donnera la taille occupée par chaque répertoire
(même caché) se trouvant à la racine de votre compte.
Vous pourrez alors détruire ce qui ne vous sert pas
en utilisant avec précaution la commande «rm»
N'oubliez pas de vérifier si un gros fichier n'est pas
à la racine de votre compte : «ls -l»
Les problèmes de quota sont souvent créés par les gros fichiers.
Pour trouver tous les fichiers de plus de 1 méga octet :
«find ~ -size +1024k -exec ls -sh {} +»
Voici des exemples de commandes shell que j'ai utilisées.
# Le 17/12/2017
# Le répertoire courant contient des fichiers PDF de une page
# nommés 0.pdf 1.pdf ... 42.pdf ...
# Le script shell génère un unique fichier PDF nommé 'merged_tops.pdf'
# contenant le haut de chacune des pages des PDF, sans changer l'ordre.
# Les commandes utilisées viennent des paquets :
# 'libjpeg-progs', 'poppler-utils' et 'imagemagick'
I=0
while [ -f $I.pdf ]
do
echo $I
pdfimages $I.pdf xxx
HEIGHT=$(pnmfile xxx-000.ppm | sed -r 's/.*by ([0-9]+).*/\1/')
pnmcut -bottom $(expr '(' 10 '*' $HEIGHT ')' / 100) \
xxx-000.ppm | cjpeg >$(printf 'xxxx-%04d.jpg' $I)
I=$(expr $I + 1)
done
convert xxxx-*.jpg merged_tops.pdf
rm xxx*
Ces projets nécessitent que vous ayez terminé tous les modules MUNIX.
Ils ne sont ni notés ni à rendre, c'est simplement pour vous donner
des exemples de choses que vous êtes maintenant capable de faire en quelques lignes.
La zone de droite de la table donne la réponse,
faites une sélection pour la voir.
Voici comment réaliser le projet en plusieurs étapes :
Commencez par faire un script qui affiche l'heure chaque fois
que le contenu du fichier «toto» change.
Vous appellerez «toto~» l'ancien contenu du fichier.
Pour ne pas surcharger la machine, regardez seulement
une fois par seconde s'il y a eu un changement
en utilisant sleep pour attendre.
Pour tester si le contenu de deux fichiers est identique,
utilisez la commande diff
Vous aurez aussi besoin de while, true, if, cp
while true
do
if ! diff toto toto~ >/dev/null 2>/dev/null
then
date
cp toto toto~
fi
sleep 1
done
Modifiez le script précédent pour conserver toutes
les versions différentes du fichier toto
Pour cela il suffit d'ajouter la bonne option à la commande cp
qui appellera alors les fichiers toto~.~1~toto~.~2~toto~.~3~toto~.~4~ ...
while true
do
if ! diff toto toto~ >/dev/null 2>/dev/null
then
date
cp --backup=numbered toto toto~
fi
sleep 1
done
Modifiez le script précédent pour recopier dans le fichier «toto»
le contenu de votre page web personnelle https://ma-page-web.mon-domaine.fr/
Pour récupérer le contenu du la page web, il suffit d'utiliser
la commande wget en lui donnant les bonnes options
pour qu'elle enregistre dans le fichier toto
Un message s'affichera donc chaque fois que la page web changera.
while true
do
wget https://www.univ-lyon1.fr/ -O toto 2>/dev/null
if ! diff toto toto~ >/dev/null 2>/dev/null
then
date
cp toto toto~
fi
sleep 60
done
Si votre fournisseur d'accès Internet vous donne une URL vous
permettant d'envoyer des SMS vous pouvez vous faire facilement
envoyer un SMS à chaque changement de la page que vous surveillez.
Voici comment réaliser le projet en plusieurs étapes :
Mettez vous dans un répertoire ne contenant que
le fichier PDF pour lequel vous voulez créer l'index
avec des vignettes.
Les vignettes seront affichées en 10 DPI (Dot Per Inch)
et donc toute petites.
Un écran classique est en 100 DPI et une imprimante en 300 DPI
Lancer la commande pdftoppm avec les bons paramètres
afin de créer les fichiers xxx-01.pngxxx-02.pngxxx-02.png qui représenteront
chacun une page du document PDF.
pdftoppm -png -r 10 *.pdf xxx
Générez la page web en créant un fichier index.html contenant :
<img src="xxx-01.png"><img src="xxx-02.png">
Vous faites une boucle !
Vous regardez le contenu de votre fichier en lançant : xdg-open index.html
for I in *.png
do
echo '<img src="'$I'">'
done >index.html
On veut maintenant que quand on clique sur l'image en petit
cela l'affiche en grand.
Pour cela :
Générez les images contenues dans le PDF en 100 DPI
et en les nommant grand-xxx au lieu de xxx
Générez la page web avec les liens de la forme :
<a href="grand-xxx-01.png"><img src="xxx-01.png"></a>
pdftoppm -png -r 100 *.pdf grand-xxx
for I in xxx*.png
do
echo '<a href="grand-'$I'"><img src="'$I'"></a>'
done >index.html
On suppose que les fichiers ont pu changer de nom.
Voici comment réaliser le projet en plusieurs étapes :
Faites afficher les chemins de tous les fichiers.
find . -type f
Ajouter une checksum du contenu du fichier devant son nom.
Pour calculer la checksum, faites une boucle while
et utilisez md5sum qui
donnera un nombre unique (on l'espère) pour chaque fichier.
find . -type f |
while read L
do
md5sum $L
done
Trier ce qui précède par checksum (ordre alphabétique classique)
find . -type f |
while read L
do
md5sum $L
done |
sort
Afficher seulement les lignes pour lesquelles le checksum n'est pas unique,
donc celles pour lesquelles le checksum suivant ou précédent est le même.
Il faut faire une boucle while, un if
et utiliser les variables suivantes : CHECKSUM,
FILENAME,
LAST_CHECKSUM,
LAST_FILENAME
Ce n'est pas grave s'il y a des lignes en double quand
le fichier est répété 3 fois.
Celui du milieu a un checksum identique au précédent et au suivant.
find . -type f |
while read L
do
md5sum $L
done |
sort |
while read CHECKSUM FILENAME
do
if [ "$CHECKSUM" = "$LAST_CHECKSUM" ]
then
echo "$LAST_CHECKSUM $LAST_FILENAME"
echo "$CHECKSUM $FILENAME"
fi
LAST_CHECKSUM=$CHECKSUM
LAST_FILENAME=$FILENAME
done
Continuez le pipeline en enlevant les lignes en double avec uniq
Faites une boucle while qui va créer des
fichier checksum.la-valeur-du-checksum qui contiendront
la liste des fichiers avec le même checksum.
uniq |
while read CHECKSUM FILENAME
do
echo "$FILENAME" >>checksum.$CHECKSUM
done
Dernière vérification : est-ce que les fichiers dont les noms
sont dans les fichiers checksum.???? sont bien identiques ?
Faites afficher les paires de noms de fichiers identiques
en comparant chacun des fichiers au premier de la liste avec
la commande cmp par exemple.
for I in checksum.*
do
(
read FIRST_FILENAME
while read FILENAME
do
if cmp "$FIRST_FILENAME" "$FILENAME"
then
echo "$FIRST_FILENAME === $FILENAME"
fi
done
) <$I
done
Vous utiliserez une boucle for parcourant char short int long float double
pour obtenir les noms des différents types.
(
echo 'using namespace std;
#include <iostream>
int main()
{
cout << "Tailles en octets :";'
for TYPE in char short int long float double
do
echo 'cout << " '$TYPE'=" << sizeof('$TYPE');'
done
echo 'cout << "\n";
}'
) >xxx.cpp
Ajoutez les types long int, long long, long double et char* à la liste
(
echo 'using namespace std;
#include <iostream>
int main()
{
cout << "Tailles en octets :";'
for TYPE in char short int long float double 'long int' 'long long' 'long double' 'char*'
do
echo 'cout << " '$TYPE'=" << sizeof('$TYPE');'
done
echo 'cout << "\n";
}'
) >xxx.cpp
Compilez xxx.cpp et exécutez le résultat seulement
si la compilation n'a pas fait d'erreur.
Le compilateur est g++
Pour trouver le fichier exécutable créé, il suffit de lancer
ls -lst pour afficher les fichiers triés par date.
Pour exécuter un fichier du répertoire courant il faut
indiquer le chemin en commençant par ./
g++ xxx.cpp && ./a.out
Faites une boucle pour compiler et exécuter xxx.cpp
en indiquant les options de compilation suivantes :
Aucune
-m96bit-long-double
-mlong-double-64
-m32
for OPTION in '' -m96bit-long-double -mlong-double-64 -m32
do
g++ $OPTION xxx.cpp && ./a.out
done
Il se cache dans les box internet, appareil photo, télé, borne wifi,
disque dur réseaux, enceintes connectée, liseuse, aspirateur robot...
Et on le trouve même sur la planète Mars.
Une distribution Unix c'est principalement 2 choses :
Un noyau "standard" avec des fonctions de bases.
Des bibliothèques et applications construites au dessus de
ce noyau.
A quoi sert le shell ?
C'est un langage textuel permettant de travailler bien plus rapidement
qu'en utilisant une interface graphique.
Son apprentissage est l'objectif principal de ce cours.
Exemples d'utilisation :
Naviguer, complétion.
Manipuler facilement pleins de fichiers : ménage, recherche.
Plusieurs milliers de commandes sur une installation classique.