Table des matières
- Avant propos
- 1. Introduction
- 2. Les entités manipulées par UNIX
- 3. Le shell (sh, ksh, bash, zsh, ...)
- 3.1. Lancement d'une commande
- 3.2. Les options des commandes
- 3.3. La documentation
- 3.4. Comment taper plus vite des commandes.
- 3.5. Les variables de l'environnement
- 3.6. Redirection des entrées sorties
- 3.7. Insertion de caractères venant d'une autre commande
- 3.8. Regroupements et enchaînements de commandes
- 3.9. Gestion des processus.
- 3.10. Structures de contrôle
- 3.11. Scripts shell
- 4. Quelques commandes
Le but de ce cours est de vous permettre d'utiliser UNIX en tant que simple utilisateur et non en tant que programmeur ou bien administrateur. Les aspects théoriques sont donc écartés au profit des aspects pratiques. Ces aspects pratiques vous seront utiles dans les prochaines années pour vous faire gagner du temps lors de la réalisation de vos futurs TP d'informatique.
Ne prenez surtout pas ce document comme une référence sur UNIX car des points complexes non utiles aux débutants ont été écartés. Ainsi, il y a beaucoup d'affirmations fausses dans ce document. Si vous estimez que cela peux gêner un débutant, prévenez-moi. Dans le futur, un symbole indiquera les affirmations fausses et pointera sur une explication approfondie.
UNIX est un système d'exploitation créé par AT&T qui a commencé à être utilisé dans les années 1970. C'est le premier système à ne pas avoir été écrit en assembleur. Ces sources ont été diffusés librement dans le monde et de nombreuses versions différentes ont été faites. Linux est l'une des très nombreuses versions qui existent, MacOS en est une autre. Ou trouve-t-on Unix :
Téléphones/tablettes Android et IOS
Routeurs réseaux (freebox...)
Disques réseaux (NAS)
Lecteurs multimédia
Téléviseurs. Lecteur BD. Aspirateur...
et bien sûr les serveurs et ordinateurs classiques
Découpage des séances
Cours 1 : ...-2.2 : Terminal, système de fichier.
Cours 2 : 2.3-3.4 : Processus, introduction au shell.
Cours 3 : 3.5-3.10 : shell avancé.
Cours 4 : 3.11-4.1 : script shell, expressions régulières.
Cours 5 : 4.2-... : Outils de base.
Ce cours est découpé en plusieurs parties, dans chaque partie seul les rudiments seront abordés. En effet, le but n'est pas de devenir un expert tout de suite mais d'avoir des connaissances de base que vous étendrez au cours des années qui viennent en les mettant régulièrement en pratique et en suivant de futurs cours.
Une présentation des entités que l'on manipule avec UNIX.
La présentation du shell qui est un langage pour communiquer avec la machine en ligne de commande. Le shell permet aussi d'écrire des scripts, qui sont en fait de simple programmes.
Un ensemble d'applications standards que le shell peut combiner ensemble.
Une présentation de quelques outils de base permettant de faire du développement en utilisant UNIX.
Une présentation de quelques outils de base permettant d'utiliser le réseau.
Vous trouverez plein de ressources sur le web pour vous aider à progresser dans la maîtrise d'UNIX, je ne les détaillerais pas, prenez celle qui vous convient.
Une lecture que je vous conseille pour des raisons culturelle sont les Jargon Files, vous devez les garder sous le coude pour un accès rapide au glossaire qui explique tous les mots que vous ne trouverez pas dans un dictionnaire d'anglais.
Ces notations sont utilisées dans tous les manuels UNIX et souvent ailleurs.
Pour indiquer les caractères non affichable on fait souvent un dessin : ←, →, ↑, ↓, ↵
La tabulation n'est pas visible, on l'affichera comme ⇥. Sur l'écran, le plus souvent, elle déplace le curseur sur la prochaine colonne dont la position est un multiple de 8.
Souvent, pour bien le mettre en évidence en dessine un symbole à la place de l'espace.
␣Pour indiquer qu'il faut taper <Control-C> on note <^C> . Le code ASCII de <^C> est
3car <C> est la troisième lettre de l'alphabet. Il n'y a pas de code ASCII associé à des séquences comme <^=>En anglais le symbole
#est l'abréviation de 'nombre de' ou 'numéro'. Il sert à préfixer des variables définissant des entiers.Il existe 2 ou 3 apostrophes différentes sur les claviers et le dessin sur le clavier ne représente pas forcément ce que vous voyez sur l'écran qui lui même peut être différents du code du caractère. Et si l'on confond l'apostrophe avec l'accent cela en fait 5.
L'apostrophe droite qui est un petit trait vertical, souvent nommée quote en anglais et qui est dans la table ASCII 7 bit standard :
'L'apostrophe penchée à gauche, souvent nommée anti-quote ou accent grave, qui est dans la table ASCII 7 bit standard :
`
Ce qui est écrit entre crochets
[]est facultatif. Les crochets peuvent s'emboîter.Je ␣ lis[ ␣ un[ ␣ super] ␣ cours ␣ UNIX].Cette phrase peut s'interpréter comme
Je ␣ lis.Je ␣ lis ␣ un ␣ cours ␣ UNIX.Je ␣ lis ␣ un ␣ super ␣ cours ␣ UNIX.
Le choix multiple est indiqué par le symbole pipe ( <|> ), souvent indiqué entre accolades. Exemple :
{Il|Elle} {aime|déteste} les {chiens|chats}.
L'ensemble de ce cours parle de ligne de commande par opposition à l'interface graphique qui utilise une souris ou un autre moyen de désignation 2D.
L'interface graphique est idéal pour réaliser des opérations qui ne seront à faire qu'une seule fois car il ne nécessite pas d'apprentissage s'il est correctement réalisé. Si les actions sont à faire plusieurs fois alors cette opération est plus vite faite en ligne de commande car l'on peut facilement répéter des commandes.
Quand on sait ce que l'on veut faire l'interface graphique est fatiguant à utiliser car l'utilisateur est obligé d'utiliser sa vue et son cerveau afin d'exécuter des commandes. Prenons le cas de la sauvegarde des données (le raccourci clavier est <^S> ). Si l'on utilise l'interface graphique, il faut :
Trouver visuellement le menu
Déplacer la souris dessus.
Cliquer sur le bouton de la souris.
Attendre que le menu apparaisse.
Chercher visuellement le bouton
Déplacer la souris dessus.
Cliquer sur le bouton de la souris.
Un autre exemple est le cas de la navigation dans une arborescence de noms (un ensemble de fichiers par exemple). L'interface graphique est idéale pour visiter quand on ne connait pas mais elle est un ordre de grandeur plus lente par rapport à une interface textuelle quand on connaît le nom de l'entité que l'on veut voir.
Utiliser un interface graphique ne vous permettra pas de devenir plus productif à long terme. En effet vous ne pourrez pas déplacer la souris beaucoup plus vite. Par contre se forcer à utiliser un interface texte, est gagnant à long terme :
Vous apprenez à taper plus vite au clavier.
Vous découvrez au fur et à mesure de nouvelles commandes et de nouvelles options.
Vous pouvez écrire facilement vos propres commandes. Et donc ainsi augmenter votre productivité.
Vous pouvez plus facilement travailler à distance avec des liaisons faibles débits.
Quand vous dialoguez avec quelqu'un il est plus facile de lui donner des commandes textuelles plutôt que d'expliquer où il faut cliquer.
Un terminal est un dispositif comportant un écran et un clavier. Le terminal est raccordé à l'ordinateur par une liaison RS232C (COM1 sous DOS), parallèle, ... Historiquement de nombreux terminaux étaient branchés sur le même ordinateur. Ce que l'utilisateur tape sur le clavier est envoyé à l'ordinateur. Ce que l'ordinateur envoie au terminal est affiché sur l'écran.
Dans notre environnement il n'y a plus de terminaux, seulement des ordinateurs avec une carte vidéo. Pour les applications non graphiques, un terminal leur est nécessaire. C'est pour cela que les systèmes d'exploitation fournissent des terminaux virtuel. Les consoles dans l'environnement texte de Linux ou les xterm dans l'environnement graphique X11.
Les terminaux (virtuel ou non) analysent les textes envoyés par l'ordinateur et extraient de ces textes des commandes qui leur sont destinés. Ces commandes sont par exemple l'effacement de l'écran, le positionnement du curseur, le choix des couleurs, le choix de la fonte, ... Si l'ordinateur envoie le contenu d'un fichier comprenant de nombreux caractères de contrôle, il peut rendre inutilisable le terminal. Il faut dans ce cas utiliser la commande reset qui remet pas mal de choses en place, ou bien fermer le terminal.
Le système peut recevoir des caractères particuliers venant du terminal (caractères que vous avez tapé au clavier) :
- <^C>
Le système demande au processus qui lit le clavier de se terminer.
- <^D>
Le système indique au processus qui lit le clavier que l'utilisateur n'a plus rien à taper. C'est une fin de fichier.
UNIX est un système d'exploitation, c'est lui qui gère l'ensemble des ressources de la machine. Les ressources les plus visibles pour l'utilisateur sont :
Les utilisateurs et leurs droits. N'importe qui n'a pas le droit de faire n'importe quoi.
Le processeur qui fait les calculs (CPU). Il faut le faire travailler pour tous le monde.
La mémoire qui est un support de stockage avec un accès rapide et aléatoire (pas forcément du début à la fin).
Les dispositifs de stockage de l'information comme les disques, CDROM, clef USB.
Les dispositifs de communications comme le réseau (avec ou sans fil), les ports parallèle et série, l'USB.
Les dispositifs d'entrée d'information comme le clavier, la souris.
Les dispositifs d'affichage d'information comme les LEDs du clavier, la carte vidéo. La carte vidéo peut être en mode graphique et afficher des fenêtres grâce à X11 ou bien en mode console et afficher du texte. On passe sur la console
4en tapant <ALT-F4> ou <Ctrl-ALT-F4> si l'on est sous X11.

Quand on travaille avec UNIX c'est forcément avec une certaine identité qui vous donne certains droits. La clef de cette identité est votre UID qui est un entier. Les informations associées à votre identité sont entre autres :
Votre login, c'est l'identifiant de connexion, composé de caractère alphanumérique mais ne commençant pas par un chiffre.
Votre mot de passe crypté (chiffré).
Votre groupe d'utilisateur indiqué par le GID. Si votre groupe est 42, alors pour toutes les entités dont le groupe propriétaire est 42, vous aurez les droits de l'entité qui sont associés au groupe.
Vos vrai nom, prénom, adresse, téléphone, ...
Le nom de l'endroit ou sont stockés tous vos fichiers. Normalement :
/home/votre_loginVotre interpréteur de commande. Normalement : /bin/sh
L'utilisateur d'UID 0 est le super utilisateur,
il est appelé root et il
a tous les droits.
Toutes ces informations sont généralement stockées
dans des fichiers appelés :
/etc/passwd et /etc/group
Quand plusieurs machines partagent les mêmes utilisateurs,
les informations sur les utilisateurs sont lues le réseau via
des protocoles comme LDAP ou NIS.
Le système de fichier permet de classer des informations de manière persistante dans des fichiers et de les organiser dans des répertoires.
L'administrateur peut accrocher au système de fichier d'autres systèmes de fichier contenu dans des medias (disque, clef USB, ...), réseau ou virtuel.
Les entités du système de fichier sont de deux types :
Les répertoires (directory en anglais, et dossier dans d'autres systèmes). Ces répertoires sont les noeuds d'une hiérarchie et peuvent contenir d'autres fichiers et répertoires.
Le répertoire associe un nom court à chaque entité qu'il contient.
Le nom court ne peut contenir les caractères
/et^@(caractère de code ASCII0).Tous les répertoires contiennent les répertoires nommés
.(eux-mêmes) et..(leur père).
Les fichiers sont des entités dans lesquels on peut lire ou écrire des octets, souvent se positionner à un endroit précis à l'intérieur.
Le seul répertoire "sans père" du système de fichier
est la racine du système de fichier (root
en anglais) son nom est /
Le nom long d'un fichier est le chemin (path)
qui permet à partir de la racine d'arriver jusqu'à l'entité
qui nous intéresse.
Par exemple :
/usr/include/math.h/usr/./include/./math.h/usr/etc/../include/math.h
Un chemin relatif est un chemin ne partant pas de la racine mais de l'endroit ou se trouve celui qui pose la question. Par exemple :
math.h./math.h../include/math.h
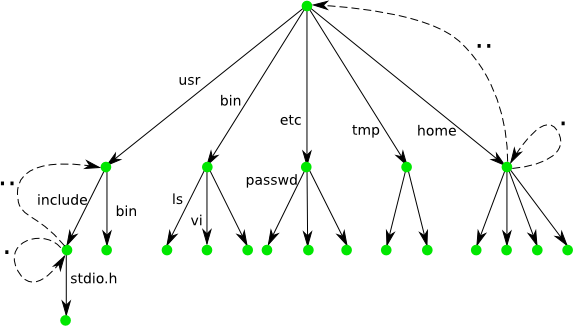
Les fichiers sont eux-mêmes de différents types, mais quelque soit leur type ils s'utilisent de la même façon, c'est-à-dire comme un flux ou un tableau d'octets.
Les fichiers de données qui sont persistant si le support de stockage est persistant. Par exemple dans
/dev/hda2, (écrire directement sur le support de stockage sans passer par le système de fichier détruira les données).Ce sont les fichiers qui vont contenir toutes les informations que vous allez rentrer dans la machine.
Les fichiers ``lisibles/interprétables par un être humain´´ sont des fichiers ne contenant que des caractères affichables (si l'on considère : ␣ , ⇥ et ↵ comme affichables). Le séparateur de ligne est le code de contrôle nommé linefeed, c'est normalement le seul que verront les applications sous UNIX.
![[Avertissement]](warning.png)
Avertissement Sous MacOS le séparateur est carriage return et sous DOS c'est la paire carriage return linefeed. Certain éditeur de texte vous cachent ces différences provocant ainsi certains comportements étranges.
Les liens symboliques.
Un lien symbolique contient un chemin menant au fichier. Ce chemin peut être absolu ou relatif par rapport au répertoire contenant le lien symbolique. Quand une application fait un traitement sur le lien symbolique, le traitement est en fait fait sur le fichier dont le nom est contenu dans le lien symbolique. Les liens symboliques sont complètement transparents vis à vis des applications. Ils sont créés par la commande ln ␣
-sLes fichiers périphériques (device en anglais) qui permettent d'accéder aux périphériques réels ou virtuels de la machine. Ils sont très nombreux, ceux qui sont indispensables sont indiqués, ceux que vous rencontrerez les plus souvent sont :
/dev/sda2(Linux)sdveut dire SCSI disk mais cela peut très bien être un CDROM, ou un autre support de stockage. Leaindique que c'est le premier disque. Le2indique que c'est la deuxième partition du disque, si on n'indique pas le2on a accès à tous le disque et donc à toutes les partitions./dev/ttyS0(Linux)Ce fichier permet d'accéder à la première prise RS232C (COM1 sous DOS), c'est un flux, donc pas d'accès aléatoire.
/dev/lp0(Linux)Ce fichier permet d'accéder à la première prise centronics (port parallèle) (
PAR1sous DOS), c'est un flux, donc pas d'accès aléatoire.lpveut dire line printer/dev/tty1(Linux)Ce fichier permet d'accéder à la première console texte de Linux.
Les fichiers virtuels qui permettent en fait d'accéder à des services ou bien à paramétrer le système.
/dev/nullINDISPENSABLETout ce qui est écrit dans ce fichier disparaît et quand on lit, on arrive à la fin tout de suite.
/dev/zero(Linux) INDISPENSABLEFichier de taille infinie contenant des octets nuls.
/dev/pts/3(Linux)C'est le nom d'une console totalement virtuelle (la quatrième) qui est utilisée par les applications graphiques qui veulent faire semblant d'être un vraie console (xterm par exemple) ou bien lorsque l'on accède au système en ouvrant une console réseau (telnet, rlogin, ssh par exemple).
/dev/ttyINDISPENSABLECe périphérique est en fait la console qui a été utilisée pour lancer le processus. Elle peut être virtuelle ou réelle.
/proc(Linux) INDISPENSABLECe répertoire contient des milliers de fichiers virtuels permettant de voir l'état du système d'exploitation et des périphériques mais aussi de changer leur état. On détaillera ce qui est intéressant dans ce répertoire au fur et à mesure.
C'est un programme exécutable par le CPU (non lisible par un être humain normal) qui est en train de s'exécuter. Seul les processus peuvent dialoguer avec le système d'exploitation. Le système d'exploitation partage l'accès aux CPU entre les différents processus.
Les attributs principaux d'un processus sont :
Son PID qui est un entier l'identifiant de manière unique.
Le PID du processus qui l'a lancé (PPID).
L'UID du propriétaire du processus, c'est lui qui va définir les droits du processus.
Un répertoire courant. Si un chemin d'accès au fichier ne commence pas par le caractère
/alors on le préfixe par le nom du répertoire courant. On appel ceci un chemin relatif par opposition à un chemin (ou nom) absolu.Un tableau des fichiers ouverts. L'indice dans ce tableau commence à 0 et est appelé file descriptor (en raccourci fildes). Les fildes suivants existent par défaut :
0est l'entrée standard, c'est ici qu'est lu ce que l'utilisateur veut entrer dans le programme. Souvent c'est le clavier.1est la sortie standard, c'est ici que le programme écrit le résultat de son traitement. C'est souvent l'écran.2est la sortie d'erreur, c'est ici que le programme affiche les erreurs et alertes durant son fonctionnement. C'est souvent l'écran.
Un espace mémoire qui lui est propre, qui ne pourra être lu ou modifié par aucun autre processus. Et inversement, il ne pourra lire/modifier l'espace mémoire d'aucun autre processus.
Un ensemble de variables appelé environnement contenant des valeurs (chaînes de caractère au format du du langage C). Par exemple
HOMEcontient le nom du répertoire de connexion,LC_MESSAGEScontient la langue des messages devant s'afficher.PATHindique ou se trouvent les programmes. Ces variables sont utilisées par beaucoup d'applications.Les arguments (paramètres) de lancements du processus.
La commande ps permet de lister les processus et kill permet de les tuer en leur envoyant un signal leur demandant de se terminer (on peut envoyer d'autres signaux).
Quand un processus en crée un autre (fils), le fils hérite de tous les attributs de son père. Sauf bien sûr le PID et la mémoire qui sera normalement une copie de celle de son père
init est le premier processus
lancé par le système, c'est l'ancêtre de tous les processus,
son PID est 1.
Quand un processus meurt, sa mémoire est libérée, les variables de l'environnement disparaissent, ses fichiers sont fermés et il retourne un valeur indiquant s'il s'est correctement exécuté à son père.
Ce sont des langages interprétés. L'interpréteur est un programme exécutable qui va interpréter des commandes stockées dans un fichier ou tapées au clavier. C'est lui qui va traduire les commandes en appels système, permettant ainsi à l'utilisateur de travailler plus simplement. Le shell permet :
de lancer des processus en indiquant le programme et ses arguments.
de changer les variables d'environnement (
HOME, ...)d'indiquer les fichiers où sont faits les entrées sorties.
de savoir si une commande (un processus en fait) s'est bien terminé.
d'écrire des programmes simples.
Avant tout il faut réussir à obtenir un shell. Pour cela connectez vous sur une console ou bien lancez avec l'interface graphique une application comme xterm (ou un autre émulateur de terminal).
Vous pouvez taper une commande dès que le prompt (invite de commande) apparaît. Le lancement d'un commande est très simple :
nom ␣ argument1 ␣ argument2...
Certaines commandes sont des programmes, d'autres sont intégrées dans le shell, on les appelle des builtins (commandes intégrées dans le shell). Lorsqu'un builtin est exécuté cela ne lance pas de processus contrairement au cas du programme.
Quand une commande a un problème, ses messages d'erreurs sont affichés sur la sortie d'erreur et non sur la sortie standard. Généralement ses deux sorties vont sur l'écran mais ce n'est pas toujours le cas.
Le prompt réapparaîtra quand la commande sera terminée.
Le nom peut être un nom long, un nom relatif ou un nom court. Dans le cas d'un nom court le shell recherche la commande dans tous les répertoires dont le nom figure dans la variable
PATHde l'environnement. Par exemple cette variable peut contenir :/bin:/usr/bin:.Le troisième répertoire est '.', cela indique que l'on cherche aussi les commandes dans le répertoire courant.Si un arguments contient des caractères qui ne sont pas alphanumériques il faut encadrer l'argument par des guillemets ou des cotes.
Les commandes builtins sont des fonctions du shell ce ne sont pas des commandes (programmes) UNIX. Elles n'existent pas dans tous les shell et ne fonctionnent pas forcément de la même manière.
Un filtre est une commande qui lit son entrée standard, la traite et écrit le résultat sur la sortie standard. Ils permettent de ne pas utiliser le système de fichier et donc le disque dur.
La cote annulle la signification de tous les caractères sauf la cote.
Le guillemet annulle la signification de tous les caractères sauf l'anti-slash, le dollar et le guillemet : \, $, "
Les commandes builtins sont des fonctions du shell ce ne sont pas des commandes (programmes) UNIX. Elles n'existent pas dans tous les shell et ne fonctionnent pas forcément de la même manière.
Les commandes suivantes nous permettront de faire les exemples suivants.
- passwd ou yppasswd
Cette commande permet de changer son mot de passe. Attention il n'y a pas de feedback quand vous tapez le mot de passe, cela n'affiche pas d'étoiles pour ne pas aider les gens qui voudraient trouver votre mot de passe.
- man
Cette commande d'afficher le manuel en ligne.
- echo (builtin)
Cette commande affiche ses arguments sur la sortie standard les uns après les autres sur la même ligne. Elle affichera une fin de ligne après le dernier argument.
- pwd (builtin)
Cette commande affiche sur la sortie standard, le chemin absolu du répertoire courant.
- cd (builtin)
Le répertoire courant devient celui indiqué en paramètre. S'il n'y en a pas alors c'est celui indiqué dans la variable d'environnement
HOMELe répertoire en paramètre peut être indiqué par un nom long, court ou relatif.- cat (filtre)
Cette commande affiche le contenu des fichiers indiqués comme argument sur la sortie standard. Si le fichier contient un million de lignes, elles seront toutes affichées !
- ls
Cette commande affiche des informations sur les fichiers indiqués comme argument sur la sortie standard. Si la commande est lancée sans indiquer de nom de fichier, elle liste le contenu du répertoire courant (c'est
.).- date
Cette commande affiche la date et l'heure sur la sortie standard.
- cp
Copie de fichiers et d'arborescence.
- ln
Création de lien physique et liens symboliques.
- mkdir
Création de répertoire.
- mv
Renommer et déplacer des fichiers et répertoires.
- rm
Destruction de fichiers et répertoires.
- chmod
Changement des droits d'accès.
- grep (filtre)
Crible permettant d'extraire certaines lignes de fichiers.
- sort (filtre)
Crible permettant de trier les lignes de fichiers.
- wc (filtre)
Affiche le nombre d'octets, de mot et de lignes contenu dans des fichiers ou l'entrée standard.
Voici ce que leur utilisation peut donner. Ce qui est en gras est ce que l'utilisateur a tapé.
$pwd↵/home/exco/Toto$echo ␣ un ␣ chat↵un chat$echo ␣ un ␣ ␣ ␣ ␣ chat↵un chat$echo ␣ 'un ␣ ␣ ␣ ␣ chat'↵un chat$echo ␣ 'un↵>chat'↵un chat$ls↵Makefile ch01.html ch02s02.html index.html unix.ps Makefile~ ch01s02.html ch02s03.html pr01.html unix.xml TP ch02.html ch03.html unix.html unix.xml~$ls ␣/↵bin cdrw etc lib net root tmp var boot dev floppy lost+found proc sbin usbmem vol cdrom dext home misc projet sys usr$cat ␣/etc/papersize↵a4$cat ␣/proc/version↵Linux version 2.6.12 (root@lirispaj) (gcc version 3.3.5 (Debian 1:3.3.5-13)) #1 SMP Thu Jun 23 10:24:03 CEST 2005$cat ␣/etc/papersize␣/proc/version↵a4 Linux version 2.6.12 (root@lirispaj) (gcc version 3.3.5 (Debian 1:3.3.5-13)) #1 SMP Thu Jun 23 10:24:03 CEST 2005$passwd↵Changing password for exco (current) UNIX password:↵ pour être certain que c'est vousEnter new UNIX password:↵; rien ne s'affiche, même pas des étoiles...Retype new UNIX password:↵ pour être certain de ne pas s'être trompépasswd: password updated successfully
Les commandes ont des arguments. Parfois on veut modifier le fonctionnement de la commande, Pour cela on utilise des options. C'est la commande qui analyse ses arguments, c'est donc elle qui décide d'y trouver des options ou non. Voici des informations qui sont généralement vraies :
Une option est un argument dont le premier caractère est un tiret
-Si l'option commence par un seul tiret alors elle est définie par un seul caractère.
Il n'est pas nécessaire de répéter le tiret devant chaque option, on peut concaténer les caractères pour raccourcir la commande.
Si l'option commence par deux tirets alors elle peut être définie par plusieurs caractères. Dans ce cas, on ne peut pas concaténer les options.
Quand l'option a besoin d'un paramètre, elle prend automatiquement le prochain argument comme son paramètre.
Après le premier argument qui n'est pas une option on ne doit plus mettre d'options. Les options doivent être les premiers paramètres. Il est possible que cela fonctionne sous certains UNIX mais ce n'est pas portable.
Certaines options sont les mêmes pour de nombreuses commandes. Voici les plus courantes :
--helpou-hAffiche une mini documentation sur la commande.
--verboseou-vDurant son exécution, le processus indique ce qu'il fait.
--forceou-fFaire l'action même si elle est dangereuse.
--recursiveou-Rou-rSouvent pour les commandes pouvant manipuler une hiérarchie de fichiers.
Voyons quelques options de ls qui en possède de très nombreuses.
-l(la lettre L minuscule)Affiche plus d'information (l=long)
-rw-r----- 1 exco liris 105 Aug 31 16:43 Makefile
Son type.
- '-'
Fichier normal
- 'd'
répertoire (directory)
- 'l'
Lien symbolique
- 'b' ou 'c'
Fichier ``périphérique´´
Les droits d'accès pour le propriétaire du fichier, le groupe d'utilisateur propriétaire du fichier et le reste des utilisateurs. Ils sont modifiables avec la commande chmod.
- 'r'
Droit de lire
- 'w'
Droit d'écrire et donc de vider.
Dans le cas d'un répertoire cela donne le droit d'enlever et d'ajouter des fichiers de le répertoire.
- 'x'
Droit d'exécuter directement ou via un interpréteur.
Dans l'exemple : L'utilisateur 'exco' a le droit de lire et d'écrire, les membres du 'liris' ont le droit de lire, les autres utilisateurs ne peuvent rien faire.
C'est le nombre de noms que porte le fichier. C'est pour les utilisateurs expérimentés.
Utilisateur propriétaire. Modifiable par la commande chown.
Groupe propriétaire. Modifiable par la commande chgrp.
Taille en octets (105).
Date de dernière modification. Ici, le fichier a été modifié le 31 août de l'année courante. Si la date est plus ancienne, l'heure est remplacée par l'année.
-tAffiche les fichiers les plus récemment modifiés en premier.
-aAffiche aussi les fichiers cachés. Ce sont les fichiers dont le nom commence par '.' comme
.,..,.profile-Rou--recursiveSi des informations sur un répertoire sont affichées alors les informations sur les fichiers qu'il contient sont affichés. Et on recommence jusqu'à ce que tous les fichiers soient traités.
$ls↵Makefile Makefile~ TP unix.css unix.css~ unix.html unix.xml unix.xsl$ls ␣-l↵total 101 -rw-r----- 1 exco liris 105 Aug 31 16:43 Makefile -rw-r--r-- 1 exco liris 86 Jul 5 23:02 Makefile~ drwxr-xr-x 5 exco liris 1000 Aug 31 15:53 TP -rw-r--r-- 1 exco liris 654 Sep 1 12:09 unix.css -rw-r--r-- 1 exco liris 65 Aug 31 16:44 unix.css~ -rw-r--r-- 1 exco liris 41251 Sep 1 12:16 unix.html -rw-r--r-- 1 exco liris 36379 Sep 1 14:05 unix.xml -rw-r--r-- 1 exco liris 476 Aug 31 16:43 unix.xsl$ls ␣-t↵unix.xml unix.html unix.css unix.css~ Makefile unix.xsl TP Makefile~$ls ␣ou-lt↵-tlou-t -lou-l -ttotal 101 -rw-r--r-- 1 exco liris 36379 Sep 1 14:05 unix.xml -rw-r--r-- 1 exco liris 41251 Sep 1 12:16 unix.html -rw-r--r-- 1 exco liris 654 Sep 1 12:09 unix.css -rw-r--r-- 1 exco liris 65 Aug 31 16:44 unix.css~ -rw-r----- 1 exco liris 105 Aug 31 16:43 Makefile -rw-r--r-- 1 exco liris 476 Aug 31 16:43 unix.xsl drwxr-xr-x 5 exco liris 1000 Aug 31 15:53 TP -rw-r--r-- 1 exco liris 86 Jul 5 23:02 Makefile~$ls ␣-l␣/etc/passwd␣/bin/sh↵lrwxrwxrwx 1 root root 4 Jun 23 11:55 /bin/sh -> bash -rw-r--r-- 1 root root 1493 Jun 23 10:42 /etc/passwd
Dans le cas des liens symboliques, le fichier
pointé est indiqué après le ->
Il faut toujours lire les documentations en anglais et utiliser les logiciels en anglais si c'est leur langue original. En effet les traductions sont toujours très mauvaises.
UNIX offre énormément de commandes et celles-ci contiennent de nombreuses options. Il est impossible de tout connaître. Par contre la documentation en ligne de commande est largement suffisante.
Pour un accès rapide, utilisez l'option --help
de la commande.
Cette aide est minimal mais est suffisante quand
on a l'habitude.
Pour une aide complète sur une commande. Il faut consulter le manuel à l'aide de la commande man.
| Avertissement |
|---|---|
L'aide sur les commandes builtins (echo, cd, pwd, ...) doit être demandée avec la commande help qui est évidemment un builtin car lié au shell utilisé. |
Le contenu du manuel ne s'affiche pas complètement sur l'écran, il ne tiendrait pas. Il est donc affiché en utilisant la commande more. Cette commande affiche les textes page par page sur l'écran. Interactivement, l'utilisateur peut taper des commandes au clavier :
↵Fait monter le contenu de l'écran d'une ligne.
␣ou<Page Suivante>Page suivante.
<Page précédente>Page précédente.
/toto↵Permet de chercher la prochaine occurrence du mot
toto.n, <n> pour nextPermet de chercher la prochaine occurrence du dernier mot recherché.
q, <q> pour quitTermine la commande more
h, <h> pour helpAffiche l'aide de la commande more
Le contenu d'une page de manuel contient presque toujours les mêmes sections dans le même ordre. Voici les plus importantes.
- NAME
Nom et description en une ligne de la commande
- SYNOPSIS
La ou les syntaxes d'utilisation de la commande.
- DESCRIPTION
Description de la commande, son utilité.
- OPTIONS
La description de chacune des options d'utilisation.
- EXAMPLES
Des exemples d'utilisation, c'est la partie la plus intéressante du manuel et elle est généralement à la fin.
- ENVIRONMENT
La description des variables de l'environnement qui peuvent modifier le comportement de la commande.
- FILES
Les fichiers (généralement de configuration) nécessaires à la commande.
- SEE ALSO
La liste des autres pages de manuel qui sont liées à celle ci.
Pour trouver une commande par mot-clef,
on peut utiliser l'option -k de la commande man.
Cela permet de lister toutes les commandes qui
ont le mot clef que vous recherchez dans leur description.
$man ␣-k␣ remove↵colrm (1) - remove columns from a file cut (1) - remove sections from each line of files lprm (1) - remove jobs from the line printer spooling queue modprobe (8) - program to add and remove modules from the Linux Kernel remove (3) - delete a name and possibly the file it refers to rm (1) - remove files or directories rmdir (1) - remove empty directories uniq (1) - remove duplicate lines from a sorted file XRemoveHost (3x) - control host access and host control structure
Chaque page de manuel est stockée dans une section de la documentation UNIX. Voici une liste non exhaustive des sections :
- 1
Les programmes que tout utilisateur peut exécuter.
- 2
Les appels systèmes, c'est-à-dire les fonctions du noyau UNIX.
- 3
Les fonctions de la bibliothèque standard du langage C,
- 3x
Les fonctions des bibliothèques X11 (le système de fenêtrage).
- 4
Les fichiers périphériques.
- 5
Le format des fichiers. C'est-à-dire la description de leur contenu.
Attention, un page de manuel peut porter le même nom
dans plusieurs sections du manuel.
Dans ce cas, on spécifie la section du manuel
dans laquelle on veut la chercher.
man ␣ 5 ␣ passwd
permet d'avoir la documentation sur le format
du fichier /etc/passwd.
Il faut tout d'abord remarquer que quand on donne des arguments à une commande ce sont généralement des noms de fichier.
Lorsque le shell trouve certains caractères spéciaux dans les arguments d'une commande il peut remplacer l'argument par un ou plusieurs noms de fichiers. Ces caractères spéciaux sont :
~/en début de motLe nom absolu de votre répertoire de connexion.
~toto/en début de motLe nom absolu du répertoire de connexion de l'utilisateur
toto- *
Une chaine de caractères quelconques ne commençant pas par '.', ne contenant pas '/' et pouvant être vide.
- ?
Un caractère quelconque sauf '/' et pas '.' en première position.
- [agy]
Un caractère de la liste, ici : 'a' ou 'g' ou 'y'.
- [a-zA0-9]
Une minuscule ou 'A' ou un chiffre.
- [!a-zA-Z]
Le '!' en première position indique la négation. C'est donc remplaçable par un caractère qui n'est pas alphabétique.
- \
Le '\' annule comme d'habitude la signification du caractère suivant. Donc '\*' représente une étoile et non une chaine de caractères quelconque.
$echo ␣ /etc/p*d↵/etc/pam.d /etc/passwd$echo ␣ /*[!v]/p*d↵/bin/pwd /etc/pam.d /etc/passwd$cd ␣ /↵$echo ␣ *↵bin boot dev etc floppy home lib lost+found misc proc root sbin sys tmp usr var$echo ␣ "*" ␣ '*'↵* *$echo ␣ *n↵bin sbin
Dans beaucoup de logiciels sous UNIX la touche ⇥ (tabulation) demande au système de compléter la suite de la commande s'il n'y a pas ambiguïté. En cas d'ambiguïté, il y a un signal sonore et dans ce cas un deuxième appuis sur ⇥ provoque l'affichage de la liste des suites possibles.
| Avertissement |
|---|---|
Il faut impérativement utiliser la complétion afin de ne pas taper des noms de fichiers faux. |
$ca⇥<BEEP>⇥Liste tous les programmes dont le nom commence par cacabextract cancel cardmgr cal capitalize case calendar captoinfo cat callgrind card catchsegv callgrind_annotate cardctl catman callgrind_control cardinfo$cat⇥<BEEP>⇥Liste tous les programmes dont le nom commence par catcat catchsegv catman$cat␣ /etc/pas⇥swd↵Pas de <BEEP> car il n'y a pas d'ambiguïté
Les variables de l'environnement permettent de modifier le comportement des commandes sans avoir besoin de leur passer des options à chaque fois que l'on tape la commande.
On a déjà parlé de HOME et de PATH qui
sont des variables de l'environnement.
L'environnement est local au processus,
les autres ne peuvent y accéder ou le modifier.
Quand un processus est lancé il hérite des
variables de son père que celui-ci désire lui passer.
Pour voir toute les variables actuellement définies il suffit d'utiliser la commande builtin set. De nombreuses variable ont été enlevée de l'exemple suivant.
$set↵DISPLAY=:0.0Indique ou l'affichage graphique doit ce faire.HOME=/home/excoRépertoire de connexionLINES=24Nombre de lignes du terminal texteCOLUMNS=80PATH=/bin:/usr/bin:/usr/bin/X11:/usr/sbin:.Ou sont les programmesPS1='$ 'promptPS2='> 'prompt indiquant que la commande n'est pas terminéeTZ=Europe/ParisFuseau horaireLC_ALL=POSIXTous les affichages sont en ``anglais´´
Quand vous taper une commande vous pouvez indiquer qu'il faut utiliser le contenu d'une variable. On le fait en préfixant le nom de la variable par un '$'. C'est le shell qui fait la substitution, les programmes ne sont au courant de rien. Un nom de variable est composé de caractères alaphanumériques et du souligné.
$echo ␣ $HOME␣ '$HOME' ␣ "$HOME"↵/home/exco $HOME /home/exco$ls ␣-l␣ $HOME/.profile↵-rwxr-xr-x 1 exco liris 4242 May 9 13:08 /home/exco/.profile
La modification n'affecte que le processus en cours. Si la variable est exporté elle sera passée aux descendants du processus courant.
$TOTO=678↵$echo ␣ $TOTO↵678$TOTO='6 7 8'↵$echo ␣ $TOTO↵6 7 8$date↵Mon Sep 5 14:29:00 CEST 2005$LC_TIME=french↵$date↵Mon Sep 5 14:29:00 CEST 2005Toujours en anglais car la variable n'est pas été exportée$export ␣LC_TIME↵$date↵lun Sep 5 14:29:10 CEST 2005
La commande read prend une ligne de l'entrée standard et la stocke dans les noms de variables passées en paramètre.
$read ␣ A↵Je ␣ suis, ␣ ␣ ␣ ici$echo ␣ "$A"↵Je suis, ici$read ␣ A ␣ B↵Je ␣ suis, ␣ ␣ ␣ ici$echo ␣ "($A)" ␣ "($B)"↵(Je) (suis, ici)$read ␣ A ␣ B ␣ C↵Je ␣ suis, ␣ ␣ ␣ ici$echo ␣ "($A)" ␣ "($B)" ␣ "($C)"↵(Je) (suis,) (ici)$read ␣ A ␣ </etc/papersize↵$echo ␣ "$A"↵a4
Jusqu'à présent, toutes les commandes lisaient sur le clavier (entrée standard par défaut) et écrivaient leur résultat sur l'écran (sortie standard par défaut). Les messages d'erreurs allaient aussi sur l'écran (sortie d'erreur par défaut). On peut changer cela en l'indiquant sur la ligne de commande. C'est utile évidemment pour garder une trace des résultats calculés.
- '>
nom-de-fichier' La sortie standard devient ce fichier. Il est vidé avant même le démarrage du processus.
- '>>
nom-de-fichier' La sortie standard devient ce fichier. Le fichier n'est pas vidé, ce qu'écrira le programme s'ajoutera à la fin.
- '<
nom-de-fichier' L'entrée standard devient le fichier, c'est le fichier qui sera lu au lieu du clavier.
- '2>
nom-de-fichier' La sortie d'erreur devient ce fichier. Il est vidé avant même le démarrage du processus.
- '2>>
nom-de-fichier' La sortie d'erreur devient ce fichier. Le fichier n'est pas vidé, ce qu'écrira le programme s'ajoutera à la fin.
- '2>&1'
La sortie des erreurs est mélangée avec la sortie standard. Rien ne sort donc de la sortie des erreurs.
- '>&2'
La sortie standard est mélangée avec la sortie d'erreur. Rien ne sort donc de la sortie standard.
| Avertissement |
|---|---|
Si un processus change l'entrée standard ou la sortie standard ce changement s'appliquera à l'ensemble de sa descendance. |
$cat ␣/etc/papersize␣/bin/toto␣/proc/version↵a4 cat: /bin/toto: No such file or directory Linux version 2.6.12 (root@lirispaj) (gcc version 3.3.5 (Debian 1:3.3.5-13)) #1 SMP Thu Jun 23 10:24:03 CEST 2005$cat ␣/etc/papersize␣/bin/toto␣/proc/version␣ >LaConcatenation↵cat: /bin/toto: No such file or directory$cat ␣/etc/papersize␣/bin/toto␣/proc/version␣ >LaConcatenation␣ 2>&1↵$
La commande grep est en fait un crible permettant de sélectionner des lignes dans les fichiers. Le critère de sélection est une chaine de caractère que l'on recherche dans chacune des lignes. Tous les exemples suivants recherchent les lignes contenant la chaine de caractère '4'.
$grep ␣ 4 ␣/etc/passwd↵sync:x:4:65534:sync:/bin:/bin/sync backup:x:34:34:backup:/var/backups:/bin/sh gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats/gnats-db:/bin/sh nobody:x:65534:65534:nobody:/nonexistent:/bin/sh identd:x:100:65534::/var/run/identd:/bin/false sshd:x:104:65534::/var/run/sshd:/bin/false$grep ␣ 4 ␣ </etc/passwd↵sync:x:4:65534:sync:/bin:/bin/sync backup:x:34:34:backup:/var/backups:/bin/sh gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats/gnats-db:/bin/sh nobody:x:65534:65534:nobody:/nonexistent:/bin/sh identd:x:100:65534::/var/run/identd:/bin/false sshd:x:104:65534::/var/run/sshd:/bin/false$grep ␣ 4 ␣/etc/passwd␣/etc/papersize↵/etc/passwd:sync:x:4:65534:sync:/bin:/bin/sync /etc/passwd:backup:x:34:34:backup:/var/backups:/bin/sh /etc/passwd:gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats/gnats-db:/bin/sh /etc/passwd:nobody:x:65534:65534:nobody:/nonexistent:/bin/sh /etc/passwd:identd:x:100:65534::/var/run/identd:/bin/false /etc/passwd:sshd:x:104:65534::/var/run/sshd:/bin/false /etc/papersize:a4$cat ␣/etc/passwd␣/etc/papersize␣ >xxx↵$grep ␣ 4 ␣ <xxx↵sync:x:4:65534:sync:/bin:/bin/sync backup:x:34:34:backup:/var/backups:/bin/sh gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats/gnats-db:/bin/sh nobody:x:65534:65534:nobody:/nonexistent:/bin/sh identd:x:100:65534::/var/run/identd:/bin/false sshd:x:104:65534::/var/run/sshd:/bin/false a4
Souvent une seule commande ne permet pas de faire ce que l'on veut. Dans ce cas, on peut appliquer une succession de transformations à un flot de données.
Le symbole pipe permet de faire un pipeline. La sortie standard de la commande de gauche est branchée sur l'entrée standard de la commande de droite. Les deux commandes sont exécutées en même temps. Le dernier exemple avec grep peut être écrit comme ceci :
$cat ␣/etc/passwd␣/etc/papersize␣ | ␣ grep ␣ 4↵sync:x:4:65534:sync:/bin:/bin/sync backup:x:34:34:backup:/var/backups:/bin/sh gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats/gnats-db:/bin/sh nobody:x:65534:65534:nobody:/nonexistent:/bin/sh identd:x:100:65534::/var/run/identd:/bin/false sshd:x:104:65534::/var/run/sshd:/bin/false a4$set ␣ | ␣ more↵Affichage paginé de la sortie de la commande set$set ␣ | ␣ grep ␣ X ␣ | ␣ sort↵Affiche dans l'ordre alphabétiques les lignes affichées par set contenant un caractère X
Cette écriture à de nombreux avantages :
C'est moins long à taper.
On n'a pas besoin de trouver un nom de fichier.
L'exécution est plus rapide car on n'utilise pas le disque et l'on fait éventuellement du parallélisme.
On peut faire des pipelines très long.
L'exemple suivant cherche les lignes qui contiennent 'add', 'd'
et 'x' dans tous les fichiers du répertoire /etc
dont le nom commence par 'c'.
$grep ␣ add ␣ /etc/c* ␣ | ␣ grep ␣ d ␣ | ␣ grep ␣ x↵grep: /etc/chatscripts: Permission denied /etc/complete.tcsh: proxy_rule redirect_address redirect_port \ /etc/complete.tcsh: prefix-addresses private-headers reloc section-headers \
Il est possible d'utiliser de calculer des arguments
en utilisant une autre commande.
La syntaxe est
$(une ligne de commande)
Ce morceau de programme sera remplacé par ce qui
aura été écrit sur la sortie standard de la ligne de commande.
$echo ␣ 'a ␣ ␣ ␣ ␣ b' ␣ >liste-de-noms-de-fichier↵$cat ␣ liste-de-noms-de-fichier↵a b$echo ␣ $(cat ␣liste-de-noms-de-fichier)↵a b$echo ␣ "$(cat ␣liste-de-noms-de-fichier)"↵a b$echo ␣ '$(cat ␣liste-de-noms-de-fichier)'↵$(catliste-de-noms-de-fichier)$cat ␣ $(cat ␣liste-de-noms-de-fichier)↵cat: a: No such file or directory cat: b: No such file or directory$cat ␣ "$(cat ␣liste-de-noms-de-fichier)"↵cat: a b: No such file or directory$A=$(cat ␣/etc/papersize)↵$echo ␣ $A↵a4
| Avertissement |
|---|---|
Historiquement, la syntaxe était
|
Il y a plusieurs manières de regrouper des commandes. Elles ont chacune leur utilité.
Il est souvent utile de lancer une succession de commandes au clavier. Remonter dans l'historique des commandes tapées est fastidieux si l'on veut exécuter systématiquement plusieurs commandes. On peut séparer les différentes commandes par un ';'. Elles seront exécutée les unes après les autres.
$echo ␣ a ␣ ; ␣ date ␣ ; ␣ echo ␣ b↵aWed Sep 7 17:17:55 CEST 2005b$echo ␣ a ␣ ; ␣ cat ␣toto␣ ; ␣ echo ␣ b↵acat: toto: No such file or directoryb
Dans les exemples indiqués dans la suite on peut toujours remplacer les points virgules par des retours à la ligne.
Dans l'exemple précédent on voit que l'exécution
continue même en cas d'erreur.
Si l'on veut qu'elle s'arrête on utilise l'opérateur
&&.
$echo ␣ a ␣ && ␣ cat ␣ toto ␣ && ␣ echo ␣ b↵acat: toto: No such file or directory
Parfois on veut mettre la sortie standard de plusieurs commandes dans un fichier. Plutôt que d'ouvrir plusieurs fois le fichier on peut regrouper les commandes en mettant des parenthèses et faire la redirection (ou le pipe) pour l'ensemble. Les trois ``suites´´ d'instructions suivantes font la même chose.
$echo ␣ Contenu ␣ de ␣ toto ␣ >xxx␣ ; ␣ cat ␣toto␣ >>xxx↵$(echo ␣ Contenu ␣ de ␣toto␣ ; ␣ cat ␣toto) ␣ >xxx↵$(↵>echo ␣ Contenu ␣ de ␣ toto↵>cat ␣toto↵>) ␣ >xxx↵
| Avertissement |
|---|---|
C'est un processus shell fils qui exécute ce qui est entre les parenthèses. Quand il se termine tout est perdu. |
$pwd↵/etc$A=a↵$export ␣ B=b↵$export ␣ C=c↵$( ␣ echo ␣ $A ␣ $B ␣ ; ␣ export ␣ C=cc ␣ ; ␣ cd ␣/␣ )↵b$pwd↵/etc$echo ␣ $C↵c
Les redirections s'appliquent au shell fils, les commandes qu'il exécute ont les mêmes fichiers d'entrée sortie que leur père.
$( ␣ echo ␣ Il ␣ est ␣ ; ␣ date ␣ ) ␣ >xxx↵$cat ␣xxx↵Il estFri Sep 16 10:30:42 CEST 2005$X=$(date ␣ | ␣ ( ␣ read ␣ A ␣ B ␣ ; ␣ echo ␣ $A ␣ ) ␣ )↵$echo ␣ $X↵Fri
Le ``shell´´ dans lequel vous tapez des commandes est un processus comme un autre. Chaque fois que vous lancez une commande un nouveau processus est lancé, lorsque la commande se termine le processus s'arrête (ses variables d'environnement sont perdues).
Si la commande est en fait un pipeline alors plusieurs processus seront lancé simultanément.
Si une commande prend beaucoup de temps pour s'exécuter
l'utilisateur ne pourra pas taper d'autres commandes.
Si l'on veut pouvoir continuer à travailler
il faut indiquer au shell que l'utilisateur veut
lancer le processus en ``arrière plan´´ (background).
Ceci est fait en mettant un '&'
à la fin de la commande ou du pipeline.
Le shell met un petit message quand la commande
se termine.
$ls ␣Stocke tous les noms de fichier dans 'xxx'-R␣/␣ >xxx␣ &↵[1] 5088C'est le premier processus en arrière plan, son PID est 5088$ls: /proc/1/fd: Permission deniedUn message d'erreur de ls s'affiche après le promptls: /etc/ssl/private: Permission denieddate↵L'utilisateur tape sa commande sans le prompt à gaucheThu Sep 8 15:15:32 CEST 2005$ls: /var/spool/cron/atjobs: Permission denieddate↵Thu Sep 8 15:19:42 CEST 2005[1]+ Done ls -R >xxxLe processus s'est arrêté entre les 2 dernières commandes tapées$
| Avertissement |
|---|---|
Si vous tapez
|
Ce sont elles qui vont nous permettre d'écrire simplement de tout petits programmes. Le langage shell n'est pas un langage générique il n'est pas fait pour développer des applications. Ces structures de contrôle vous sont présentées des plus couramment utilisés en ligne de commande jusqu'à celles qui le sont moins.
Les redirections indiquées après la fin de la structure de contrôle s'appliquent à toutes les commandes qui sont à l'intérieur.
Elle permet de faire prendre à une variable un ensemble de valeur parmi une liste donnée dans la ligne de commande. Pour chaque valeur, les commandes entre le do et le done sont exécutées.
$for ␣ TOTO ␣ in ␣ toto ␣ tata ␣ tutu ␣ ; ␣ do ␣ echo ␣ "<$TOTO>" ␣ ; ␣ done↵<toto><tata><tutu>$for ␣ TOTO ␣ in ␣ /b* ␣ "/b*" ␣ ; ␣ do ␣ echo ␣ "<$TOTO>" ␣ ; ␣ done↵</bin></boot></b*>
On peut remplacer les points virgules par des retours à la ligne si l'on veut écrire la boucle sur plusieurs lignes.
for ␣ I ␣ in ␣ $(date) ␣ ␣ do ␣ ␣ ␣ ␣ echo ␣ "$I" ␣ ␣ done
Tant que la commande exécutée en paramètre du while se termine sans erreur (est vrai, et donc retourne 0 contrairement à tous les langages de programmation existant) les instructions entre le do et le done sont exécutées.
$while ␣ read ␣ TOTO ␣ ; ␣ do ␣ echo ␣ "<$TOTO>" ␣ ; ␣ done ␣ </etc/aliases↵<postmaster: root><abuse: postmaster>$I=0↵$while ␣ test ␣ $I ␣ != ␣ 3↵>do ␣ echo ␣ "<$I>" ␣ ; ␣ I=$(expr ␣ $I ␣ + ␣ 1) ␣ ; ␣ done↵<0><1><2>
Le case permet d'exécuter une suite différente de commandes en fonction du paramètre.
$A=B$case ␣ "$A" ␣ in↵>␣ ␣ v1|[A-Z]*) ␣ echo ␣ v1_ou_commence_par_une_majuscule ␣ ;;↵>␣ ␣ *.gif) ␣ echo ␣ se_termine_par_gif ␣ ;;↵>␣ ␣ *) ␣ echo ␣ n_importe_quoi ␣ ;;↵>esac↵v1_ou_commence_par_une_majuscule
Les tests sont faits du début à la fin. Si un test réussi, alors on ne regarde pas les suivants.
Le sélecteur qui est utilisé à la gauche de la parenthèse est le même que pour le globbing mais en plus il autorise le '|' pour faire les 'ou' logique.
Les commandes shell sont extrêmement puissantes. Beaucoup de problèmes sont résolus en quelque lignes. Si ces problèmes reviennent souvent il est intéressant de ne pas retaper ces lignes. Pour cela on les met dans un fichier en utilisant un éditeur de texte quelconque. Pour exécuter les commandes qui sont dans le fichier il suffit de lancer l'exécution du fichier les contenant.
Voici quelques remarques sur les scripts en général, qu'ils soient en shell ou dans d'autres langages.
La première ligne du fichier doit donner le nom absolu du fichier exécutable contenant l'interpréteur du langage contenu dans le script. Dans le cas du shell cela sera :
#!/bin/sh
Le fichier contenant le script doit être exécutable. On peut le rendre exécutable en tapant :
$chmod ␣ 755 ␣mon-script.shIl est recommandé mais pas obligatoire de suffixer le nom du fichier par une extension indiquant le langage de programmation utilisé. L'inconvénient est que l'on doit taper le nom avec l'extension quand on veut l'utiliser.
Si le script se trouve dans un répertoire indiqué dans la variable
PATHalors il suffit de taper son nom pour exécuter les commandes qu'il contient. Sinon, il faut donner le nom relatif ou absolu du fichier.Pour lancer un script qui est dans le répertoire courant ('.' n'est pas dans
PATH) il faut taper./mon-script
Différences de fonctionnement quand des commandes s'exécutent dans un script :
Le prompt n'apparaît pas après l'exécution de chaque commande.
La variable '@' contient tous les arguments de lancement du script. Pour parcourir tous les arguments du script la syntaxe fiable doit utiliser les guillemets
for I in "$@" ; do ... ; done
La variable nommée '1' contient seulement le premier, '2' le deuxième, ...
Le prompt n'apparaît pas après l'exécution de chaque commande.
Dans les scripts, les structures de contrôle sont écrites sur plusieurs lignes et indentées.
Si la ligne commence par '#' ou bien s'il y a ' ␣ #' dans la ligne ce qui suit est un commentaire. C'est aussi vrai en interactif, donc le '#' est un caractère spécial qu'il faut protéger par des guillemets si l'on veut vraiment l'utiliser.
La commande builtin exit permet de terminer le shell en indiquant une valeur de retour (0 = OK).
Il ne faut plus utiliser $* qui est
obsolète et dangereuse.
elle fait la même chose que $@
à la différence près que "$*" représente
une seule valeur alors que "$@"
en représente une par argument.
Seules les commandes les plus utiles sont ici. Il faut utiliser le manuel pour avoir des détails sur les commandes ou en trouver de nouvelles.
Certain concepts sont communs à de nombreuses commandes. Ils sont présentés séparément.
Voici quelques informations qui concernent le fonctionnement de beaucoup de commandes.
Les expressions régulières permettent d'identifier des morceaux de texte dans un texte afin de les afficher ou de les remplacer. Elles sont utilisées par de nombreuses commandes dont grep, vi, emacs, sed, awk mais aussi elles sont utilisables dans de nombreux langages de programmation (Perl, JavaScript, Python, C...). Quelques concepts généraux :
On identifie le morceau de texte le plus au début de la chaine.
On identifie le morceau de texte le plus long possible quand il y a plusieurs choix possibles.
Par défaut le morceau identifié est sur une seule ligne.
Le vocabulaire des expressions régulières.
'.' remplace n'importe quel caractère.
'[listes]' comme pour le shell mais la négation est le '^' au lieu du '!'
'*' Répète ce qui précède un nombre de fois entre 0 et l'infini.
'\' Annule la signification du caractère suivant. Donc '\*' représente une étoile et non le multiplicateur d'expression.
'^' Représente le début de la ligne.
'$' Représente la fin de la ligne.
Le expressions régulière étendues ont beaucoup plus de possibilités, les symboles les plus courants :
'(.....)' forme un groupe qui est manipulé en bloc (pas découpé)
'+' Répète ce qui précède un nombre de fois entre 1 et l'infini.
'?' Répète ce qui précède 0-1 fois.
'|' remplace ce qui est à gauche ou à droite. Il est conseillé de le mettre dans un groupe.
'\1' représente la même chose que le groupe 1 (ou 2, 3, ...) dans l'ordre de lecture de l'expression.
'&' existe pour certaines applications, il représente l'ensemble de ce qui à été trouvé.
Exemples :
| Un texte | Expression recherchée | Type |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | i | |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | .* | |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | \* | |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | [0-9]+ | étendue |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | [0-9a-z]+ | étendue |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | [0-9]+|[a-z]+ | étendue |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | [0-9]+ | non étendue |
| Les nombres sont trouvés mais aussi tous les espaces inter-lettre | [0-9]* | |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | (.*) | non étendue |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | (.*) | étendue |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | ([^)]*) | non étendue |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | [a-zA-Z_]+\( | étendue |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | [a-zA-Z_]+[ ␣ \t]*\( | étendue |
| for ␣ (i=0; ␣ i!=*m1n; ␣ i++) ␣ printf("%d\n", ␣ 5+i) ␣ ; | ([a-z0-9])[^()]*\1 | étendue |
L'internationalisation (I18N) est ce qui permet aux logiciels de travailler dans n'importe quelle police de caractères existantes dans le monde (passé, présent et imaginaire). Chaque symbole possède un numéro dans la table Unicode standard. Ces numéros peuvent être codés de plusieurs façons, la plus courante est l'UTF8.
La localisation (L10N) défini la manière d'afficher certaines informations comme les nombre décimaux, les dates, les unités monétaires, ... Mais aussi les méthodes de changement de casse et de tri.
Adapter un logiciel à chaque culture est un problème énorme car le logiciel doit être testé dans toutes les langues. Les logiciels sont toujours plus stables et faciles à utiliser quand ils le sont dans la langue pour laquelle ils ont été développés initialement.
La commande locale affiche la localisation choisie pour chaque fonctionnalité.
La commande locale ␣
-aaffiche les localisations installées sur le système.export ␣
LC_ALL=POSIX est ce qui est le plus sûr d'utilisation. La langue sera celle dans laquelle le logiciel a été écrit.export ␣
LC_MESSAGES=french Les messages seront affichés en français mais par exemple les nombres décimaux seront affichés avec le point plutôt que la virgule.
Les configurations des différents logiciels pour un utilisateur donné sont stockées dans le répertoire de connexion de l'utilisateur. Dans un fichier ou un répertoire dont le nom commence par '.'. Le format du contenu de ces fichiers est spécifique à chaque application.
.profileou.bash_profileCe fichier est un script shell qui est exécuté par le shell chaque fois que l'utilisateur se connecte.
.emacs.d/init.elCe fichier est un script lisp (le langage dans lequel emacs est majoritairement écrit) qui est exécuté par emacs chaque fois qu'il est lancé.
.exrcCe fichier est une liste de commandes vi qui est exécutée par vi chaque fois qu'il est lancé.
.mozillaCe répertoire contient les nombreux fichiers de données et les configurations de mozilla et des autres outils de sa famille (firefox, thunderbird, netscape).
.gconfCe répertoire contient les configurations des logiciels utilisant les bibliothèques Gnome.
.kdeCe répertoire contient les configurations des logiciels utilisant les bibliothèques KDE.
.configCe répertoire contient les configurations des logiciels indépendants des bibliothèques précédentes.
Tout ce qui concerne les fichiers eux-mêmes et non leur contenu.
Liste des informations sur les fichiers et répertoires.
-sAffiche la taille en nombre de blocs utilisés sur le disque.
-lAffiche plus d'informations.
-Rou--recursiveAffiche l'arbre entier.
-tTrie les fichiers suivant la date affichée.
-uAffiche la date d'utilisation plutôt que la date de modification.
-rInverse l'ordre du tri.
-dAffiche les informations sur les répertoires plutôt que sur leur contenu.
Destruction de fichiers et répertoires. La commande rmdir ne permet que de détruire un répertoire vide.
-rou--recursiveDétruit tout récursivement.
-fDétruit sans poser de question.
-iDétruit en demandant confirmation avant chaque destruction.
-rou-Rou--recursiveCopie récursive, le dernier argument ne doit pas être un nom de fichier. S'il y a plusieurs choses à copier, elles vont dans le répertoire destination qui doit exister. Si une seule chose est à copier, elle remplace la destination si celle-ci existe.
-pPréserve si possible les informations sur le fichiers (dates, droits, ...)
-dCopie les liens symboliques plutôt que le contenu du fichier pointé.
-aRaccourci pour
-Rpd. C'est l'option conseillée pour faire des copies les plus exactes possible.-u(update)Ne fait la copie sur un fichier existant que si la nouvelle version est plus récente que le fichier existant.
Déplace des fichiers et répertoires.
C'est un renommage plutôt qu'une copie.
La sémantique est la même que pour la commande cp.
Les options -i et -f
ont le même sens que pour la commande rm.
L'option -R indique la récursion.
chmod ␣ 750 ␣ toto ␣ titi ␣ Met le moderwxr-x---aux deux fichiers chmod ␣ u+wx ␣ toto ␣ titi ␣ Ajoute les droitswetxpour le propriétaire chmod ␣ go-w ␣ toto ␣ titi ␣ Enlève le droit d'écriture au groupe propriétaire et aux autres (other) chmod ␣-R␣ a+X ␣ . Ajout récursif du bit x s'il était déjà présent pour l'un des 3 (a≡ugo)
L'option -R indique la récursion.
chown ␣ exco ␣ toto ␣ titi ␣ Le propriétaire des deux fichiers devientexcochgrp ␣ liris ␣ toto ␣ titi ␣ Le groupe propriétaire des deux fichiers devientliris
Le premier but de la commande ln est de permettre de donner plusieurs noms au même fichier (pas répertoire). Le fichier existe tant qu'il porte encore un nom. Les différents donnent accès au même contenu même s'il est modifié. Tous les noms du fichier sont au même niveau, il n'y en a pas un plus important qu'un autre. Ce liens est appelé lien hard, il est peu usité, il permet par exemple de partager l'accès de manière sécurisé à un fichier sans créer un groupe spécial.
$echo ␣ Bonjour ␣ >xxx$ln ␣xxx␣yyy$cat ␣yyyBonjour$echo ␣-n␣ ... ␣ >>yyy$cat ␣xxxBonjour...$echo ␣-n␣ toi ␣ >>xxx$cat ␣yyyBonjour...toi$rm ␣xxx$cat ␣yyyBonjour...toi
Le liens symbolique :
Le lien symbolique est indiqué avec l'option
-sde la commande lnIl est asymétrique, le second fichier est un raccourci vers le premier fichier.
Le premier fichier n'existe pas obligatoirement.
Si le premier fichier est désigné par un chemin relatif alors il est relatif par rapport au répertoire contenant le liens symbolique et non le répertoire courant du processus.
$ln ␣Un raccourci vers-s␣/usr/include/stdio.h␣stdio.hstdio.hest créé dans le répertoire courant.$ln ␣Le raccourci-s␣../xxx␣/tmp/toto/tmp/totopointe sur/xxx
Accroche ou décroche des systèmes de fichiers à la hiérarchie des fichiers. Les exemples suivants fonctionnent pour le super-utilisateur (root), Pour les media amovibles, le gestionnaire de fichier les monte normalement sans intervention de l'utilisateur.
mount ␣/dev/sda1␣/media/MaClefUSBumount ␣/media/MaClefUSBmount ␣ UnServeurNFS:/UnRépertoire␣/homeDistant
| Avertissement |
|---|---|
Il faut toujours démonter avec umount (ou en utilisant la souris) avant d'enlever un media amovible. En effet, on effet, la copie des informations sur les supports physiques n'est certaine qu'un fois que le démontage est réussi. |
df affiche la liste des systèmes de fichiers accrochés
à la hiérarchie des fichiers.
Pour chacun, on obtient le nom du périphérique,
l'endroit où on accroche le système de fichier,
la place totale, utilisée et libre en nombre de kilo-octets.
L'option -h permet d'avoir un affichage
plus lisible par un être humain (avec des Mega/Giga/Tera/Peta octets).
Cette commande souvent utilisée dans les if et while
est aussi nommée crochet ouvrant : [.
Elle évalue l'expression indiquée par ses paramètres
et retourne vrai ou faux en conséquence.
Attention, le vrai en shell c'est quand
la commande retourne 0 indiquant qu'elle c'est
bien passée. C'est le contraire du C
Quelques exemples d'utilisation les plus courants en utilisant le nom test ou crochet. Les espaces sont fondamentaux.
test ␣ "oui" ␣ = ␣ "$REPONSE" Vrai si égalité textuelle test ␣ "5" ␣ -eq ␣ "$REPONSE" Vrai si égalité numérique ('5 ' = '5' est faux) test ␣ "5" ␣ -lt ␣ "$REPONSE" Vrai si 5 < $REPONSE [ ␣ -e ␣ "$F" ␣ ] Vrai si l'entité $F existe [ ␣ -f ␣ "$F" ␣ ] Vrai si le fichier $F existe [ ␣ -d ␣ "$F" ␣ ] Vrai si le répertoire $F existe
La commande find permet de trouver des fichiers dans une hiérarchie. La syntaxe est complexe, de manière simplifiée, on peut considérer que les paramètres sont dans l'ordre :
des noms de répertoire ou l'on cherchera.
une expression comportant des tests, entre autres :
-name␣ patternL'expression est vrai si le nom trouvé correspond au pattern. C'est la même syntaxe que pour le globbing.
-iname␣ patternIdem, mais ne tient pas compte de la casse (différence minuscule/majuscule)
-size␣ +999kVrai si la taille du fichier est plus grande que 999 kilo octets. On peut mettre - au lieu de plus pour dire plus petit.
-type␣ fVrai si c'est un nom de fichier texte (f). Si c'est 'd' alors c'est répertoire. Voir la documentation pour les autres types de fichier.
-oFait un ``ou´´ entre l'expression de gauche est celle de droite. Il fait mettre des parenthèses autour pour regrouper les opérateurs. Attention, il faut protéger les parenthèses en mettant des guillemets ou des backslashs.
-aC'est le ``et´´ (and) entre expressions. Il est facultatif.
une action à réaliser lorsque le fichier est trouvé.
-printAffiche le nom trouvé sur la sortie standard en ajoutant un
\naprès.-print0Affiche le nom trouvé sur la sortie standard en ajoutant un NUL (
\0) après.-exec commande arguments \;Exécute la commande indiqué en remplaçant les occurrences de
{}par le nom du fichier trouvé.
Exemples d'utilisations courants dans le répertoire courant :
- Affiches les fichiers
.cou.h find ␣ . ␣
-name␣ '*.[ch]' ␣-print- Trouve les fichiers de plus d'un méga-octets modifiés ce mois
find ␣ . ␣
-size␣ +1000k ␣-mtime␣ -30 ␣-print- Affiche des informations sur les images.
L'option
-dest là en cas de répertoire. find ␣ . ␣ \( ␣
-iname␣ '*.jpg' ␣-o␣-iname␣ '*.png' ␣-o␣-iname␣ '*.gif' ␣ \)\↵-exec␣ ls ␣ -lsd ␣ {} ␣ \;- Détruire les fichiers de sauvegarde vieux de plus d'une semaine.
find ␣ . ␣ \( ␣
-name␣ '*.bak' ␣-name␣ '*~' ␣ \) ␣-mtime␣ +7 ␣-exec␣ rm ␣ {} ␣ \;
Les exemples précédents s'exécutent lentement
car la commande est exécutée pour chaque fichier trouvé.
Souvent on peut exécuter la commande avec plusieurs
noms de fichier à la fois.
C'est le travail de la commande xargs qui
va appeler un autre commande en lui mettant
plusieurs arguments.
Pour détruire tous les fichiers .bak:
find ␣ . ␣-name␣ '*.bak' ␣-print0| xargs ␣-0␣ rm ␣-f
On utilise les options -0 et
-print0 pour que les noms de fichier soient
séparés par un code \0.
Ainsi on pourra traiter des noms de fichiers
absolument quelconque, même contenant des retours
à la ligne.
Si les noms de fichiers sont normaux
et que l'on ne veut pas forcer la destruction,
on peut taper la commande plus courte suivante.
find ␣ . ␣ -name ␣ '*.bak' | xargs ␣ rmLa commande xargs est intelligente, si les noms à ajouter sur la ligne de commande sont trop nombreux, elle fera le travail en plusieurs fois. En effet, la longueur des commandes que l'on peut taper est limité.
| Avertissement |
|---|---|
La commande suivante ne fonctionne pas s'il y a beaucoup de fichiers (ou si les fichiers contiennent des espaces). rm ␣ $(find ␣ . ␣ |
Fondamentale pour le développement, elle affiche
les différences entre deux fichiers et vous permet
donc de savoir ce qui a changé entre une version qui
marche et une qui ne marche pas.
L'option -u fait un affichage plus lisible.
C'est cette commande qui permet de générer des patchs (rustine en français) permettant de mettre des ensembles de fichiers à jour sans tout retransférer.
La commande patch permet d'appliquer des changements à un fichier même si le fichier ne correspond plus exactement au fichier de départ. Cela permet de fusionner (to merge en anglais) des modifications faites par différentes personnes sur le même fichier initial.
L'utilisateur A envoie les fichiers
APPLICATION/xxx,APPLICATION/yyyetAPPLICATION/zzzà d'autres utilisateurs X, Y, ...Les utilisateurs X, Y, ... recopient le répertoire
APPLICATIONet son contenu sous un autre nom, par exempleAPPLICATION.X, ...Les utilisateurs X, Y, ... modifient chacun de leur coté le contenu des fichiers, il peuvent aussi en ajouter et en détruire. Il modifient dans le répertoire
APPLICATION.X, ...Une fois le travail terminé, les utilisateurs retournent leur travail à A sous la forme d'un patch. La commande suivante crée le fichier
X.diffqui contient le patchdiff ␣
-Naur␣ APPLICATION ␣ APPLICATION.X ␣ >X.diffL'utilisateur A récupère donc des fichiers patch venant de X, Y, ... Il doit fusionner leur travail en faisant :
patch ␣
-p0␣ <X.diff patch ␣-p0␣ <Y.diff ...Si les utilisateurs ont modifiés des zones différentes des fichiers alors l'ensemble de leurs modifications sera fusionné.
L'utilisateur A peut alors envoyer la nouvelle version à tous le monde.
Les systèmes de développement collaboratif comme SVN, GIT, Mercurial rendent invisible cette notion de patch aux différents participants du projet.
Tout ce qui concerne la manipulation des contenus de fichier. Les commandes manipulant des fichiers utilisent leur entrée standard si on ne leur a pas donné de fichiers à traiter. Parfois il faut explicitement nommer l'entrée standard : '-'
Ces deux commandes permettent de transformer une hiérarchie de fichier en un seul fichier et inversement. Ceci à de nombreux avantages : cela prend moins de place, c'est plus facile à manipuler, cela peut mieux se comprimer, cela permet de stocker ce fichier sur n'importe quel type de système de fichier, par exemple une clef USB.
- Créer une archive
tar ␣
-cvf␣MonRépertoireVersion-1.2.tar␣ MonRépertoireVersion-1.2-cindique create.-vindique verbose.-findique que l'on va donner le nom du fichier archive.Avertissement Ne faites jamais d'archive du répertoire
.car cela oblige la personne qui extrait les fichiers à créer un répertoire avant.Ne faites jamais d'archive avec un nom absolu. On ne peut pas les extraire ou l'on veut.
- Regarder le contenu d'une archive
tar ␣
-tvf␣MonRépertoireVersion-1.2.tar-tindique que l'on veut voir le contenu sans l'extraire.- Extraire le contenu d'une archive
tar ␣
-xvf␣MonRépertoireVersion-1.2.tar-xindique que l'on veut eXtraire. L'extraction est faite dans le répertoire courant.
Utilisable comme un filtre ou pour comprimer un ou plusieurs fichiers ou les fichiers d'une hiérarchie.
gzip ␣totoRemplacetotopar sa version compriméetoto.gzgunzip ␣toto.gzRemplacetoto.gzpar sa version décompriméetotogzip ␣ <toto␣ >toto.gzCréation detoto.gzsans quetotodisparaisse gunzip ␣ <toto.gz| grep ␣ truc Décomprimetoto.gzen affichant seulement les lignes contenanttructar ␣-cvf␣-␣ MonRépertoireVersion-1.2 | gzip ␣ >MonRépertoireVersion-1.2.tar.gzgunzip ␣ <MonRépertoireVersion-1.2.tar.gz| tar ␣-xvf␣-
L'option -0 permet de compresser
rapidement (mais mal) et l'option -9
permet de comprimer efficacement (mais lentement).
La commande bzip2 est plus efficace mais par forcément installée par défaut sur toutes les machines (en 2008).
cut permet d'afficher une ou des colonnes
de caractères ou de valeurs de fichiers.
paste permet de les recoller ensemble.
L'option -d
permet de définir le séparateur de colonnes.
L'option -f
permet de définir le ou les colonnes à extraire.
cut ␣-d␣ : ␣-f␣ 1 ␣/etc/passwdExtrait les noms d'utilisateur
Prend les dernières ou premières lignes d'un fichier.
tail ␣ -f
permet de voir la fin d'un fichier et
elle reste bloquée en affichant au fur et à mesure ce
qui est ajouté au fichier.
C'est très utile pour surveiller un fichier de "log" qui grossi.
Permet d'afficher l'entrée standard ou le contenu des fichiers indiqués en triant les lignes. On peut choisir les colonnes qui seront les clefs du tri. En sortie, toutes les colonnes seront présentes et le contenu des lignes sera inchangés.
-t␣ un-caractèreDéfini le caractère séparateur.
-nOn trie des nombres et non du texte
-kpremière-colonne[,dernière-colonne]Indique les colonnes à trier
Ce programme est issu de 'ed' qui est le premier éditeur de texte sous UNIX. Quand on utilise 'ed' pour éditer de manière automatique un fichier chaque commande que l'on fait s'applique à l'ensemble du fichier ce qui est gênant quand le fichier est plus gros que la mémoire de l'ordinateur. sed lit le fichier ligne par ligne et applique successivement les commandes sur chacune des lignes. 99.9 des utilisations faites sont de la forme :
sed ␣-e␣ "s/regex/.../g" ␣-e␣ "s/regex/.../g" ␣ ...autres remplacements...
Pour les expressions régulières étendues,
il faut ajouter l'option -r.
C'est un langage de programmation ressemblant au C qui comme 'sed' analyse les fichiers lignes par ligne. Il supporte les tableaux indexés par des chaînes de caractères au lieu de simples entiers. Exemples simples :
Affiche la ligne la plus longue de/etc/passwd$awk ␣ </etc/passwd␣ '{ if (length($0) > MAX) { MAX=length($0) ; M=$0 ; } } END { print M; }'↵cyphesis:x:107:65534:Cyphesis C++ Administrator,,,:/usr/share/cyphesis:/bin/bashAffiche les lignes entre DEBUT et FIN$awk ␣ '↵>/^DEBUT$/ { A=1 ; next ; }↵>$0=="FIN" { A=0 ; }↵>A==1 { print $0 ; }'↵
Quelques outils permettant d'utiliser le réseau.
Permet de se connecter sur une autre machine. Le shell que l'on obtient après avoir indiqué son nom et mot de passe s'exécute sur l'autre machine et la machine sur laquelle vous avez tapé la commande.
ssh ␣ nom-de-machineOn peut demander à exécuter un script shell sur une machine distance :
ssh ␣ nom-de-machine ␣ "pwd;ls;hostname"L'exemple suivant permet de copier une hiérarchie de fichiers de la machine locale sur la machine distante tout en comprimant les données transmises pour utiliser le moins de débit sur le réseau.
tar ␣-cf␣-␣MonRépertoire| gzip | ssh ␣ nom-de-machine ␣ "gunzip | tar ␣-xvf␣ -"
| Avertissement |
|---|---|
La commande telnet ne crypte pas les échanges. On peut donc vous volez votre mot de passe. |
L'utilitaire standard pour échanger des fichiers entre machine. Les navigateurs web utilisent le même protocole quand l'URL commence par 'ftp:'
| Avertissement |
|---|---|
La commande ftp ne crypte pas les échanges. On peut donc vous volez votre mot de passe. |
Permet de copier des fichiers entre machines différentes si vous avez un compte sur les deux machines. Les noms des fichiers sont préfixés par le nom de la machine ou ils se trouvent.
La syntaxe de scp est la même que celle de cp
à la différence que le nom du fichier peut être préfixé
par nom-de-machine:
scp ␣toto␣ machine-distante:titiscp ␣-rp␣ machine-distante:/usr/include␣CopieDeIncludescp ␣ machine-distante-1:toto␣ machine-distante-2:.
| Avertissement |
|---|---|
La commande rcp ne crypte pas les échanges. On peut donc vous volez votre mot de passe. |
Permet d'envoyer un mail par ligne de commande. Permet aussi de lire son mail local en ligne de commande.
L'envoi de mail par ligne de commande permet d'écrire des scripts envoyant des messages automatiquement pour prévenir de problèmes qui se sont produits durant une exécution de nuit ou bien pour faire de l'envoi de messages personnalisés à une liste de personnes.
echo ␣ "Je suis le texte du message" | mail ␣ -s ␣ "Je suis le sujet du message" toto@titi.comNon classable.
Regarder des informations modifiées en temps réel. L'utilisation est simple, vous passez en paramètre le script shell que vous voulez exécuter régulièrement et la commande watch vous affiche le résultat sur l'écran.
watch ␣ "df;ls ␣ -l"Manipulation de nom de fichier. 'expr' permet de faire des calcul mais aussi de faire des manipulations simple sur les chaînes de caractères.
$dirname ␣/usr/include/stdio.h↵/usr/include$dirname ␣usr/include/stdio.h↵usr/include$dirname ␣stdio.h↵.$basename ␣/usr/include/stdio.h↵stdio.h$basename ␣/usr/include/stdio.h␣ .h↵stdio
Ces commandes permettent de gérer les impressions et lister les imprimantes. Suivant la version d'UNIX ce sont les unes ou les autres qui seront utilisées.
Pour éviter toute surprise (et gaspillage), il est conseillé de convertir les fichiers en PostScript, et d'afficher le PostScript à l'écran avant d'imprimer.
lp ␣ output.psOn détruit une impression en faisant :
lprm ␣ numéro-d-impressionGrosse applications interactives. Elles sont pratiques mais elles sont difficiles sinon impossible à intégrer dans des scripts pour fabriquer ses propres commandes.
Les commandes qui suivent ne font pas partie d'Unix mais sont des outils qui lui sont souvent associé.
Si votre machine est bien configurée, le navigateur web sait quelle application il faut lancer.
| Extension | Commentaire | Applications |
| .html | Navigation web | firefox, konqueror, mozilla, opera |
| .tex, .latex | Langage de formatage de texte | tex, latex |
| .man .1 .2 | Langage de formatage de texte | nroff, troff, groff |
| .doc | Format de fichier fermé | OpenOffice, Abiword |
| .rtf | Version plus ouverte des .doc | OpenOffice, Abiword |
| .xls | Format de fichier fermé | OpenOffice, gnumeric |
| .ppt | Format de fichier fermé | OpenOffice |
| .ps | Langage PostScript | gv, gs, display |
| .gif .png .jpg ... | Images |
Affichage : display, eog, gthumb, ... Palette graphique : gimp Traitement en ligne de commande : convert, netpbm |
| .mpg .avi .mp4 | Video | vlc, xine, totem |
| .mp3 .ogg .au | Son | Enregistrement, édition, codage : audacity |
| .svg | Scalable vector graphic | inkscape |
| Textes | vi, emacs, xemacs, ... |