L'objectif du TP est de mettre en place les éléments qui
permettent de faire du rendu différé, repassez dans "rendu
différé / direct ?" si tout ça n'est pas très clair. Il y a
plusieurs étapes, un peu techniques, avant de démarrer : créer et
configurer un framebuffer et ses textures pour stocker les
informations nécessaires au rendu, ie le G-Buffer et bien sur
compiler un compute shader et configurer ses entrées et surtout
(c'est la grosse nouveauté) ses sorties.
vous pouvez utiliser les utilitaires de texture.h pour créer simplement les textures nécessaires, cf make_depth_texture() ou make_vec3_texture(), etc. elles sont faites exactement pour ça !
la configuration se fait en plusieurs étapes : on commence par la
création des textures pour stocker les données, puis la
configuration du framebuffer. il faut associer les textures aux
sorties du framebuffer avec glFramebufferTexture() et associer les
sorties du fragment shader aux sorties du framebuffer avec
glDrawBuffers()
les explications détaillées sont dans la doc en ligne : "framebuffer
object"
au final, votre code ressemblera à :
// creation des textures pour stocker le GBuffer
GLuint zbuffer= make_depth_texture( /* unit
*/ 0, /* width */ 256, /* height */ 256 );
GLuint position= make_vec3_texture( /*
unit */ 0, /* width */ 256, /* height */ 256 );
GLuint normal= make_vec3_texture( /* unit
*/ 0, /* width */ 256, /* height */ 256 );
...
// configuration du framebuffer
GLuint framebuffer= 0;
glGenFramebuffers(1, &framebuffer);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER,
framebuffer);
glFramebufferTexture(GL_DRAW_FRAMEBUFFER,
/* attachment */ GL_DEPTH_ATTACHMENT, zbuffer, /* mipmap */
0); // associe une texture a la sortie zbuffer
du frambuffer;
glFramebufferTexture(GL_DRAW_FRAMEBUFFER,
/* attachment */ GL_COLOR0_ATTACHMENT, position, /* mipmap */
0); // associe une texture a la sortie 0
glFramebufferTexture(GL_DRAW_FRAMEBUFFER,
/* attachment */ GL_COLOR1_ATTACHMENT, normal, /* mipmap */
0); // associe une texture a la sortie 1
...
// configuration des sorties du fragment shader
//
binding
0
binding
1
etc
GLenum buffers[]= { GL_COLOR_ATTACHMENT0,
GL_COLOR_ATTACHMENT1 };
glDrawBuffers(2, buffers);
// verification de la configuration du framebuffer
if(glCheckFramebufferStatus(GL_DRAW_FRAMEBUFFER) !=
GL_FRAMEBUFFER_COMPLETE)
return
"error";
// nettoyage...
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);
render( ) :GLuint read_framebuffer;
glGenFramebuffers(1, &read_framebuffer);
glBindFramebuffer(GL_READ_FRAMEBUFFER, read_framebuffer);
glFramebufferTexture(GL_READ_FRAMEBUFFER, /* attachment */ GL_COLOR_ATTACHMENT0, /* texture a copier */ , /* mipmap */ 0);
glReadBuffer(GL_COLOR_ATTACHMENT0);
// copie vers le framebuffer par defaut / la fenetre
glBindFramebuffer(GL_READ_FRAMEBUFFER, read_framebuffer);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);
glBlitFramebuffer(/* source */ 0,0, 1024,1024, /* destination */ 0,0, 1024,1024, GL_COLOR_BUFFER_BIT, GL_NEAREST);
bravo ! vous savez manipuler tous les ingrédients techniques. il
ne reste plus qu'à modifier le compute shader pour calculer la
couleur de chaque pixel du G-Buffer.
question :
est ce que tout ça est plus rapide que la 1ere version directe
de votre code ?
dans quels cas le G-Buffer + compute est plus rapide ? et dans
quel cas est-il plus lent ?
exercice : petit G-Buffer.
au lieu de stocker la position dans une texture, il est tout a
fait possible de recalculer la position, on connait le zbuffer.
dans quel cas sera-t-il interessant de limiter le volume de
données écrit par chaque fragment ?
rappel : chaque fragment remplit le G-Buffer, si plusieurs
triangles se projettent sur le même pixel, on écrit plusieurs fois
les informations d'un pixel.
bonus : G-Buffer compact.
quelles informations doit on vraiment conserver dans le G-Buffer ?
peut-on les compresser pour réduire la représentation d'un pixel ?
et si l'objet et les paramètres de la matière sont texturés ?
comment mesurer l'impact de la compression sur l'exécution du
rendu différé ?
pour les curieux : un peu de lecture, par exemple comment
"rainbow
six | siege" GDC2016 fait son rendu et quel format de
G-Buffer il utilise, + comment il interpole ou calcule ses
pixels...
si le rendu est toujours trop lent, que peut-on faire de plus ?
une idée est de limiter le nombre de source de lumière qui peut
influencer chaque fragment, cf les bonus, une autre solution
consiste à ne pas calculer tous les pixels du G-Buffer : en
choisissant d'interpoler les pixels voisins à la place.
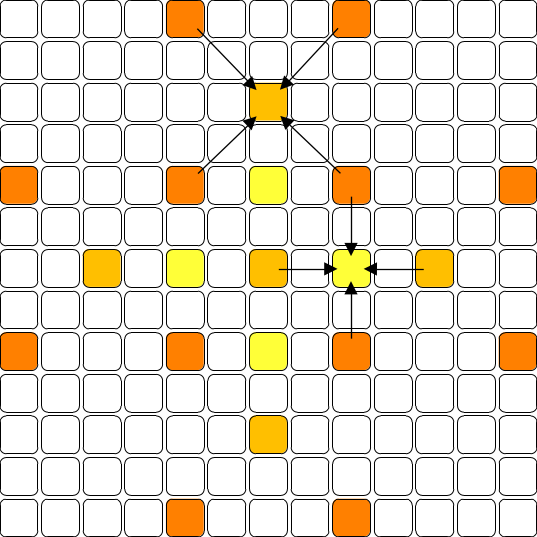
on commence par calculer 1 pixel sur 16 dans l'image, ensuite, il
faut décider d'interpoler ou de calculer chaque pixel d'un bloc de
5x5 pixels. il y a 2 étapes : d'abord calculer ou interpoler le
pixel au centre du bloc, puis calculer / interpoler les pixels au
milieu de chaque arête du bloc (en utilisant les voisins
horizontaux et verticaux) :
pour calculer / interpoler les pixels du bloc, on doit quand même
accéder aux blocs voisins :
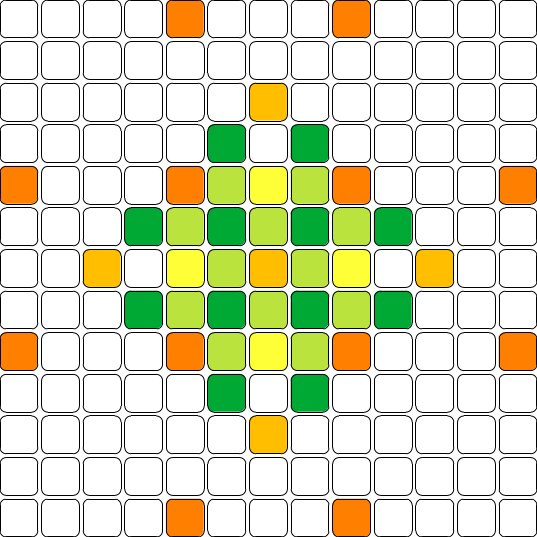
et on recommence pour les 4 petits blocs 3x3 de chaque bloc pour
compléter l'image.
pour décider d'interpoler ou pas, on peut calculer la variance
des 4 couleurs et la comparer à un seuil. par exemple si a,
b, c et d sont des couleurs :
Color s= ( a+b+c+d ) / 4;
Color ss= ( a*a+b*b+c*c+d*d ) / 4;
float v= gray(ss - s*s);
avec la conversion en luma
:
float gray( const Color& color ) { return float(0.21) * color.r + float(0.71) * color.g + float(0.08) * color.b; }
l'interpolation est une simple moyenne dans ce cas (et oui, on
vient juste de la calculer pour évaluer la variance, cf la
variable s)
et ça marche ?
voila la variance calculée pour chaque pixel :

et voila les résultats avec un seuil de 1/100 (à gauche) et de
1/1000 (à droite) :


(zoomez sur les images pour voir les défauts de reconstruction,
l'image vient de Alan
Wake 2)
pas mal non, pour 1% et 7% des pixels de l'image calculés (sans
compter la premiere passe) ? (même s'il reste des défauts)
en fonction du seuil, on peut vraiment ne calculer que quelques
pixels ou presque tous.
les détails complets sont dans "Deferred
Adaptive Compute Shading" HPG 2018 et aussi dans sa suite
publiée en 2020.
bien sur, toutes les scènes / images ne présentent pas la même
structure / densité de contours marqués. le réglage du seuil pour
obtenir une reconstruction de bonne qualité, sans calculer tous
les pixels, peut etre assez délicat. voici la variance de 2 images
bien différentes tirées de Black
Myth Wukong :


comment programmer efficacement cette technique ? quel est le
problème fondamental ?
question :
combien de threads s'exécutent simultanément si tous les pixels
d'un groupe sont calculés ? si tous les pixels d'un groupe sont
interpolés ?
et dans le cas normal (ie des pixels sont interpolés et d'autres
sont calculés...) ?
question :
si tout ça parait trop compliqué, que pensez-vous du checkerboard
rendering proposé par ubisoft dans "rainbow
six | siege" ?
quelles sont les différences principales ? quel pourcentage des
pixels sont calculés ?
question :
que pensez vous de la solution utilisée dans "call
of duty: modern warfare" ?
quelles sont les différences principales ? quel pourcentage
des pixels sont calculés ? est-ce efficace ?
quelle technique permet de rendre les acces mémoire cohérents ?
exercice : premier essai
écrivez un compute shader qui réalise une passe de calcul : ie qui
teste 4 pixels voisins et décide d'interpoler ou de calculer la
couleur.
comment enchainer l'exécution des passes de calcul ? combien
faut-il de passes de calcul ?
indication : la position des voisins change à chaque passe
de calcul, comment paramétrer le shader ? (et n'écrire qu'un seul
shader)
question :
peut-on écrire un seul shader qui enchaine toutes les passes ?
quel serait l'interet de cette solution ?
exercice : restructuration des calculs / des accès
mémoire
proposez une solution plus cohérente.
peut-on utiliser la mémoire partagée ? quel serait l'interet ?
exercice : et si on changeait un peu la méthode ?
un inconvénient de la méthode vient du test "interpole / calcule"
réalisé pour chaque pixel. l'exécution est donc plutot incohérente
et il serait plus simple et plus efficace de décider lors de la
toute première passe quels pixels calculer. les passes suivantes
ne feraient donc qu'interpoler et leur exécution serait cohérente.
problème : comment décider à priori de calculer certains pixel ?
quels critères peut-on utiliser ? quel sera l'impact sur l'image
finale ?
cf la presentation "Clustered
Deferred and Forward Shading" ou l'article
une autre solution consiste à ne pas faire tous les calculs à
chaque image lorsqu'ils sont trop longs et que l'application
affiche moins de 60 images par seconde. l'idée est de répartir les
calculs sur 4 ou 8 images pour permettre d'afficher 60 images par
seconde. les calculs répartis sur plusieurs images ne seront
complets que 10 ou 20 fois par seconde, ce qui suffisant pour pas
mal d'effets ! c'est très simple à faire si rien ne bouge :
chaque image calcule une partie des résultats et les accumule aux
résultats précédents pixel par pixel. mais en général, les objets
et/ou la camera bougent, et pour accumuler les résultats sur les
bons pixels, il faut faire un peu de gynmastique... mais en
connaissant les positions des objets à l'image actuelle et l'image
précédente, on peut y arriver, c'est ce que propose le TAA, ie
l'intégration temporelle.
cf les présentations "An
excursion in Temporal Supersampling" GDC 2016 et "Temporal
Reprojection Anti-Aliasing" PlayDead INSIDE
plus récent, une comparaison de plusieurs techniques : "A
Survey of Temporal Antialiasing Techniques" L.Yang 2020
les techniques de base : moyenne exponentielle, reprojection
temporelle, etc. sont introduites dans "Accelerating
Real-Time Shading with Reverse Reprojection Caching" HPG
2007