Définition
L’informatique décisionnelle (Management du système d’information, en anglais : DSS ou encore B.I.) désigne les moyens, les outils et les méthodes qui permettent de collecter, consolider, modéliser et restituer les données, matérielles ou immatérielles, d’une entreprise en vue d’offrir une aide à la décision et de permettre aux responsables de la stratégie d’entreprise d’avoir une vue d’ensemble de l’activité traitée. Ce type d’application utilise en règle générale un datawarehouse (ou entrepôt de données) pour stocker des données transverses provenant de plusieurs sources hétérogènes et fait appel à des traitements lourds de type "batch" pour la collecte de ces informations.
L’informatique décisionnelle s’insère dans l’architecture plus large d’un système d’information.
Les applications classiques d’une organisation permettent de stocker, restituer, modifier les données des différents services opérationnels de l’entreprise (logistique, gestion de la qualité, marketing, finance par l’outil comptable). Ces différents services possèdent chacun une ou plusieurs applications propres, et les données y sont rarement structurées ou codifiées de la même manière que dans les autres services. Chaque service dispose le plus souvent de ses propres tableaux de bord et il est rare que les indicateurs (par exemple : le chiffre d’affaires sur un segment de clientèle donné) soient mesurés partout de la même manière, selon les mêmes règles et sur le même périmètre même s’il est possible d’évaluer l’entreprise. Pour pouvoir obtenir une vision synthétique de chaque service ou de l’ensemble de l’entreprise, il convient donc que ces données soient filtrées, croisées et reclassées dans un entrepôt de données central. Cet entrepôt de données va permettre aux responsables de l’entreprise et aux analystes de prendre connaissance des données à un niveau global et ainsi prendre des décisions plus pertinentes, d’o├╣ le nom d’informatique décisionnelle.
Source : Wikipedia
Processus global
Liste des phases d’un projet décisionnel
Comme je le disais dans la partie précédente, un projet décisionnel est composé de 4 phases clés :
- La phase de collecte
- La phase d’intégration
- La phase d’organisation
- La phase de restitution
Schéma global
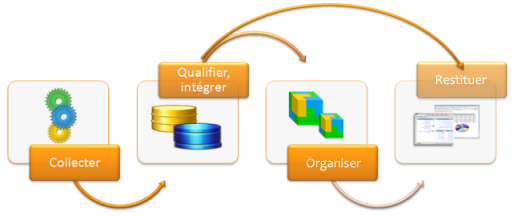
— Processus global de traitement des données d’un système décisionnel —
Source : Bewise
Je vais maintenant détailler ces 4 phases et expliquer les éléments qu’elles contiennent.
Processus détaillé
La phase de collecte
La collecte s’éffectue à partir de données appelées : données sources. Ces données peuvent se présenter sous différents formats. Il peut s’agir de fichiers "plats" (fichiers CSV avec séparateurs, fichiers XML, fichiers ASCII...) mais aussi de systèmes de bases de données (export de base MySQL, PostgreSQL, DB2, ORACLE...). Ces sources de données sont donc en général hétérogènes c’est pourquoi il va falloir passer par une phase dites d’intégration pour pouvoir les manipuler avant de les stocker dans notre système d’aide à la décision.
La phase d’intégration
C’est à ce niveau qu’apparait la première couche logicielle de l’environnement décisionnel à savoir l’ETL. Cette couche offre des fonctions d’extraction de données issues de différents systèmes (internes ou externes), de transformation de ces données (homogénisation, filtrage, calcul) et de leur chargement dans un ODS intermédiaire ou directement dans le DW (entrepôt de données). Elle garantit la délocalisation de la charge de calcul et une meilleure disponibilité des sources.
La deuxième couche logicielle est l’ODS qui fait office de structure intermédiaire destinée à stocker les données issues des systèmes de production opérationnelle. Ce sont en quelque sorte des zones de préparation avant l’intégration des données dans le DW : périodicité journalière, données qualifiées, premier niveau de filtrage et d’agrégat. En général, il existe deux types de schéma : un schéma "ODS brut" qui contient les tables qui recoivent les données brutes des différentes sources et un schéma "ODS final" qui contient des tables avec une structure (champs et contraintes associées) le plus proche possible du schéma du DW (même si les tables de celui-ci peuvent contenir plus de champs que les tables du DW) car ces données vont ensuite être figées dans l’entrepôt. L’ODS ne contient des données que sur une faible période et ces données vont être manipulées, transformées, traitées, modifiées plusieurs fois avant d’être copiées dans le DW. On peut se passer d’utilisation d’un ODS dans un seul cas : si les données du DW sont une simple copie (c’est-à-dire qu’il n’y a pas de traitements à faire et que les données extraites ne vont pas évoluer) des données de production (sources) ce qui n’est malheureusement pratiquement jamais le cas dans de grosses structures.
La phase d’organisation
La trosième phase permet de stocker les données dans un entrepôt appelé : Datawarehouse. Cet entrepôt contient les données orientées métier, non volatiles (datées), historisées et documentées. Cette structure de données est volontairement généralement dénormalisée pour pouvoir optimiser les temps de réponses lorsque l’on fait des analyses de type OLAP qui se réfère à une base de données multidimensionnelle (aussi appelée cube ou hypercube). Elle est constituée de dimensions ou axes d’analyse (l’axe temporel ou géographie sont des exemples courant) et de faits ou indicateurs (tels que le chiffre d’affaires). Un élément important vient du fait que les données stockées dans le DW ne doivent plus changer une fois à l’intérieur. Ce sont des données consolidées et figées qui vont nous permettre de faire toute sorte d’analyses et statistiques.
Une fois ces données stockées dans le Datawarehouse, on va pouvoir créer des magasins de données appelés : Datamarts. Comme le Datawarehouse, c’est un entrepôt de données mais dédié à une fonction de l’entreprise pour des raisons d’accessibilité, de facilité d’utilisation ou de performance. Les données sont généralement équivalentes à celles présentes dans le DW principal mais elles sont représentées de fa├¦on adaptée aux besoins spécifiques de la fonction et/ou du domaine utilisateur (par exemple, on va créer un DM dédié pour le service Marketing ou Commercial). Le DM peut avoir une implémentation physique (cube) ou n’être qu’une vue logique ("multiprovider").
La phase de restitution
La dernière phase concerne la restitution des résultats, on distingue à ce niveau plusieurs types d’outils différents :- Les outils de reporting et de requêtes
- Les outils d’analyse
- La phase de Datamining
Les outils de reporting et de requêtes permettent la mise à disposition de rapports périodiques, pré-formatés et paramétrables par les opérationnels. Ils offrent une couche d’abstraction orientée métier pour faciliter la création de rapports par les utilisateurs eux-mêmes en interrogeant le datawarehouse grâce à des analyses croisées. Ils permettent également la production de tableaux de bord avec des indicateurs de haut niveau pour les managers, synthétisant différents critères de performance.
Les outils d’analyse OLAP permettent de traiter des données et de les afficher sous forme de cubes multidimensionnels et de naviguer dans les différentes dimensions. Cet agencement des données permet d’obtenir immédiatement plusieurs représentations d’un même résultat, en une seule requête sous une approche descendante des niveaux agrégés vers les niveaux détaillés (Drill-down, Roll-up).
Les outils de Datamining offrent une analyse plus poussée des données historisées permettant de découvrir des connaissances cachées dans les données comme la détection de corrélations et de tendances, l’établissement de typologies et de segmentations ou encore des prévisions. Le Datamining est basé sur des algorithmes statistiques et mathématiques, et sur des hypothèses métier.
Fonctionnalités transverses
Il existe 2 grandes familles d’outils :
- Le meta-dictionnaire
- Les outils d’administration
Le meta-dictionnaire (ou méta data), a pour rôle de décrire l’ensemble des données gérées dans le système, depuis les sources de données jusqu’aux restitutions. Il permet aussi de gérer les données communes à toutes les couches.
Les outils d’administration servent à réaliser principalement des sauvegardes ou des restaurations, assurer un suivi de l’utilisation et des performances (journaux ou "logs") ou encore de gérer les droits et les restrictions pour les accès aux applications et aux données selon les utilisateurs.
Schéma détaillé
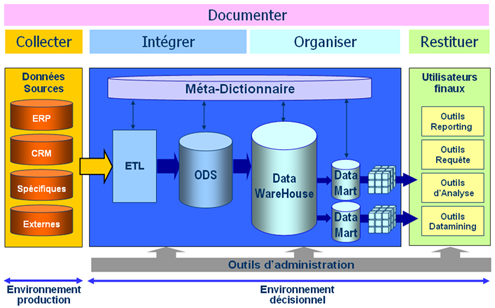
— Processus détaillé de traitement des données d’un système décisionnel —