History:
For years I used EXT4 on MD with a 2 disks RAID1. One of the disks disconnected randomly, so the RAID must be reconstructed (not fully because it was created with a bitmap). I replaced the disk and to be on the safe side, I created a RAID1 on 3 disks.
For years I used EXT4 on MD with a 3 disks RAID1. But one day EXT4 started to display strange error messages. Strangely, 'fsck' fixed problems but some files were not usable, even just after multiple successful 'fsck'. I assume that the mirrored disks were no more synchronized and 'fsck' was getting the uncorrupted data. But I can't check this because I formatted them.
I will no more use a filesystem that does not verify checksum at the file level. So I decided to switch to BTRFS because it seems that all the horror stories are from the past.
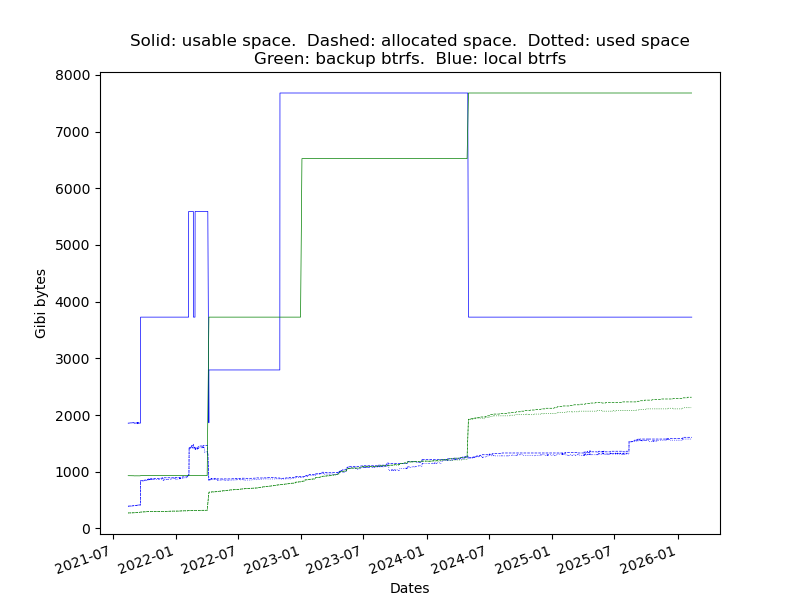
My desktop+backup setup is defined in the picture on the right side
BTRFS is configured with a RAID1, all is duplicated (not triplicated). The OS is far more responsive, there are no more freezing when resetting a big GIT repository. On the good side, BTRFS allows to use 2To of data because the RAID1 is not done at the disk level, so having different disk size is really not a problem.
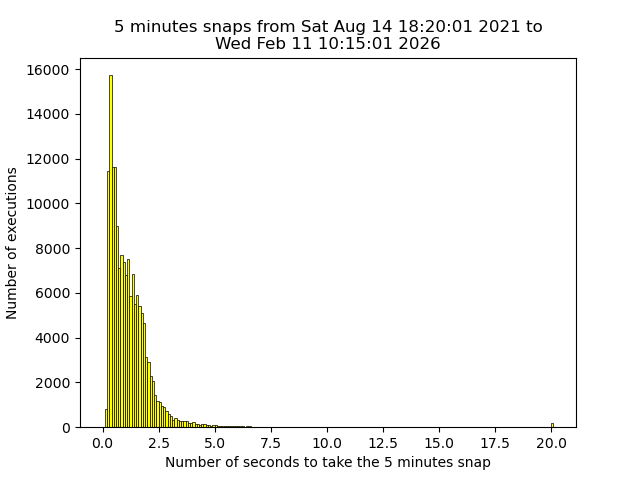
I will see if a snapshot every 5 minutes is really useful, but it costs really nothing (it takes one second). I can restore files instantly and easily (I used 'duplicity' before). I keep last snaps:
| Snap period | Number of snaps kept | |
|---|---|---|
| Local | Backup | |
| 5 minutes | 5 | · |
| 1 hour | 6 | · |
| 1 day | 6 | 31 |
| 1 month | 3 | 24 |
| 1 year | · | 4 |
The deletion of an old snap is an high priority operation that freeze disk writes. So the number of kept snaps must be as low as possible. The deletion must be done when the system is unused.
Beware: the snapshots are done at the subvolume level not at the directory level, moving directories from one subvolume to another is an heavy operation, so take the time to define the subvolumes and their content.
The backups are done by a Raspberry Pi on a mechanical timer plug (5€), the Raspberry Pi (and its disk) get power only 15 minutes per day. It is safe from power surge (or any hacking) most of the time.
The backup disk on the Raspberry Pi is also formatted with BTRFS, so the last snapshot on the desktop disk can be transferred natively to the backup disk with minimal CPU and disk usage. If the desktop BTRFS crashes, the backup disk can be plugged on the desktop and all the files will be immediately usable, and the old snapshots will be accessibles.
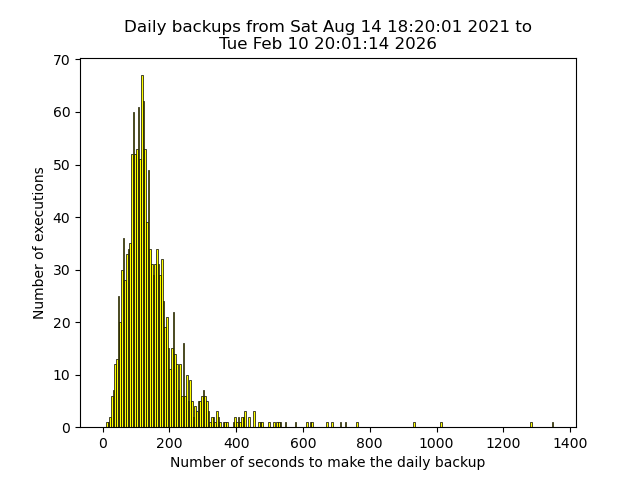
Pending problems:
Random remarks:
The BTRFS filesystem was formatted the 2021-08-11, it works like a charm.
The «btrfs receive» displayed some errors about bad checksums while backuping. I started a scrub on the Raspberry Pi (interrupted by the timer plug) and it quickly discovered multiple checksum errors. I deleted all the intermediate snapshots and rerun the scrubbing, and the scrubbing founds no errors. I manually do a send/receive and once again scrubbing find errors. On the desktop side the scrubbing find no problems.
The pipelined send/receive may have bugs in some kernel versions, so I redo the snapshot copy without using a pipe. The checksum problem is always here.
After deleting the bad subvolume the scrubbing continues to find errors. The filesystem is usable but can't be repaired. The initial filesystem snapshot was not created with the same BTRFS version nor CPU (X86/ARM). So to eliminate this point of failure, I reformated the disk and transferred the original snapshot.
A couple of minutes after the transfer started, once again the filesystem was full of errors, but the system logs were also full of: « Under-voltage detected! » So I restarted all the procedure with a more powerful charger. All worked perfectly fine.
Good point for BTRFS for its early problem detection, the problem was not on its side. The problem with BTRFS is may be that we assume that it is not fully reliable...
It took 1 hour and found no errors. I was working on the computer and the scrubbing did not make the computer slower, it was fully invisible.
The graphic displays the filesystem usage on the desktop and backup, not much change in one month because most of the files are unchanged. The important points are (before the 2021-09-19):
As it is not clear at all, since 2021-09-19 the values are:
The green lines are unchanged because there is no mirroring for the backup.
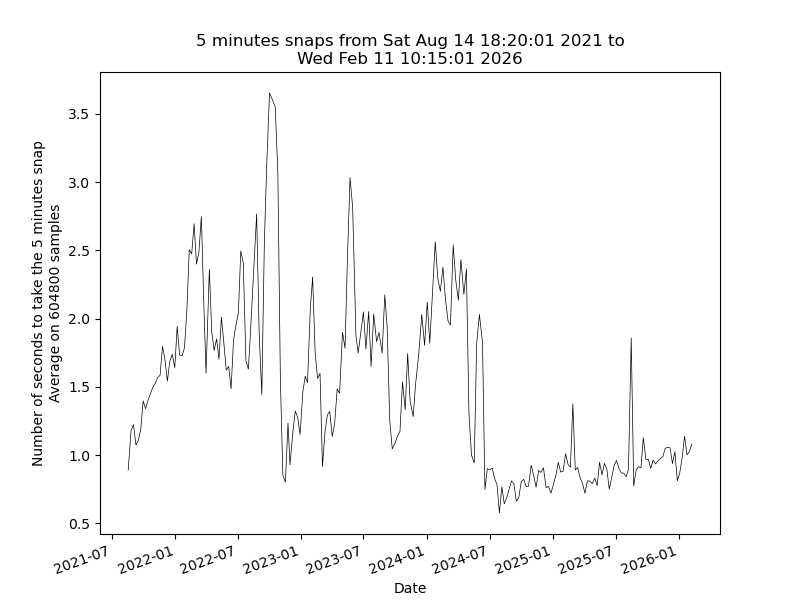
I increased the number of kept snapshots because there is plenty of free disk space. It was a bad idea, but it took me some months to understand.
By mistake I scrubbed one of the device and not the filesystem, so the scrubbing was really fast. It took me some time to understand my error. Once launched on the full system and the 3 discs it took 80 minutes and found no problems.
An EXT4 filesystem I use has reached the maximum number of inodes and by side effect wrecked a GIT repository. EXT4 does not allow to increase the number of inodes without reformating. So it is few hours lost to found the problem and fix it.
By the way, the number of inodes is unlimited with BTRFS.
My snapshot and backup script was not reentrant. So I tried to delete a snapshot while it was being sent to the backup. BTRFS nicely rejected the snapshot deletion, so the backup can be finalized.
Add the 2TB device with :
btrfs device add /dev/sdXXX /XXX
The intent is to use RAID1 with 3 copies, but this functionality requires a 5.5 linux kernel. It is not the default one in Ubuntu 20.04, so I will wait a little.
The new free space is visible on the graphic.
I can't wait, I upgraded my kernel (it was a very bad idea, jump to the next week) with:
apt install \
linux-image-5.13.0-28-generic \
linux-headers-5.13.0-28-generic \
linux-modules-extra-5.13.0-28-generic
Beware, the conversion to RAID1C3 needs to have a lot of free space. Really much more than what it is theoretically needed. I really don't understand why, I assume it is to allow to cancel nicely the conversion.
I converted the filesystem to RAID1 with 3 copies :
btrfs balance start -dconvert=raid1c3 -mconvert=raid1c3 /XXX
The balancing took 7 hours and it was fully transparent because it uses not much bandwidth nor CPU. It's a lot of time to copy 500Go of data, I assume it is because the operation is done very safely in order to be resilient to power cut. At the balancing end, 200GB were freed. The balancing wrote 2.2TB dispatched on the 4 disks.
On the graphic the used space increase because there are now 3 copies of the data.
As the four disks are on a powered usb HUB (TP-LINK UH700) and I am not very confident on the power management I launch a scrub in order to check all the data.
btrfs scrub start /XXX
The scrubbing took 80 minutes (same time than for 3 disks), read 300MB/s from disks, was fully transparent (except for IO intensive applications) and found no errors.

A JBOD enclosure allows to have standard 3.5 inch SATA hard disk in a box connected with a single cable to the computer. Each of the disk is accessible individually, they is not a RAID.
Less cables.
Cheap disks.
Single a point of failure, if the box die, none of your discs is accessible until you buy a new one.
Noisy because the enclosure needs a fan.
Needs a power alimentation.
Not possible to add a new disk if the box is full
So I stay with my spaghetti plate
With my current setup with RAID1C3 on 1+1+2+2 TB, I can take any two of the disks and recreate two usable separate BTRFS filesystem. Beware these 2 sets of disks must never be put together again on the same computer. Just a VERY DANGEROUS fun idea.
I found 18 times these 6 lines with «dmesg», the 9, 11 and 12 february. The bold text is the same in all the messages :
[348613.432090] BTRFS error (device sdb): bad tree block start, want 951475748864 have 7611175298055105740 [348613.440063] BTRFS error (device sdb): bad tree block start, want 951475748864 have 7611175298055105740 [348613.537293] BTRFS info (device sdb): read error corrected: ino 0 off 951475748864 (dev /dev/sdc sector 767774688) [348613.537586] BTRFS info (device sdb): read error corrected: ino 0 off 951475752960 (dev /dev/sdc sector 767774696) [348613.537820] BTRFS info (device sdb): read error corrected: ino 0 off 951475757056 (dev /dev/sdc sector 767774704) [348613.538023] BTRFS info (device sdb): read error corrected: ino 0 off 951475761152 (dev /dev/sdc sector 767774712)
btrfs device stats /XXX does not display errors.
I run btrfs scrub start /XXX found and corrected 949 bad chunks on /dev/sdc.
The scrubbing froze my computer multiple times by sending dozens of GB to the logs. A second scrubbing did not manage to terminate.
Scrub device /dev/sdb (id 1) done Scrub started: Wed Feb 16 14:08:50 2022 Status: finished Duration: 0:53:57 Total to scrub: 245.00GiB Rate: 75.40MiB/s Error summary: no errors found Scrub device /dev/sdd (id 2) done Scrub started: Wed Feb 16 14:08:50 2022 Status: finished Duration: 0:58:14 Total to scrub: 244.03GiB Rate: 70.23MiB/s Error summary: no errors found Scrub device /dev/sdc (id 3) done Scrub started: Wed Feb 16 14:08:50 2022 Status: finished Duration: 1:29:21 Total to scrub: 489.03GiB Rate: 91.29MiB/s Error summary: csum=1 Corrected: 1 Uncorrectable: 0 Unverified: 0 Scrub device /dev/sde (id 4) done Scrub started: Wed Feb 16 14:08:50 2022 Status: finished Duration: 1:30:36 Total to scrub: 489.03GiB Rate: 90.02MiB/s Error summary: no errors found
At this point I thought that such a failure was certainly my fault. As the scrubbing is directed by 'btrfs-prog' and it does not match the kernel version, this can be the origin of the problem. So I installed «btrfs-progs» from sources, I needed the really last developer version because to compile it, it was necessary to have a patch only a week old.
The scrubbing ended nicely correcting one problem.
So BTRFS has done its job and the data was safe on disk even after multiple hard reboots. Even the filesystem snapshots and backup were working nicely.
It is required to have the same version of BTRFS in the kernel and for btrfs-progs. It is the down side of having a filesystem evolving quickly.
To be sure I started a third scrubbing while using intensively the computer... It found no error.
The computer was using disks continuously for several days, one of the disk has some problems. So the origin of the previous problems was not a BTRFS one but a problem with one of the disks.
I scrubbed the bad disk and found 1859 bad checksums. Sadly the disk does not have SMART capability. It was brought 3 years ago, so not so old.
A second scrub make so many log errors that the computer was frozen. I restarted the scrubbing multiple times but can't finish it.
So I give up and run:
btrfs device remove /dev/XXX /XXX
The removing took many hours with the disks nearly not used (nor the CPU). The free space size is slowly decreasing while the device is being removed.
The device removing writes data on the disk to remove. It is a strange behavior considering that the removal is certainly done for a failing disk. Some untested tips on the web indicated to remove physically the disk to speedup the process: Do not do this.
While the disk was removed, applications froze sometime for some seconds. I assume it is because a needed bloc group was being displaced.
The freezing cause seems to be the deletion of old snapshots. If the number of snapshots is low it should be less a problem.
Once the disk removed I launched a search for bad blocks. It takes 40 hours to test the 4 write patterns.
badblocks -sw /dev/XXX
It found bad blocks (1024 bytes per block):
So using 'fdisk' (beware, sectors of 512 bytes), I created partitions without the badblocks. I don't add these partitions one by one in BTRFS to be sure that they are not seen as multiple physical disks. I merged the partitions with 'mdadm':
echo "n p 211070798 n p 221378432 1619531910 n p 1619532032 2312960038 n p 2431502208 p w" | fdisk -W always /dev/XXX mdadm --create --verbose /dev/md0 --level=0 --raid-devices=4 /dev/XXX1 /dev/XXX2 /dev/XXX3 /dev/XXX4
To be sure I made no configuration errors and that the bit rot was not spreading, I launched 'badblocks' on '/dev/md0' with random write in order to detect sector not stored in the good place.
badblocks -svwt random /dev/md0
It found a huge number of bad blocks, so this disk is no more usable, I added a fresh disk to BTRFS:
btrfs device add /dev/XXX /XXX btrfs balance start /XXX
The balancing was not required because I have a lot of free space. I do it because I hope the mirroring will speedup disk read access because all the data is on 4 disks instead of 3. The balancing took 13 hours.
It's nearly impossible to work while balancing is running. It was not the case 2 weeks ago. I suppose it is because the number of snapshots was not the same or because the btrfs-prog version changed.
VSCode and thunderbird started to freeze more and more often because they use SQLite and it does not work nicely with BTRFS. They are 3 ways to fix this.
| How | Advantage | drawback |
|---|---|---|
| Defragment: btrfs filesystem defragment |
Works online. Easy to do. |
Must be done periodically. May take lot of disk space. |
| Disable BTRFS COW: chattr +C |
Works on any offline database. |
chattr works on empty files. No more block checksum: so the bitrot is possible. |
| Configure SQLite SQLite journal mode: WAL | Fast and secure | None |
So I converted some databases. The application must be stopped before running the script:
find .config/Code \
.thunderbird \
.mozilla \
.local/share \
snap/firefox \
snap/chromium \
'(' -name '*.vscdb' \
-o -name '*.sqlite' \
-o -name '*.db' \
-o -name '*.data' \
-o -name Favicons \
-o -name History \
-o -name Cookies \
')' -exec sqlite3 {} "PRAGMA journal_mode=WAL" ';'
VSCode continues to freeze (but not Thunderbird), so there is another problem.
I reduced the number of snapshots to only 20 because it seems that the deletion of old snapshot freezes the disk writes on Linux version 5.13.
This 2019 thread shows that the problem is known, maybe it is now fixed, I did not find any recent link on the subject.
A possible way to turn around this current BTRFS limitation is to:
To have the final word on snapshoting, see the snapshoting chapter.
When a disk is missing, balancing and removing operations takes far more time because many thousands of error messages are logged by the kernel. Using VSCode in a such situation is very hard because it freezes frequently.
If a balancing is done with a missing disk, BTRFS works as if the disk was here and so the data is no more mirrored! I will not make a bug report because there is a mismatch between kernel and user space BTRFS on my computer.
So remove the disk from BTRFS before unplugging it.
Without stopping working nor rebooting the desktop I swapped disks beetween the desktop and the backup host. It took some days, but worked.
One disk started to have problems :
mai 18 20:15:43 pundit kernel: sd 5:0:0:0: [sdd] tag#5 CDB: Write(10) 2a 00 1a cd c4 d0 00 00 08 00 mai 18 20:15:43 pundit kernel: sd 5:0:0:0: [sdd] tag#4 uas_eh_abort_handler 0 uas-tag 1 inflight: CMD OUT mai 18 20:15:43 pundit kernel: sd 5:0:0:0: [sdd] tag#4 CDB: Write(10) 2a 00 16 3a 43 80 00 04 00 00 mai 18 20:15:43 pundit kernel: scsi host5: uas_eh_device_reset_handler start mai 18 20:15:43 pundit kernel: sd 5:0:0:0: [sdd] tag#7 uas_zap_pending 0 uas-tag 4 inflight: CMD mai 18 20:15:43 pundit kernel: sd 5:0:0:0: [sdd] tag#7 CDB: Read(10) 28 00 35 79 fb 58 00 00 08 00 mai 18 20:15:43 pundit kernel: usb 2-4.1.3: reset SuperSpeed USB device number 6 using xhci_hcd mai 18 20:15:43 pundit kernel: scsi host5: uas_eh_device_reset_handler success ... mai 18 20:16:44 pundit kernel: sd 5:0:0:0: [sdd] tag#13 timing out command, waited 180s
The filesystem was working, but was unusable because on each error BTRFS was freezed for 3 minutes.
A full power off host and USB hub fixed the errors and BTRFS has not lost any data. It fixed one error with a scrubbing.
I changed the disk because the problems restarted. I forgot the «-r» option so the replacing was slow (many read errors).
btrfs replace start -r /dev/WORKING /dev/BROKEN /dev/NEW /XXX
badblocks worked perfectly on the removed disk. No disk error of any kind (physical or communication). So I assume that BTRFS uses the disk in such way that it fails.
It is really annoying that snap deletion froze applications. So instead of snaping every five minutes the new algorithm is to check every five minutes :
So the snap is done when the user takes a break.
To have the final word on snapshoting, see the snapshoting chapter.
To cleanup my desktop I replaced my USB disks by a disk dock. A Sabrent DS-SC4B, it is a very good product, but very noisy even after a fan change. I put it in a bookself behind a row of books to attenuate the sound, I make a hole in the back of my bookshelf to let the air flow. It's a shame because the enclosure is nice. The enclosure manage cleanly the OS suspend and smartctl.
I am very happy because there are no more freeze even when the OS is stressed multiple «git gc» on huge repositories. The SATA disks are 2 times faster, but this does not explain the fact that the OS is really snappier.
The 5 minutes snaps are now done only if:
To have the final word on snapshoting, see the snapshoting chapter.
I created a small DANGEROUS script «btrfs-bench-balance» to evaluate the disk usage of balancing when there are snapshots.
There are the results if «/usr» is taken as starting point (19GB and 640000 files) and 1000 files are copied and deleted before each snapshot (btrfs-progs 5.16.2) The table contains the amount of data written on disk to do the operation, the size is relative to the real data size.
To have the final word on snapshoting, see the snapshoting chapter.
| Number of snapshots | add a second disk | add a third disk | add a fourth disk | remove fourth disk | remove third disk | remove second disk |
|---|---|---|---|---|---|---|
| 1 | 2.0 | 2.1 | 2.0 | 3.1 | 3.5 | 1.7 |
| 2 | 2.0 | 2.2 | 2.0 | 3.2 | 3.5 | 1.6 |
| 4 | 2.1 | 2.1 | 2.1 | 3.2 | 3.5 | 1.7 |
| 8 | 2.1 | 2.1 | 2.1 | 3.2 | 3.6 | 1.6 |
| 16 | 2.1 | 2.2 | 2.1 | 3.2 | 3.5 | 1.7 |
| 32 | 2.3 | 2.3 | 2.3 | 3.4 | 3.9 | 1.8 |
| 64 | 2.5 | 2.6 | 2.5 | 3.8 | 4.3 | 2.0 |
The good news: the number of snapshots does not increase the amount of data to do the operation. Beware: it may not be the case if the same files are modified between each snapshots.
When adding a second disk, the numbers are the expected results because data is written at two places, so this usage case is working nicely. But when adding a third disk, I was expecting that some data will not be moved, and clearly it is not the case.
But how can it be possible that removing a disk writes so much data?
The best algorithm is :
Deleting snapshot is an operation that may freeze applications, so it must done only if the computer is not interactively used. After some hours of continuous work, dozens of snapshots will be deleted.
Detecting when there is no user interaction for 5 minutes is not an easy task because some applications raise fake user events. So xssstate -i does not give the good idle time.
Moreover, cleaning old snaps every 5 minutes is a waste of time and may slow down the computer if the user restart its work at the bad time.
So now, I clean old snaps if the user has locked the session since the last snapshot (5 minutes in my case). To check this I use the command xscreensaver-command -time (or gnome-screensaver-command -q or xfce4-screensaver-command -q...)
Its perfect because if the user lock its session, it will not be unlocked soon.
After one year I decided I can no more stand the noise of the SATA enclosure. So I switched the disks content (it tooks some days).
On my computer:
On the backup system:
| Snap period | Number of snaps kept | |
|---|---|---|
| Local | Backup | |
| 5 minutes | 12 | · |
| 1 hour | 8 | · |
| 1 day | 7 | 365 |
| 1 month | 1 | 24 |
| 1 year | · | 4 |
To replace a big disk by a smaller one, the devices names must not be used, only the devices ID:
btrfs device usage -b /XXXdisplays devices ID and sizes in bytes.
btrfs filesystem resize 42:1000204886016 /XXXresize the device 42, it may take a long time.
btrfs replace start 42 /dev/sdXXX /XXXreplace device 42 by disk /dev/sdXXX
btrfs replace status /XXXlook at the percentage of replacement done.