
L'idée du tp est de réaliser les tests de visibilité des boites englobantes des régions de la scène comme dans le tp précédent, mais avec un compute shader et d'afficher les régions visibles avec un seul draw, cf MultiDrawIndirect. les parties suivantes décomposent une solution.
que faut-il faire pour réaliser le test de visibilité d'une région avec un compute shader ?
glMultiDrawIndirect()
/ glMultiDrawIndirectCountARB() pour tout dessiner d'un
coup. relisez la doc
exercice 4 : un peu de nettoyage...
modifiez le shader précédent pour écrire, dans un buffer résultat,
les paramètres de draw des régions visibles (et uniquement les
régions visibles). le shader ressemblera à l'exercice 6 du tp de
préparation.
comparez les performances à la version précédente. c'est mieux ?
mais combien de régions faut-il dessiner maintenant ?
l'application doit fournir le nombre de draws lors de l'appel
MultiDrawIndirect.
mais la valeur est dans un buffer... il suffit de relire cette
valeur avec glGetBufferSubData() avant de dessiner.
cette solution fonctionne correctement mais elle introduit une
synchronisation entre le gpu et l'application qui doit attendre la
fin de l'exécution du compute shader, relire la valeur du compteur
et enfin dessiner les n régions visibles. il existe une solution
plus rapide, sans synchronisation : utilisez
MultiDrawIndirectCount(), relisez la doc,
si nécessaire. cette version de MultiDrawIndirect utilise un
buffer pour lire le nombre de draws à réaliser !
comparez les performances à la version précédente. c'est mieux ?
exercice 5 : un gros nettoyage !
modifiez votre shader pour limiter les opérations atomiques en
mémoire graphique. cf exercice 7 / partie 1.
comparez les performances aux versions précédentes. c'est mieux ?
ou cette optimisation n'est pas nécessaire dans ce cas ?
exercice 6 : et avec les matières et les textures ?
c'est le bon moment pour faire cette partie, si ce n'est pas déjà
fait.
Dans un premier temps, concentrez vous sur la méthode elle meme
et faites les tests dans l'application. Lorsque les différents
éléments du test fonctionnent dans l'application, il faudra écrire
un compute shader...
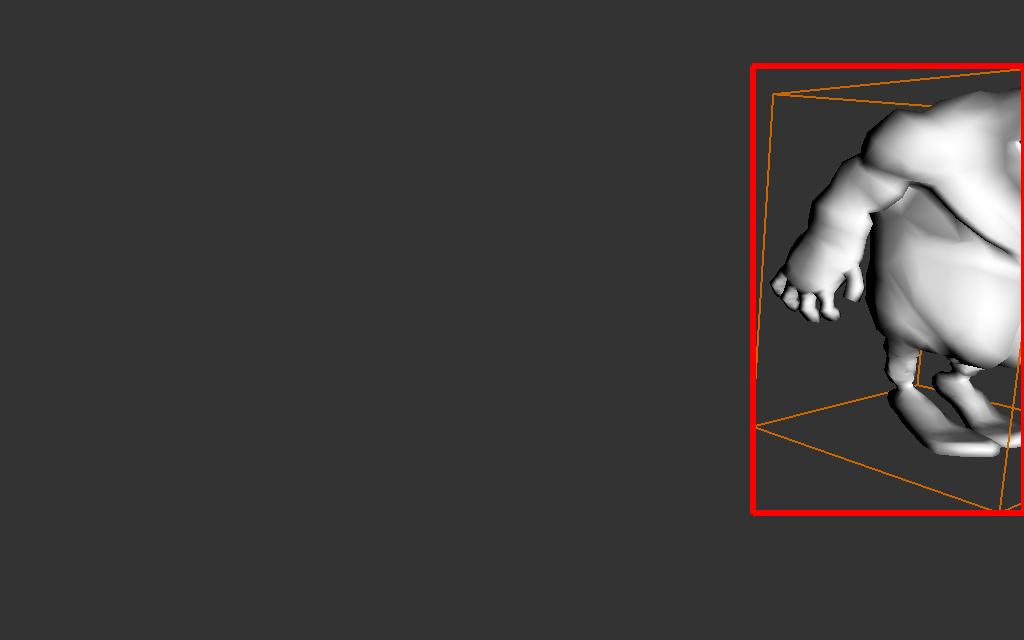

attention ! lorsque l'englobant de l'objet passe derriere
la camera, la projection va produire des résultats surprenants, il
faudrait découper l'englobant de l'objet et ne conserver que la
partie devant la camera.
indication : une autre solution, plus simple, considère
qu'un objet dont l'englobant est partiellement derrière la camera
sera visible sur toute l'image... ie le rectangle englobant de sa
projection dans l'image sera l'image complète.
bien sur, si l'englobant est entièrement derrière la camera,
l'objet n'est pas dans le frustum : il n'est pas visible et il n'y
a pas besoin de faire ce calcul de rectangle englobant. ie on ne
dessine un objet que si une partie de son englobant est dans le
frustum.
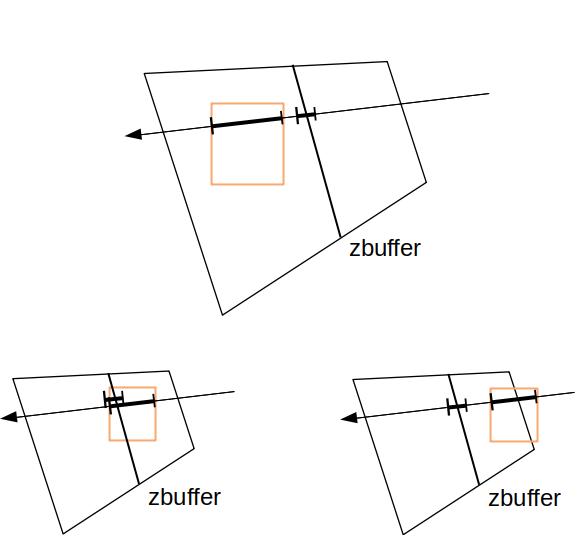
exercice 8 : déterminez la visibilité de l'objet en
comparant la profondeur stockée dans le zbuffer et la profondeur
de la boite englobante de l'objet pour chaque pixel. selon le cas,
l'objet est entièrement derrière le zubffer, complètement devant,
etc.
exercice 9 : testez l'inclusion des régions dans le
frustum, dessinez-les, et récupérez le zbuffer. Testez les
englobants image de chaque région par rapport au zbuffer. combien
sont visibles ?
rappel : pour relire le zbuffer de la fenetre depuis
l'application, utilisez glReadPixels(), (ou regardez comment
fonctionne screenshot()...)
std::vector<float>
zbuffer(width*height);
glReadBuffer(GL_BACK);
glReadPixels(0, 0, width, height,
GL_DEPTH_COMPONENT, GL_FLOAT, zbuffer.data());
remarque : si le zbuffer est dans une texture, relisez la texture dans l'application avec glGetTexImage().
exercice 10 : c'est un peu lent non ?
tester tous les pixels de l'englobant image de chaque région est
long. comment faire plus rapide, et en temps constant ?
indications : l'idée est d'utiliser un zbuffer
hiérarchique et de faire le test dans la "bonne" résolution du
zbuffer en fonction des dimensions de l'englobant image. par
exemple, on peut choisir la resolution du zbuffer pour ne tester
que 4 pixels... ou 16.
exemple : pour une région dont l'englobant image est
toute l'image, on peut choisir le zbuffer de resolution 1x1, 2x2
ou 4x4 et ne faire que 1, 4, ou 16 tests.
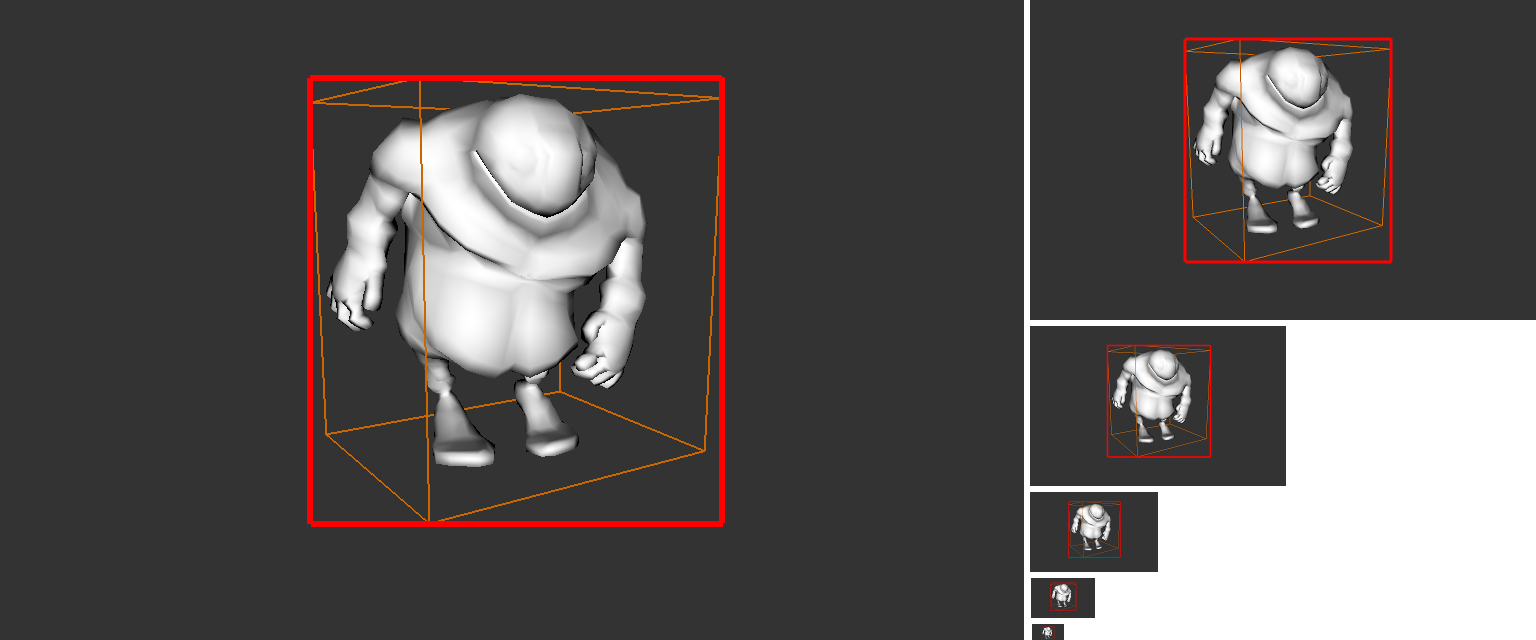
pour des englobants plus petits, qui n'occuppent pas toute l'image, il est aussi possible de choisir une resolution du zbuffer qui permette de ne tester que quelques pixels.
choisir cette resolution est un compromis, existe-t-il des cas ou
il serait souhaitable de faire un test plus précis ?
quel est le probleme avec les englobants qui occuppent toute
l'image ?
quel est le problème avec les englobants qui sont partiellement
derrière la camera, le plan near ?
pour chaque pixel d'un mipmap du zbuffer, on peut construire
l'intervalle de profondeur des pixels du zbuffer pleine
resolution. est-il nécessaire de conserver les 2 bornes de
l'intervalle ?
construisez le zbuffer hiérarchique. et vérifiez que le test
d'occultation hiérarchique fonctionne correctement.
exercice 11 : maintenant que le test d'occultation est en
place, il ne reste plus qu'à l'utiliser pour dessiner les régions
de la scène.
Mais pour que ce soit interressant, il faut un zbuffer pour
tester la visibilite des régions avant de les dessiner... L'idée
est de dessiner les régions considérées visibles lors de l'image
précédente pour construire / initialiser le zbuffer, puis de
tester les régions pour lesquelles on a pas encore établi la
visibilité. et bien sur de conserver cette information pour
initialiser l'image suivante...
exercice 12 : c'est quand meme lent de relire le zbuffer
dans l'application... comment faire le test avec un compute shader
?
l'idée est toujours la meme, le compute shader fera le test de
visibilite et remplira un tableau de parametres pour
MultiDrawIndirectCount().
indications : commencez par construire le zbuffer
hiérarchique avec un compute shader...
utilisez imageLoad() / imageStore() pour lire et écrire les
zbuffers. relisez la
doc sur les storage images / textures.
les opérations atomiques min, max, addition, etc existent aussi
sur les images (en plus des buffers) elles sont documentées dans
la section glsl de la doc opengl, ou sur le wiki
opengl.org
comment paralléliser ce calcul ? combien de dispatch()
faudra-t-il faire ? 1 par resolution ?
peut-on grouper le calcul de plusieurs niveaux du zbuffer
hierarchique dans un seul compute shader ? comment ? pourquoi
vouloir faire ca ?
commencez par la version directe, 1 dispatch() + synchronisation
par resolution du zbuffer.
pour les curieux : oui, on peut gagner un peu de temps sur
le test d'occultation en utilisant textureGather() au lieu de
texture(), qui renvoie 4 valeurs de 4 pixels différents...
pour les tres curieux : construire un mipmap de maniere
très efficace est décrit sur gpuopen. les
commentaires sur la technique sont dispo
(video)
vous venez de construire votre premier "gpu-driven rendering
pipeline" !
il ne manque plus que les mesh shaders et vous savez faire aussi
bien qu'eux
! (ou peut etre pas tout à fait ?)