rendu différé / direct ?
deferred rendering / forward rendering ?
Partie 1. Pourquoi ces 2 types de rendu existent-t-ils ?
La vraie question est légèrement différente : quelles sont les
limites du rendu classique ?
Une carte graphique dessine scrupuleusement tous les triangles dans
l'ordre : chaque fragment de chaque triangle provoque l'exécution du
fragment shader responsable de calculer sa couleur.
Ce comportement semble plutot raisonnable, jusqu'au moment ou l'on
compare le nombre de fragments généré au nombre de pixels de
l'image. Pour une scène un peu complexe, plusieurs triangles se
dessinent sur le même pixel, mais un seul sera visible dans l'image
à la fin du calcul. Lorsque les calculs réalisés par le fragment
shader deviennent complexes, la perte de temps peut etre importante.
Le rendu différé est une méthode permettant de n'exécuter les
fragment shaders qu'une fois par pixel, uniquement sur le fragment
visible. mais ce n'est pas tout à fait aussi simple...
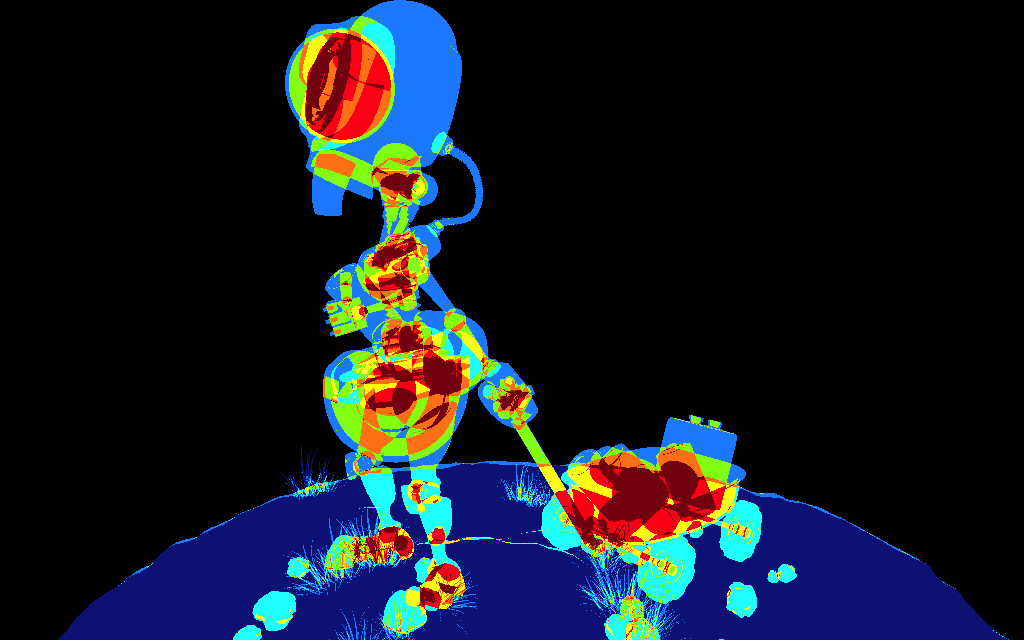
Les images suivantes illustrent le problème en permettant de
visualiser le nombre de triangles par pixel. Vous pouvez reproduire
les résultats avec d'autres objet 3d en utilisant tuto_storage_texture
exemples :
Selon les points de vue, pas mal de pixels sont couverts par au
moins 4 triangles, voir nettement plus, et bien sur tous les
fragments générés provoquent l'exécution des shaders. Une
optimisation simple permet de réduire légèrement le nombre de
fragments générés : dans la configuration par défaut, le test de
profondeur d'un fragment à lieu après l'exécution du fragment shader
(pourquoi ? un fragment shader peut modifier la profondeur du
fragment...). Mais il est possible de faire le test avant
l'exécution du shader. Il suffit d'ajouter la décoration :
layout(early_fragment_tests) in;
dans l'entête du fragment shader pour configurer le pipeline
graphique. Ce test utilise une version hiérarchique du zbuffer (qui
existe sur toutes les cartes graphiques), qui permet de déterminer
qu'un bloc de fragments ne peut pas être visible (la profondeur des
fragments est supérieure à celle de la géométrie déjà dessinée).
Bien sur, tous les fragments invisibles ne sont pas éliminés, il
faudrait connaitre à l'avance la profondeur du fragment visible, que
l'on ne connait qu'une fois tous les triangles dessinés.
L'efficacité de ce test dépend donc fortement de l'ordre dans lequel
sont dessinés les triangles (la meilleure solution serait de les
dessiner en s'éloignant de la camera, mais cela nécessite de les
trier, même approximativement avant de les dessiner...)
Cet exemple est un cas de base qui n'utilise qu'une seule matiere et
un seul fragment shader, mais que se passe-t-il pour une scene plus
complexe avec plusieurs matières / textures ? Par exemple, cette
scène type Minecraft est dessinée de manière assez classique :
La carte est découpée en régions de 16 par 16 cubes, la visibilite
de chaque région est testée avant affichage, puis chaque région
visible (partiellement ou entièrement inclue dans le frustum de la
camera) est dessinée matière par matiere, en changeant de textures à
chaque fois. Afficher toute la carte (qui est plutot petite, voire
minuscule à l'échelle de Minecraft) nécessite 1275 draw(), ce qui
est assez lent et cette solution ne permettra pas d'afficher une
carte beaucoup plus grande. Bien sur, lorsque la camera est plus
proche du terrain, le nombre de régions visibles est plus faible,
mais il faut encore quelques dizaines de draw(). Mais lorsque la
camera est proche du terrain, de plus en plus de triangles se
projettent par pixel...
Si l'on souhaite dessiner cette carte plus rapidement, il faut
changer de méthode pour réduire fortement le nombre draw() et mieux
utiliser les capacités de la carte graphique. En analysant la
méthode d'affichage, on constate assez facilement que c'est la
gestion des matières qui oblige à utiliser plusieurs draw() pour
afficher une région. Si l'on souhaite afficher plus de géometrie
(soit plus détaillée, soit plus de régions...), il faut pouvoir
dessiner la géométrie (toutes les régions visibles !),
indépendamment des matières des triangles avec le moins d'appels à
draw, 1 seul dans le meilleur cas... et n'exécuter les fragment
shaders que sur les fragments réellement visibles dans l'image...
c'est à dire un seul fragment shader exécuté par pixel de l'image.
remarque : euh ? pourquoi est-il aussi important de
réduire le nombre de draws ?
Dans cet exemple, chaque région est dessinée matière par
matière, ou texture par texture. on configure le pipeline pour
utiliser une texture puis on dessine tous les cubes de la région qui
utilisent cette texture et on recommence pour chaque texture de la
région et encore pour chaque région.. pour chaque draw, on a
entièrement reconfiguré le pipeline : changement de texture,
eventuellement changement de shaders, changement de vao / buffers,
et toutes ces opérations prennent du temps, à l'application bien
sur, mais aussi au driver openGL qui prépare les commandes à envoyer
à la carte graphique.
En pratique, il y a un abus de langage : ce qu'il faut réduire,
c'est le nombre de configurations différentes du pipeline utilisées
pour dessiner la scène, et surtout vérifier que la manière de
dessiner les objets de la scène, l'ordre dans lequel on les dessine,
ne fait pas plus de changements de configuration du pipeline que
nécessaire.
si on dessine avec un seul draw tous les triangles / objets qui
partagent la même configuration, le nombre de draw résume bien la
situation...
Dernière subtilité, même une fois que l'on a réduit le nombre de
configurations nécessaires pour dessiner la scène, il faut quand
même s'assurer que l'ordre dans lequel on dessine les objets
provoque le moins de changements de configuration possible... dans
l'exemple, il y a une configuration par texture utilisée pour
décorer les cubes. il y a 5 types de cubes / textures, donc on
devrait pouvoir dessiner la carte avec 5 draws, pas 1275... c'est
très facile à faire si on dessine tout sans vérifier la
visibilité... si la carte est vraiment grande, avec des millions de
cubes, la carte graphique ne permettra pas de les dessiner
rapidement, d'ou la nécessité de découper la carte en région et de
ne dessiner que les régions visibles. Mais la solution choisie fait
beaucoup trop de draws / changements de configuration du pipeline
pour etre efficace sur les grandes cartes...
Les sections suivantes présentent 2 solutions classiques à ce
problème.
Solution 1 : z pre-pass et rendu direct / forward rendering
Une solution pour n'exécuter qu'un seul fragment shader par pixel
consiste bizarrement à dessiner 2 fois les objets la scène et à
activer le test de profondeur avant l'exécution des fragments
shaders (cf partie 1) :
- étape 0 : initialiser le zbuffer,
- étape 1 : créer rapidement le zbuffer de l'image, sans
fragment shader, avec un ztest normal, cf glDepthFunc(GL_LEQUAL)
indication : il suffit de n'attacher qu'un vertex shader au
shader program. le fragment shader ne sert à rien, on ne veut
stocker que la profondeur de chaque fragment, pas sa
couleur...
- étape 2 : redessiner les objets avec les shaders "normaux" et
évaluer la couleur de la matière en laissant faire le Z
hiérarchique, avec un ztest exact, cf glDepthFunc(GL_EQUAL) +
layout(early_fragment_tests) in;
attention
: le zbuffer n'est pas re-initialisé avant l'étape
2...
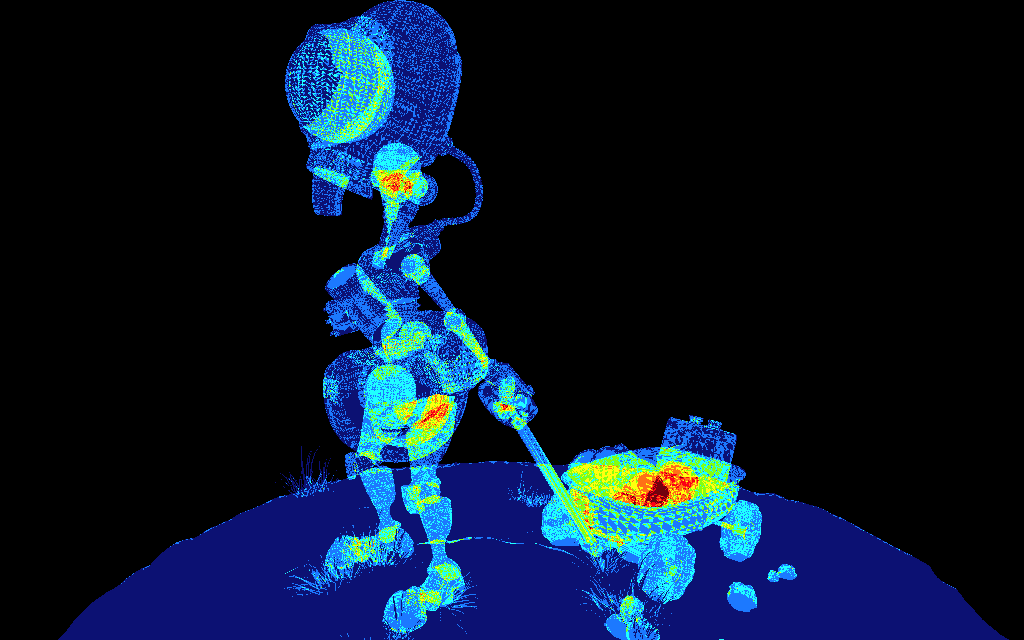
On peut obtenir le résultat suivant en comptant le nombre de
fragments par pixel en dessinant à l'étape 2 :
C'est plutot un bon résultat, il n'y a effectivement plus qu'un seul
fragment par pixel qui passe le ztest, et il sera bien le seul à
faire des calculs, et uniquement sur la surface visible.
Qu'est ce qui à changé ? tous les triangles sont dessinés par les 2
étapes. Mais l'étape 1 a construit le zbuffer et lors de l'étape 2,
lorsque l'on redessine les triangles, le ztest exact n'exécute les
fragment shaders que sur les fragments visibles.. c'est à dire 1
fois par pixel. ce qui évite de perdre du temps à calculer les
fragments cachés, mais il faut dessiner 2 fois la scène, ce qui peut
être génant, cf mesure
de temps cpu / gpu.
Bien sur, cette solution ne sera interressante que si l'on peut
dessiner toute la géometrie avec très peu de draw() à l'étape 1.
Mais comme il n'est pas nécessaire de "traiter" les matières (pas la
peine de re-parametrer les shaders à chaque changement de matière),
il est possible de ré-organiser les positions des sommets des objets
pour tous les dessiner avec 1 seul draw() ou presque...
pour les curieux : en
utilisant glMultiDrawIndirect( ), cf tuto_mdi
on peut grouper l'affichage de plusieurs objets dans un seul draw()
!!
Conclusion : en stockant le z dans une première passe, on peut
exécuter les shaders uniquement sur les surfaces visibles.
Solution 2 : rendu différé / deferred rendering / G-buffer
On peut pousser l'idée plus loin : et si on stockait toutes les
informations nécessaires aux calculs de lumière / matière dans une
ou plusieurs textures lors de la première étape ? Il suffirait alors
d'une 2ieme étape simplifiée qui ne dessine qu'un quad (ou un gros
triangle) qui couvre toute l'image. Dessiner cet imposteur permet
d'exécuter un seul fragment shader par pixel pour faire les calculs
sur les matières. Cette modification évite de dessiner les objets
une deuxième fois.
remarque : en général,
c'est un compute shader qui réalise les calculs par pixel dans la
2ieme étape.
Par exemple, pour éclairer un fragment avec une source de lumière
ponctuelle, on a besoin de connaitre :
- la position du point, sa normale,
- la position de la source, son émission,
- la brdf, la couleur diffuse et l'exposant pour les reflets
Il suffit de configurer un framebuffer pour stocker pour chaque
pixel visible, la position, la normale, la couleur diffuse
(eventuellement lue depuis une texture), et l'exposant du reflet :
vec3 p;
vec3 n;
vec3 diffuse;
float m;float z; (implicite, stocké dans
zbuffer)
ce qui nécessite de configurer un framebuffer avec 3 textures
floats pour stocker rgb32f p, rgb32f n, rgba32f diffuse+m,
soit 10 floats / 40 octets par pixel.
il est possible de recalculer la position p connaissant les
coordonnées du fragment dans le repère image, cf gl_FragCoord.xy
et le zbuffer, ce qui évite de la stocker explicitement.
Ces textures qui stockent toutes les informations nécessaires
pour calculer la couleur d'un fragment s'appelle un G-buffer, (G
comme geometry...)
pour les curieux : bien sur, il est possible de compresser
ces données pour limiter leur taille...
les couleurs sont souvent stockées sur 3 canaux
10bits, cf GL_RGB10, ou 4 canaux 8bits, cf GL_RGBA8.
le cas des normales est plus interressant :
voici un catalogue de différentes solutions évaluées par un
developpeur Unity : blog
en résumé :
- étape 0, initialiser le gbuffer : les textures qui vont
stocker profondeur, position, normale, etc. de la géometrie
visible,
- étape 1, construire le gbuffer : dessiner la géometrie (avec
le moins de draw() possible) et stocker les paramètres,
- étape 2, évaluer le gbuffer : dessiner un quad ou triangle
plein écran pour exécuter un fragment shader par pixel (ou
utiliser un compute shader) et évaler la couleur du pixel en
utilisant les informations stockées dans les textures du
gbuffer.
Comme pour la solution précédente, tout ça ne sera interressant
que si l'on peut dessiner la géométrie lors de l'étape 1 avec un
seul draw() ou presque.
Un inconvénient de cette méthode est le volume de données qui est
écrit par la 1ere étape (les données d'un pixel seront écrites 1
fois par triangle se dessinant sur le pixel) et relue par la 2ieme
étape (1 seule fois par contre).
L'autre inconvénient de la méthode est plus subtil : comment
faire pour exécuter des calculs / shaders différents en fonction
du type de la matière de chaque pixel ? Dans le rendu direct et la
solution 1, c'est l'application qui dessine les objets triés par
matière et qui paramètre correctement les shaders. Avec cette
solution, il faut le programmer...
pour les curieux : il est possible de
compresser les données pour réduire le temps d'écriture de l'étape
1. les détails se trouvent par exemple dans la dernière presentation
d'Unity.
pour les très curieux : on peut éliminer une bonne partie
des problèmes de volume de données écrit à l'étape 1 en ne stockant
que l'indice du triangle visible pour chaque pixel au lieu de
stocker directement toutes les informations. mais il faudra
recalculer pas mal de choses...
plus d'informations : présentation GDC 2016 Visibility
Buffer + page
de l'auteur W. Engel.
et quelques slides dans la (grosse) présentation
technique de Nanite / unreal engine 5 "A
Deep Dive into Nanite Virtualized Geometry"
Quelle est la meilleure solution ?
Il n'y a pas de bonne réponse, selon la carte graphique, l'api 3d
(openGL / Vulkan, ou Direct3d 11 / Direct3d 12) et la structure de
la scène, et surtout la quantité de calculs réalisée par pixel, le
nombre et le type de source de lumière, la variété des matières /
effets, le nombre de textures, etc. chaque méthode à ses avantages
et inconvénients.
Par exemple, le rendu différé est très populaire depuis la ps3,
puisqu'il permettait de contourner certaines limites / faiblesses
de la carte graphique de la console : dessiner 2 fois la scène
n'était pas une option envisageable. Les studios qui travaillaient
principalement sur la xbox 360 n'appreciaient pas autant la
technique, puisque les textures nécessaires étaient souvent trop
grosses pour être stockées sur la mémoire dédiée de la carte
graphique, ce qui ne posait pas de problème avec la mémoire
unifiée de la ps3...
Exemples plus récents, Unity est en train de ré-écrire son
pipeline de rendu en utilisant un hybride des 2 techniques (cf presentation
très détaillée) et les
équipes d'Unreal constatent un gain plutot interressant avec la
méthode directe pour du rendu stereo en réalite virtuelle (cf blog).
Mais l'interêt de ces deux méthodes est de séparer l'affichage de
la géometrie seule (qui peut etre fait de manière très efficace
avec un peu de travail sur l'organisation mémoire des objets) de
l'étape de calcul des couleurs des pixels / triangles visibles
dans l'image.
Conclusion
Mais la conclusion de toute cette présentation est très simple :
le triangle le plus rapide à dessiner est celui que l'on n'affiche
pas :
- "GPU-Driven
rendering pipelines",
siggraph 2015,
U. Haar, S. Aaltonen, Ubisoft
- "Optimizing
the Graphics Pipeline with Compute",
GDC 2016,
G. Wihlidal, DICE / Frostbite
- "Two pass occlusion culling", (2021 lien mort... pas de
copie...)
la même idée existe depuis plusieurs années, une explication
claire et directe chez s.
hill en 2011 "Practical,
dynamic visibility for games", section 5
et quelques slides sont dispo dans la grosse présentation de
Nanite / unreal engine 5 "A
Deep Dive into Nanite Virtualized Geometry"
Pour maintenir l'efficacité de la fragmentation / rasterization,
il est fortement recommandé :
- d'utiliser un système de LOD : plusieurs niveaux de détails
géométriques par objet, à sélectionner en fonction de la
distance, pour controler la taille moyenne des triangles
dessinés, cf les explications dans la section suivante...
- de dessiner les objets en s'éloignant de la camera pour
maximiser l'efficacité du ztest.
pour les très curieux : il est également
possible de diminuer encore le nombre de fragment shaders
exécutés...
en jouant sur la résolution et les modes MSAA,
cf Checkerbord
rendering / intel, mis au point par sony, cf 4K
checkerboard rendering GDC 2017, G. Wihlidal, DICE /
Frostbite
en choisissant de calculer ou d'interpoler la
couleur d'un pixel, cf Adaptive
undersampling
ou en utilisant une fonctionnalité plus récente
des cartes graphiques : le Variable Rate Shading, ou VRS.
Mais en vrai, c'est pire que ça...
Plus les triangles projettés sont petits (ils occuppent peu de
pixels dans l'image), plus le pipeline graphique est inefficace...
pourquoi ?
Les figures suivantes sont tirées de :
"Evolving
the direct3d pipeline for micro-polygon rendering"
K. Fatahalian, siggraph 2010
Le pipeline graphique doit trouver quels pixels sont couverts par
chaque triangle avant de pouvoir exécuter les fragment shaders. Ce
test est réalisé en parallèle par du materiel spécialisé (l'unité
de fragmentation / rasterizer), sur un groupe de pixels. Pour les
pixels du bloc à l'intérieur du triangle, il faudra exécuter les
fragment shaders :
Les fragment shaders sont toujours exécutés par blocs de 2x2
pixels. Cette organisation permet de calculer les différences
finies de n'importe quelle variable dans un fragment shader, cf dFdx(
) pour les différences sur l'axe X, et dFdy( )
pour l'axe Y. L'utilisation la plus courante de ces fonctions est
le calcul du niveau de mipmap à utiliser pour lire les textures
(en simplifiant, il faut calculer la projection d'un pixel dans la
texture, ou comment varient les coordonnées de textures entre 2
pixels voisins, sur chaque axe... ces calculs sont faits
implicitement par la fonction texture( sampler2d, vec2
texcoords ) )
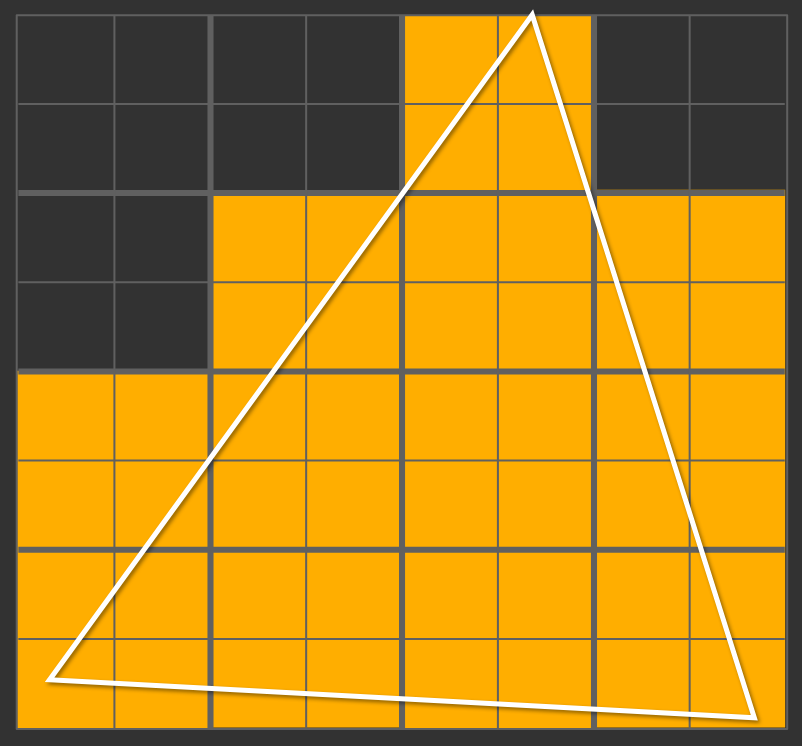
Selon la forme du triangle, 1, 2, 3 ou 4 pixels sont à l'intérieur
du triangle pour chaque bloc 2x2, mais 4 fragment shaders sont
exécutés dans tous les cas, afin de pouvoir évaluer les
différences dFdx et dFdy.
La figure ci-dessus illustre le nombre de blocs 2x2 et de groupes
de 4 fragment shaders exécutés pour un triangle qui remplit la
moitié du bloc de pixels testé par l'unite de fragmentation /
rasterizer. Que se passe-t-il lorsque l'objet est maillé plus
finement et que les triangles sont de plus en plus petits, mais
qu'ils couvrent la même surface / le même nombre de pixels ?
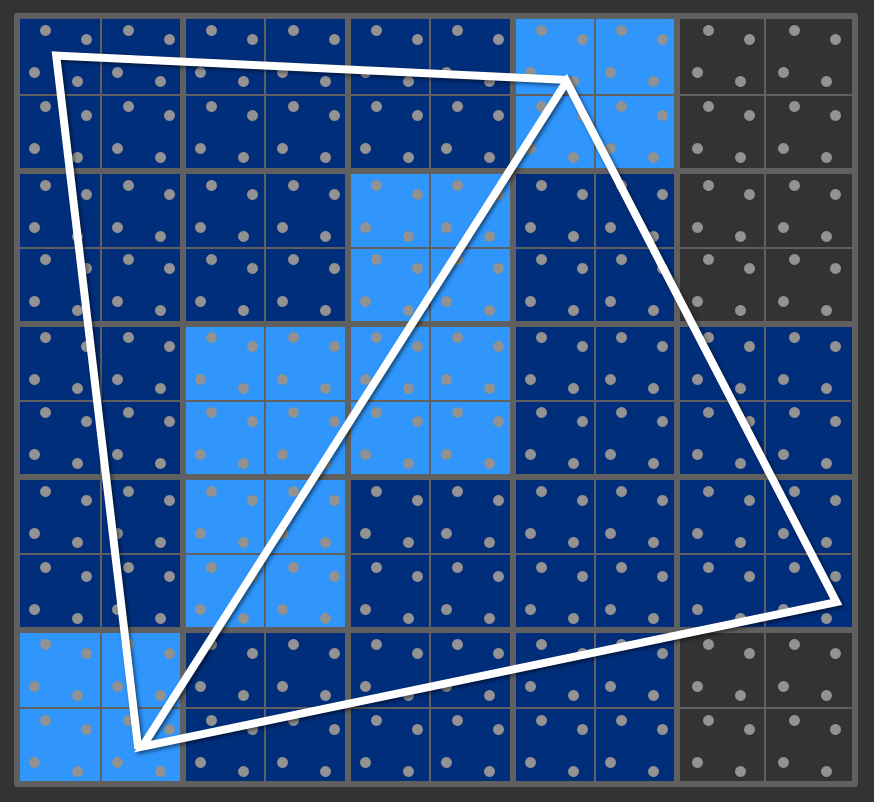

Chaque triangle provoque l'exécution de groupes de 4 shaders sur
les blocs 2x2. Résulat, les shaders des blocs 2x2 le long de
l'arete commune des triangles sont exécutés 2 fois, une fois par
triangle.
Pour des triangles plus petits, la situation dégénère assez vite :
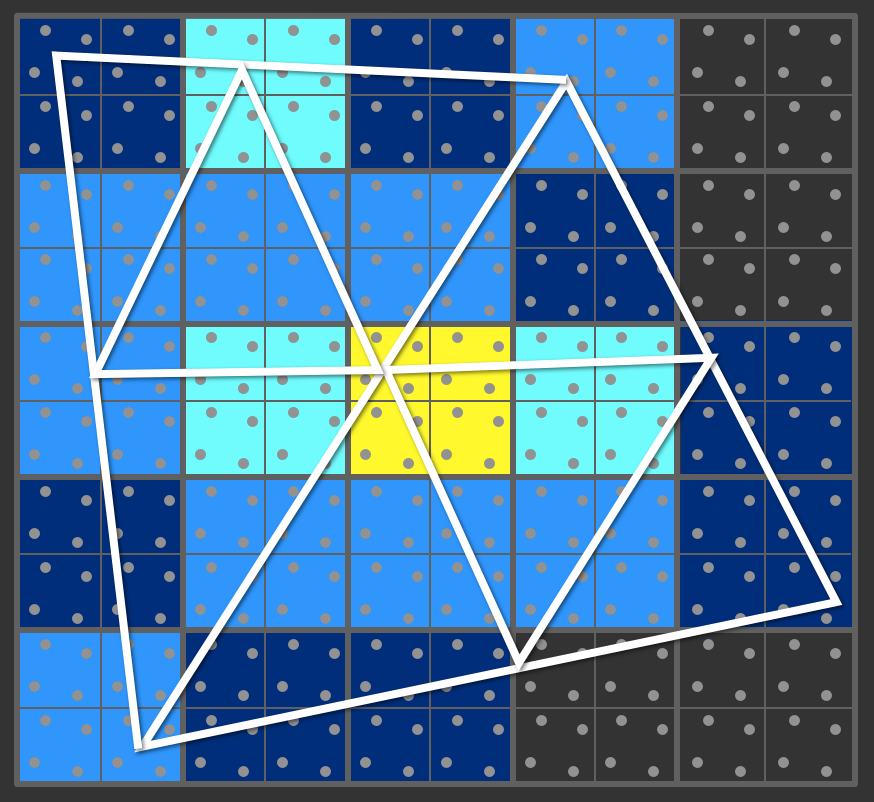
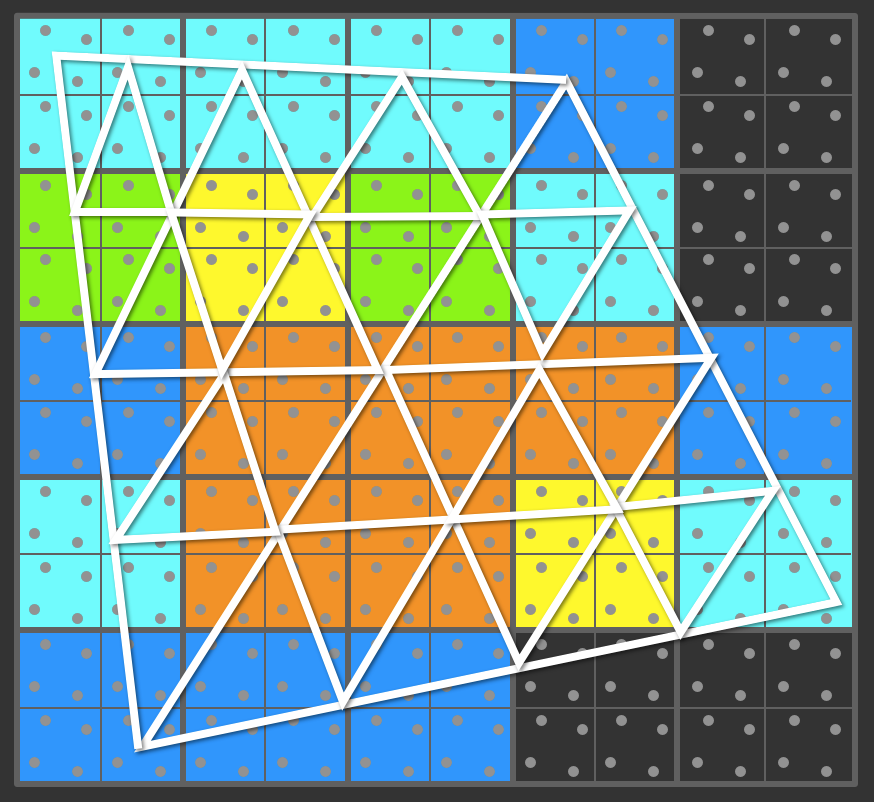
Pour le même nombre total de pixels, chaque triangle est découpé
en bloc, chaque point du bloc est testé, puis chaque bloc 2x2
touchant le triangle exécute 4 fragment shaders, ce qui peut
provoquer l'exécution de nombreux shaders sur un seul pixel (en
fonction du nombre de triangles qui touchent le bloc 2x2)
Sur un objet fermé, ce fonctionnement dégénère assez rapidement
lorsque la taille des triangles diminue et approche 1 pixel
:
 |
 |
 |
| (triangles de 100 pixels) |
(triangles de 10 pixels)
|
(triangles de 1 pixel)
|
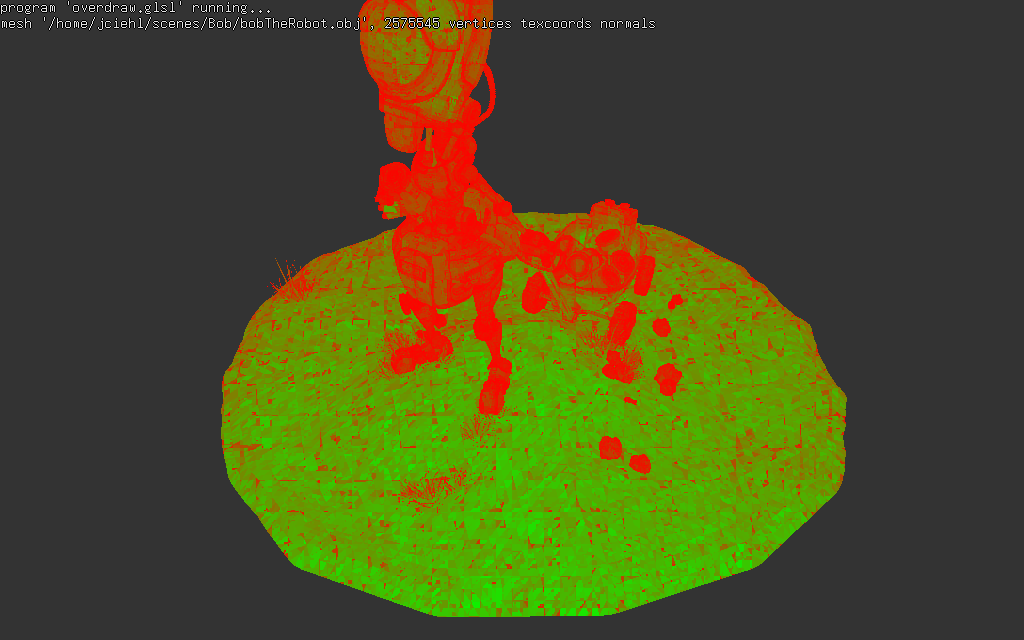
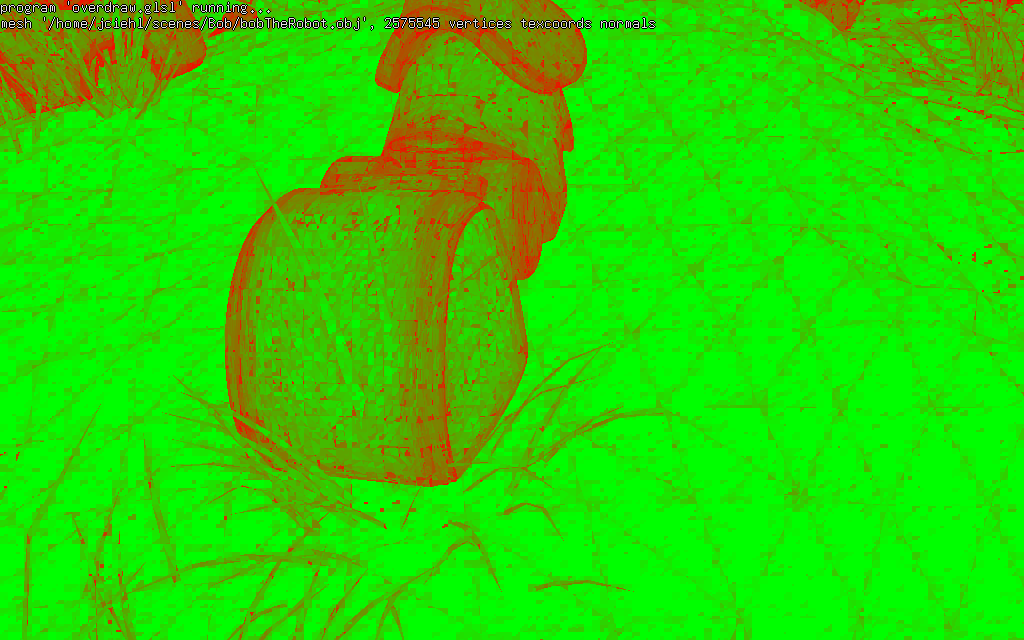
overdraw.glsl permet de visualiser le
rapport fragments "utiles" / fragments "inutiles" dans les blocs 2x2
(sur les triangles visibles...). Dans ce test, un fragment est
considéré utile s'il est à l'intérieur du triangle (indiqué par la
variable gl_HelperInvocation == false), et inutile
lorsqu'il se trouve dans le bloc 2x2, mais à l'extérieur du triangle
(indiqué par la variable gl_HelperInvocation == true).
Les zones vertes sont affichées efficacement, tous les fragment
shaders sont utiles, et les zones rouges sont composées
majoritairement de fragment shaders inutiles :
bin/shader_kit overdraw.glsl objet.obj
Conclusion : il est plutot conseillé d'utiliser plusieurs géométries
plus ou moins détaillées des objets dessinés, afin de controler la
taille des triangles dessinés et d'exploiter correctement l'unité de
fragmentation et d'exécuter le moins de shaders possible.
ou de dessiner les tous petits triangles à la main, avec un compute
shader, comme Nanite dans unreal engine 5, par exemple...
pour les sceptiques : plus de schemas, d'exemples et de tests
sont dispo sur la page de j.
habble