Pour l'instant le lancer de rayon se résume à une double boucle, pas très efficace lorsqu'il y a beaucoup de rayons et beaucoup d'objets :
que peut-on faire pour éviter de calculer la totalité des intersections et réduire la complexité de cette fonction ?
L'idée est assez simple : si un rayon passe loin d'un objet ou d'un groupe d'objets, ce n'est pas la peine de calculer toutes ces intersections... Comment réaliser ce test rapide sur tout le groupe d'objet ? il suffit de choisir une forme simple avec une fonction d'intersection rapide et de l'utiliser pour représenter la région de l'espace occuppée par le groupe d'objet :
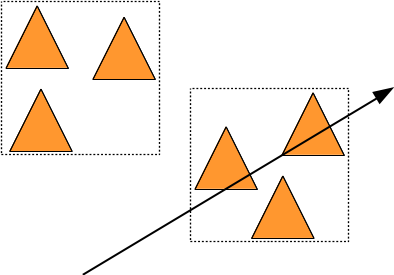
On dit que cette forme simple et rapide à tester est l'englobant du groupe d'objet. Si un rayon ne touche pas l'englobant du groupe, il n'est pas nécessaire de calculer les intersections du rayon avec tous les objets du groupe. Dans cet exemple, on a testé 2 boites et 3 triangles, au lieu de 6 triangles. ce ne sera plus rapide que si tester 2 boites est plus rapide que tester 3 triangles...
Mais bien sur, il faut maintenant construire cet englobant à partir des objets, ou d'une partie des objets. et selon la complexité de chaque étape, l'algorithme complet pourra être plus interessant que la double boucle, ou pas...
Voila l'idée générale, qui repartit les triangles en 2 groupes / englobants si c'est interessant, ou qui utilise la double boucle directe.
le paramètre limite aura une grosse influence sur l'algorithme, en fonction du temps necessaire pour couper un englobant en 2, repartir les objets dans les 2 englobants et tester quels rayons touchent chaque englobant.
on peut illustrer les différentes étapes de l'algorithme, en utilisant un cube aligné sur les axes comme englobant :
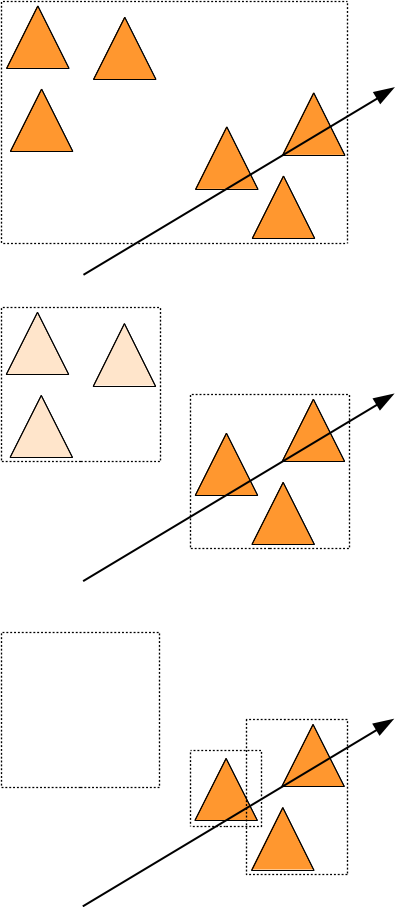
Répartition
Il y a encore quelques détails à régler avant d'écrire la solution complète : si on découpe un englobant en 2 parties, il peut très bien arriver qu'un triangle touche les 2 parties, il faudra donc inclure le triangle dans les 2 ensembles de triangles testés par la suite de l'algorithme. ce qui veut dire allouer de la mémoire à chaque appel récursif pour représenter l'ensemble { t }... et ça va être très long.
On peut faire le contraire : choisir pour chaque triangle dans quel englobant le mettre et calculer ensuite la taille des englobants (en fonction des triangles qui leur sont associés). De cette manière chaque triangle n'apparait que dans un seul ensemble { t } et il n'est plus nécessaire de réallouer de la mémoire. On peut même faire mieux : on peut décider que les triangles du premier ensemble seront au début du tableau de triangles et que les autres sont placés après. si tous les triangles sont dans un tableau T, après la répartition, on peut repérer chaque ensemble de triangles { t } par un indice de début et un indice de fin.
tout ça pour dire que le tableau de triangles va se trier au fur et à mesure des appels récursifs de repartition( ) et qu'il suffit de passer les indices debut/fin de chaque partie en paramètre.
En pratique, une solution de répartition qui fonctionne bien utilise une boite alignée sur les axes comme englobant. Pour découper l'englobant en 2 régions, il suffit de trouver quel axe de l'englobant est le plus long, et de le couper en 2, au milieu. Ensuite, il suffit de tester un point de chaque triangle pour décider de l'associer à la region 1 ou 2, selon sa position par rapport au plan qui coupe l'englobant par le milieu.
Quel point choisir pour répartir un triangle dans l'ensemble T1 ou T2 ? Si l'on regarde le fonctionnement de l'algorithme, les objets sont répartis en utilisant leur boite englobante. Et le centre de la boite englobante est probablement la meilleure solution.
Dernier détail pratique, comment écrire la répartition des triangles ?
en fait, c'est un algorithme classique disponible dans la librairie standard c++ : std::partition() l'idée est de tester chaque élément d'un tableau et de décider s'il doit etre placé au début ou à la fin du tableau, en fonction du résultat du test. Tous les éléments pour lesquels le test est vrai sont placés au début du tableau, et ceux pour lesquels le test est faux sont placés à la suite, à la fin du tableau. Et la fonction std::partition() renvoie l'indice du premier élément de la 2ieme partie du tableau. Il ne reste plus qu'à écrire le test. On utilise une structure qui définit operator() ( ... ) const, qui renvoie un bool. cette fonction de test des éléments s'appelle un prédicat :
Les ensembles de triangles et des rayons sont répresentés par des tableaux et les indices de début et fin. L'intersection directe de tous les rayons avec tous les triangles peut s'ecrire facilement :
On a maintenant tous les éléments pour écrire l'algorithme de répartition. Pour manipuler facilement les englobants, on peut utiliser :
Et voila l'algo principal :
il manque les prédicats qui testent les rayons et les triangles :
et
remarque : oui, bien sur on peut aussi utiliser des lambdas c++ pour écrire les prédicats, c'est la même chose. par exemple :
et alors ?
est-ce que tout ca est interessant ?? pour la cornell box, qui ne comporte que 32 triangles, c'est un peu mieux :
direct()90msdivide()80ms
et pour un objet plus gros, par exemple data/bigguy.obj, 3000 triangles :
direct()12400msdivide()170ms
ca commence à etre mieux... petite remarque sur la complexite de l'algorithme de répartition, il y a presque 10 fois plus de triangles dans bigguy, mais le temps d'intersection n'est que ~2 fois plus important... pas mal.
code complet dans tuto_englobant.cpp
Par contre, il y a un petit inconvénient pour utiliser cet algorithme pour calculer une image, il faut construire le tableau de rayons pour l'utiliser et il serait plus simple et plus pratique de pouvoir tester rapidement un seul rayon à la fois. Un autre problème est lié au fait que les triangles sont re-triés à chaque fois : pour tous les rayons partant de la camera, puis les ombres (visibilité des sources de lumières), pour les reflets, etc... Dernier point embétant, il n'est pas facile de le paralléliser...
pour les curieux : cette méthode est décrite plus en détail :
- "Naive-Ray-Tracing: A divide-and-conquer approach", B. Mora, 11
- "Efficient Divide-And-Conquer Ray Tracing using Ray Sampling", K. Nabata, K. Iwasaki, Y. Dobashi, T. Nishita, 2013
BVH : arbre d'englobants
Le principal inconvénient de la solution précedente est que l'on re-trie plusieurs fois les triangles, pour chaque ensemble de rayons nécessaire au calcul de l'image (et construire l'ensemble de rayons à tester n'est pas toujours simple).
construction
Mais il n'est pas très compliqué de stocker les englobants construits par l'algorithme de répartition dans un arbre. Puis de parcourir cet arbre pour chaque rayon... Voici les englobants construits par l'algorithme de répartition, ainsi que les noeuds et l'arbre associé :
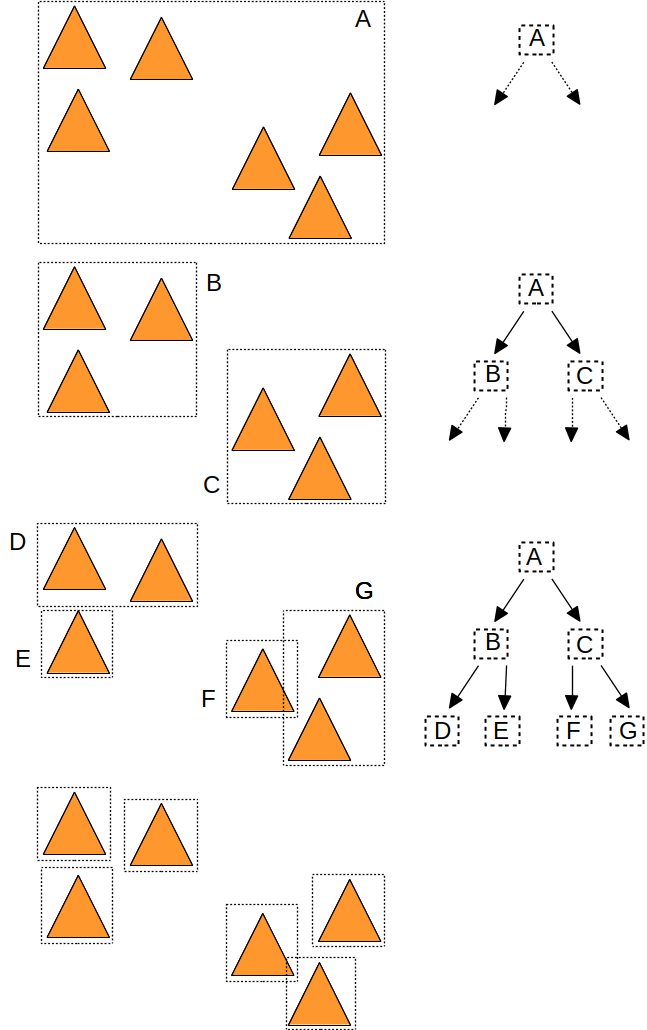
il suffit de modifier l'algorithme de répartition de la section précédente :
l'appel à la fonction direct() correspond à la création d'une feuille, et les appels à repartition() correspondent à la création des fils des noeuds internes. On n'a plus besoin des rayons, on veut simplement construire tous les groupes d'objets et leurs englobants :
et l'algorithme renvoie le noeud racine de l'arbre. Ce type d'arbre s'appelle un BVH, pour Bounding Volume Hierarchy.
Ces deux algorithmes suivent le meme principe et à la fin les objets sont triés dans l'ordre des feuilles qui les référencent.
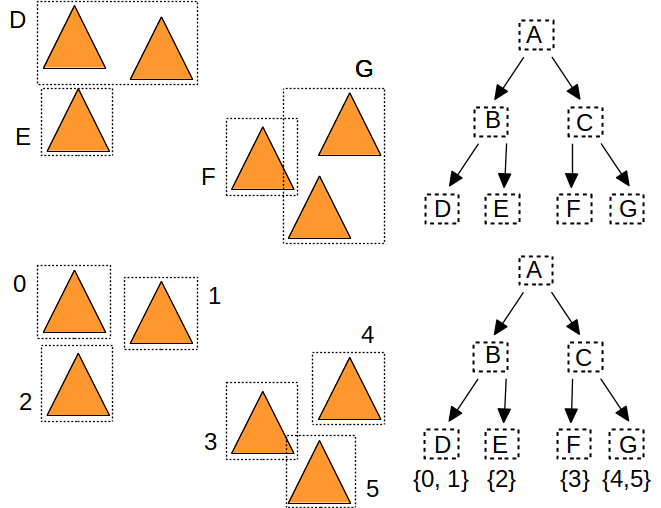
Bien sur, il reste quelques détails à régler : comment représenter les noeuds, les feuilles, les objets, etc. Le plus simple est d'utiliser la meme structure pour représenter les noeuds internes et les feuilles de l'arbre. Une autre simplification consiste à utiliser un tableau de noeuds, et à utiliser des indices pour désigner le fils gauche et le fils droit. Avec cette convention, on obtient cette représentation de noeud :
- noeud : un englobant, l'indice de son fils gauche, l'indice de son fils droit,
- feuille : un englobant, l'indice du premier objet dans le tableau trié des objets, et l'indice du dernier objet, ce sont les memes parametres que l'appel à
direct()dans l'algorithme de répartition.
L'arbre est représenté par un tableau de noeud / feuille et le tableau des objets triés par la construction, ainsi que l'indice de la racine :
on aurait également pu utiliser des entiers supplémentaires dans les feuilles (premier et dernier par exemple) pour stocker l'indice du premier et du dernier objet, mais il suffit de pouvoir faire la différence entre un noeud (interne) et une feuille. Du coup, on peut utiliser des valeurs négatives pour stocker les indices des objets et des valeurs positives pour stocker les indices des fils. Pour rendre le reste du code plus lisible, il suffit de cacher ces détails dans la structure Node :
La construction de l'arbre est sans surprise, elle utilise la meme fonction de répartition std::partition(), et renvoie l'indice du noeud ou de la feuille crée :
et voila !! c'est exactement la meme stratégie que tout à l'heure, mais bien sur, il faut conserver les englobants, les groupes d'objet et construire l'arbre en plus.
parcours
Maintenant que l'arbre est construit, il faut l'utiliser pour calculer les intersections d'un rayon et des objets. La encore, le principe est le meme que tout à l'heure, dans la fonction de répartition. Si le rayon touche l'englobant d'un noeud, il faut aussi vérifier s'il touche les englobants des fils du noeud. L'intersection avec les objets ne se fait qu'au niveau des feuilles.
ce qui s'écrit directement :
et alors ca marche ??

pour la cornell box, 32 triangles :
direct()90msdivide()80ms- bvh construction < 1ms, construction + intersection 85ms

pour un objet plus gros, par exemple data/bigguy.obj, 3000 triangles :
direct()12400msdivide()170ms- bvh construction < 1ms, construction + intersection 150ms

plus gros, sibenik : 75000 triangles
direct()abandon...divide()710ms- bvh construction 19ms, construction + intersection 910ms

sponza version crytek : 250000 triangles
direct()pas la peine...divide()2470ms- bvh construction 80ms, construction + intersection 4000ms

musee : 1500000 triangles
direct()pas la peine...divide()2800ms- bvh construction 480ms, construction + intersection 4000ms
bien sur, on peut maintenant paralleliser l'intersection des rayons (avec openMP, par exemple) :
sur 6 coeurs / 12 threads : le temps de construction du bvh ne change pas, par contre voici les temps d'intersection :
- sibenik : intersection 120ms (au lieu de 900ms)
- sponza version crytek : intersection 450ms (au lieu de 4000ms )
- musée : intersection 310ms (au lieu de 3700ms )
c'est mieux, la construction du bvh et son parcours / intersection parallelisé sont toujours plus rapides que divide() et le bvh sera plus simple à utiliser pour calculer une image.
pour les curieux : la version en ligne de PBRT (un livre de référence sur le lancer rayons et les calculs réalistes) propose également d'utiliser des BVH. 3 méthodes de construction sont présentées, ainsi que l'optimisation de la représentation mémoire de l'arbre et un parcours ordonné plus efficace que celui présenté ici.
paralléliser le calcul de l'image
pour paralléliser le calcul de l'image, il suffit de se rendre compte que le calcul d'un pixel est indépendant des autres pixels, et qu'il suffit de paralleliser la boucle sur les lignes de l'image :
peut mieux faire...
il est possible de construire des arbres de meilleure qualité qui sont encore plus rapide à parcourir (>2 fois !!), mais ce sera pour le cours de M2...